Overview of scheduler features
Introduction
This article describes the features of the scheduler component.
Features of scheduler
One-stop-shop for job related queries
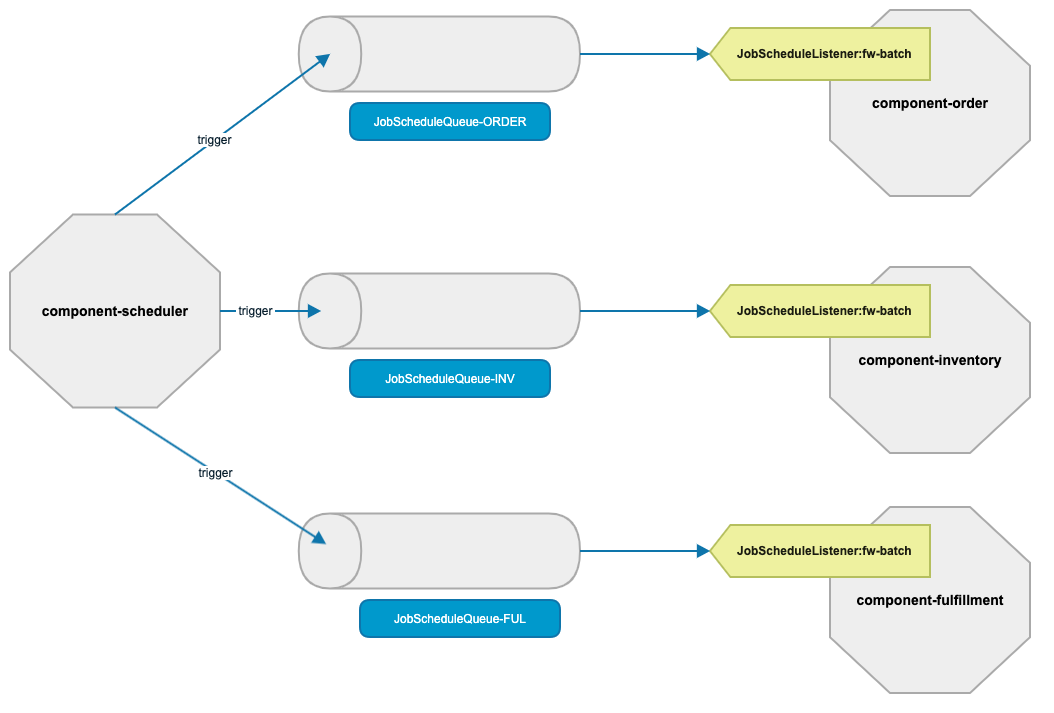
The component-scheduler is the central repository for all job schedules spread across components. scheduler takes care of posting a message to the component specific JobScheduleQueue when a job has to be triggered. The batch framework still holds the responsibility of executing the job, only the scheduling part is delegated to scheduler. As scheduler maintains the schedules and triggers them for all components, we have a better control and visibility of the schedules and their next triggers. To manage this, two new entities have been introduced to store the future runs for a configurable time window (next 4 hours by default) and already triggered jobs.
This is how scheduler triggers jobs for all the components -
High-availability
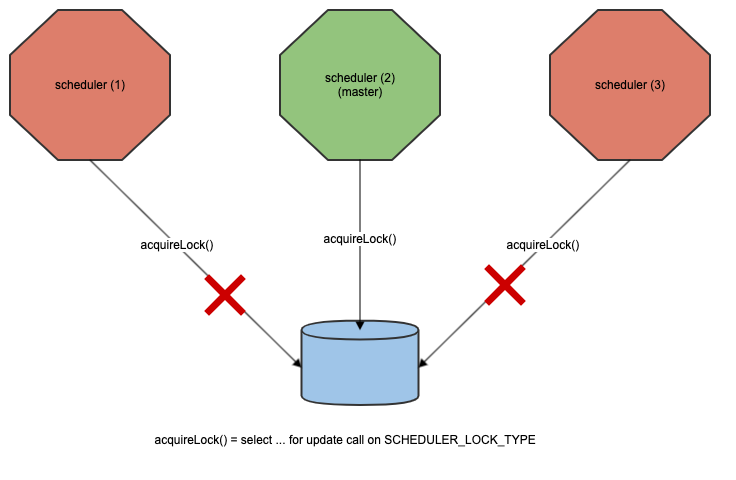
Even if the master instance of component-scheduler goes down, any other instance can elect itself as a master and continue the job triggers seamlessly. Even if none of the master instances are available at a given point of time, there will be no job triggers for the time it is down and when it is brought up, the pending schedules will be triggered as we have stored them in the DB. So, there is no chance of missing a trigger. At most, it can be delayed a few minutes in case of the component being down.
Scheduler master instance election -
Scheduler internal housekeeping jobs
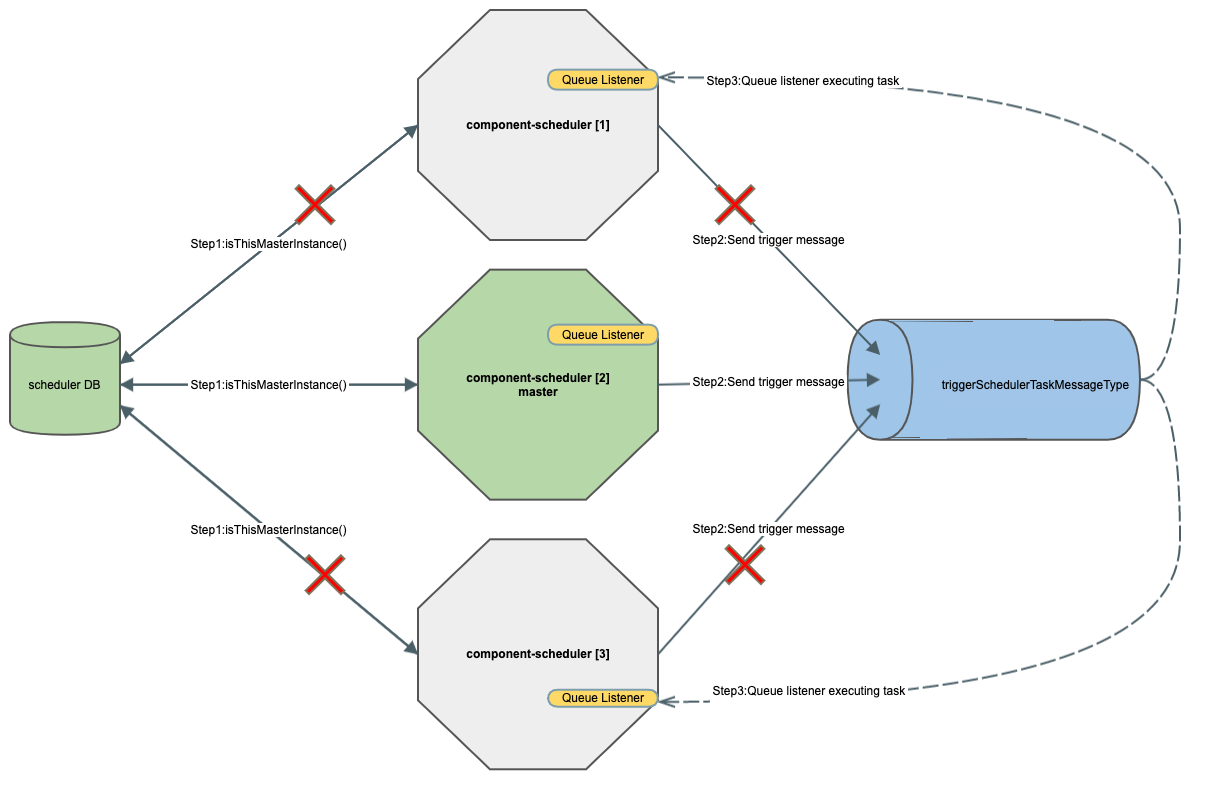
Scheduler component maintains a few internal jobs that help in maintaining and triggering the job schedules for all the components.
Polling data from components: Runs at 00:00 UTC every day to poll the JobSchedule and JobTypeDefinition from all the components. Even though there is a separate process to relay the updates on JobSchedule and JobTypeDefinition on the fly. This job helps in syncing any delta that could have been missed during the relay.
Create Future Data: Runs at the 10th minute of every hour and creates the future execution backlog for the next 4 hours.
Purge Job Executions: Runs every 6 hrs to purge the JobExecution records which are older than 5 days.
Status monitoring for components: Every component can have some jobs configured that need status monitoring. Scheduler triggers a status monitoring for all the inprogress jobs for a component every 1 minute. Once a job execution has been marked as completed, no further status monitoring would happen.
Abort jobs: If a job execution has not been completed even after the MaxRunDuration has elapsed, the corresponding JobExecution record will be marked as aborted. This job runs every 15 minutes
This is how scheduler invokes the internal housekeeping jobs -
Useful API endpoints
Full initialize: This API endpoint will fetch the JobTypeDefinition, JobSchedule and required OutboundMessageTypes for all “managed” components, given as a comma separated list to component-scheduler and for all organizations and persist them in the component-scheduler DB.
POST : {url}/scheduler/api/scheduler/setup/fullinitialize
Initialize for an Org: This is a lighter version of the full initialize API endpoint and does the initialization for a particular Organization across all managed components.
POST : {url}/scheduler/api/scheduler/setup/orgId/{orgId}
Initialize for an Org and a component: This is an even lighter version of the full initialize API endpoint and does the initialization for a particular Organization for the input component.
POST : {url}/scheduler/api/scheduler/setup/orgId/{orgId}/component/{component}
Please note: this API endpoint is expecting the component short name, not the full component name. For example, if you are trying to use this API endpoint for component-order and organization org1, then you would do so by passing “order” as the component name.
Create future jobs: This API endpoint creates the future job execution records based on the cron expression of the jobSchedule and persists them in the SCH_FUTURE_JOB_EXECUTION table. The offset value should be provided as an integer in minutes.
POST : {url}/scheduler/api/scheduler/setup/createfuturejobs/{offset}
The future calculation will start from currenttime+offset. The offset value essentially signifies the time buffer we keep before recreating the futureJobs. While recreating the futureJobs, if the schedule is supposed to trigger, we might have issues because the same futureJob entry could be getting updated or deleted. The immediate futureJob entries (which fall within the offset period) will remain intact to avoid conflict issues as explained above.
Get the master lock status: As per the Active/Active design, only one of the running scheduler instances will hold the ActiveMasterLock and this instance (master instance) will be responsible for triggering the jobs. The below API endpoint can be used to gather information about the current lock status.
GET : {url}/scheduler/api/scheduler/schedulerLockStatus
View already triggered jobs: The following API endpoint can be used to search for the JobExecution records, where scheduler stores the already triggered executions.
POST : {url}/scheduler/api/scheduler/jobExecution/search
{
"Query": "JobScheduleId='<JobSchduleId>'"
}
Any of the fields can be used for searching the job execution records. This sample takes the JobScheduleId as input.
View upcoming job triggers: The following API endpoint can be used to search for the FutureJobExecution records, where scheduler stores the upcoming triggers for the next 4 hours.
POST : {url}/scheduler/api/scheduler/futureJobExecution/search
{
"Query": "JobScheduleId='<JobSchduleId>'"
}
Any of the fields can be used for searching the job execution records. This sample takes the JobScheduleId as input.
Authors
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
Feedback
Was this page helpful?