Overview of batch job configuration
This article describes the concepts of JobTypeDefinition and JobSchedule entities and explains the importance of key fields in these entities that will help you configure the batch jobs for a ActivePlatform™ microservice.
Entity details
Batch framework has the following entities. The below diagram just captures the Key fields for each entity to depict their relationship. The latter section explains each field in detail.
Please note that the one-to-many relationships shown in the diagram are figurative in nature. There is no database level constraint, it is more of a data relation between the entities.
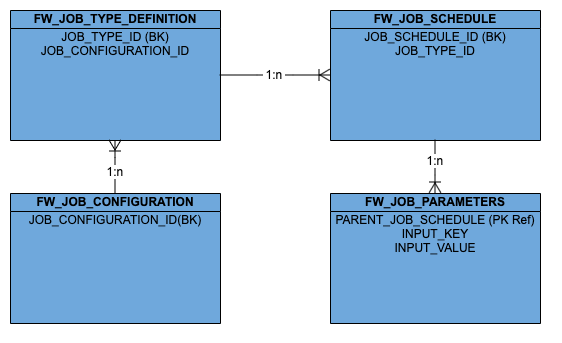
JobTypeDefinition: This entity defines what and the how part of a job. The entity to store the different types of jobs for which schedules can be created. For. e.g “Re-tag Fulfillment”, “Cancel aged orders” etc. Each component is supposed to provide a finite set of such configurable jobs. New job types can be configured as this is a service level entity.
JobSchedule: This entity defines the when part of the job, basically the execution cadence based on the cron expression. It is tied to a particular jobType and there could be multiple schedules created for a job type. This is a service level entity and schedules can be created / updated as required.
JobParameters: This entity is the direct child of JobSchedule entity and is used to provide input parameters for the job as a key-value pair
JobConfiguration: This entity pertains to only batchv2 jobs and defines the how part of the job.
Fields of JobTypeDefinition
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobTypeId | Unique identifier for a particular job type. This serves as the business key for the entity along with the profileId. JobTypeDefinition is a config type entity belonging to batch profile purpose. For a spring-batch job, the JobConfiguration java file should contain a @Job bean with the same name | N.A. | Some name that explains the business purpose of the JobTypeDefinition. |
| JobTypeDescription | Brief description about the type of job. | N.A. | Describe the business purpose of the jobTypeDefinition in clear words. |
| ChunkSize | Chunk size for the particular job. This is applicable for spring-batch jobs and for JpaPagingItemReader type readers. The default QueryReaderBase, provided as part of BatchFramework makes use of this type of reader. Essentially what does it mean? There is a concept of ChunkSize and PageSize in spring-batch. If there is a lot of data to be read and written (to queues in our case), the read and write can happen in multiple threads and pages. The reader threads read as many number of records in one shot as the configured PageSize. The writer threads receive a List of items to be written to the queue, the List size is based on the ChunkSize. For simplicity, BatchFramework has assumed PageSize=ChunkSize for all processing. This document here has more details about the chunk oriented processing : https://docs.spring.io/spring-batch/trunk/reference/html/configureStep.html#chunkOrientedProcessing | null | N.A. The chunksize should be very carefully set based on the volume consideration for this job. If you expect few thousands of records or more to be read during one particular execution, it is better to set the ChunkSize to a higher value (may be in thousands). If you set it too less, the entire dataset will be logically broken into a large number of pages and as many DB hits will be fired to load the data. This can lead to a situation where all the eligible records are not picked up during an execution if the job updates the same column on which the reader query is built (part of the where clause). As the reader and writer can execute concurrently in separate threads, some of the eligible records can be updated while the read is still in progress. This will impact the total count and the page offsets calculated earlier. You can try adding an “oder by” clause on a field that doesn’t change on the update (like the created_timestamp) |
| StatusMonitorLevel | This field enables status monitoring for your job. Status monitoring implies keeping track of the progress of the job execution and marking the status to OPEN (read start), INPROGRESS (write complete) and COMPLETED (all messages processed). Basically status monitoring should be enabled for only those jobs where you want to take some action after the job execution has been completed and you have defined a callback handler. For all other jobs, setting status monitoring to true may cause un-necessary load on the system. This field supports these values : CHUNK, MESSAGE, NONE. CHUNK : Used to do status monitoring per chunk when t he data was stored at chunk level. Now this implies that status monitoring is enabled. MESSAGE : Not used any more. NONE : This implies that status monitoring is disabled for this job. POINT TO NOTE This feature is supported only when functional jobs have StatusMonitoringJobexecutionListenerBase as JobExecutionListener (for reference Agent Job configuration class | null | NONE Unless you business usecase needs to know the completion status of the job execution and you take some business decision/make some changes (like you have configured a CallBackHandler) based on the outcome of the job execution, it is better to disable the status monitoring by setting it to ‘NONE’. Please note : Leaving it to NULL would imply the value is defaulted to ‘NONE’ in the code. |
| JobType | This field defines different types of jobs. Supported values are SYSTEM, FUNCTIONAL, SERVICE, AGENT SYSTEM : Reserved for framework jobs and should not be used by components. FUNCTIONAL : For functional spring-batch type jobs. This is the default value that is assumed by BatchFramework if this field is not set. SERVICE : For functional service type jobs. Needs to be set explicitly for jobs that just invoke a ServiceDefinition on trigger. AGENT : Agent jobs. Mostly used by services teams to configure jobs where they need to execute the logic in their extension components. | null | N.A. Should be decided based on the Job. If left to the default value of NULL, the system would assume it is a spring-batch job (FUNCTIONAL). |
| JobStatusCallbackHandlerBean | This is the bean that will be invoked once the job execution has been completed. This bean should implement this interface : JobStatusCallbackHandler. If you want to configure a JobStatusCallbackHandlerBean for your job, it is mandatory to enable status monitoring for your job type. | null | N.A. Unless you have set the status monitoring levels accordingly for your job and you have some business logic to perform once the job execution completes. |
| InvocationServiceId | This maps to a ServiceDefinition entry in the system. Once the job trigger time comes, that particular ServiceDefinition will be invoked with all the jobParameters set in the schedule (refer to the section below) as input to the service method. This is tightly coupled with the field JobType (value = SERVICE) and is applicable only for service type jobs and has no bearing on the spring-batch jobs. | null | null Unless you have a SERVICE type job and you have the corresponding ServiceDefinition entry defined in the system |
| CreateContextFromJobParams | Flag to denote whether the context needs to be created from job parameters. By default, during the job execution, the context will be renewed to the context with which the JobSchedule was created. But in case, there is a need to override the context and execute the job in a custom context created from the JobParameters, this flag should be set to true. Location, Organization, User, and Business Unit can be overridden by the JobParameters. | false | false Unless you have a requirement to override the context with which the JobSchedule was created and you want to renew the context based on the JobParameters when the job executes |
| IsHeelToToe | Flag to denote whether it is a heel-to-toe job. A heel-to-toe job would only have one schedule of the job executing at any instance of time. Default false implies multiple simultaneous executions of the job is allowed. | false | false Unless you business usecase requires your job to be of heel-to-toe nature. |
| DropToMessageType | Unique identifier for the outbound messageType where the writer will send the messages. | null | If the DropToMessageType is not specified , the outbound message type will be considered as JobTypeId. |
| JobConfigurationId | Unique identifier for the job configuration. Required only for batch v2 jobs. | null | null Unless you are configuring a batchv2 type job. The Job configuration id mandatory for any batchv2 job to start. |
| MaxRunDuration | Expected time duration for one execution of the job. Jobs will be auto aborted post that. Should be given like ‘30 MIN’, ‘1 HOUR’ etc | null | null Unless you want to abort the job after a specific period of time if it still doesn’t complete naturally |
| IncludedOrganization | Comma separated list of organizations for which the JobSchedule will be included for execution. A jobSchedule will execute for all the organization which are sharing the same profileId for which the jobSchedule has been configured. Out of all those organizations, if you wish to execute the job for a particular few, this property needs to be configured | null | null Unless you wish to restrict the job execution only for certain organizations, even if there are many organizations which share the same profile |
| ExcludedOrganizations | Comma separated list of organizations for which the JobSchedule will be excluded for execution. A jobSchedule will execute for all the organization which are sharing the same profileId for which the jobSchedule has been configured. Out of all those organizations, if you wish to avoid execution of the job for a particular few, this property needs to be configured | null | null Unless you wish to avoid the job execution only for certain organizations, out of all the organizations which share the same profile |
| IsSyncExecution | Flag to denote if the job execution happens synchronously. Defaulted to false denoting async execution. Once the job trigger message arrives in the JobSchedule queue, the execution is handed over to a separate thread by default. As the trigger message is ACKed in the queue, the message is dequeued. In case the job execution fails due to some reason, we have to wait for the next trigger to happen to resume the execution. If you wish to keep the job trigger message alive in the queue till the time the job execution ends, you need to set this property TRUE | false | false Unless it is a very low frequency and important job that needs to resume immediately if the container processing the job goes down. |
Fields of JobSchedule
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobScheduleId | Unique identifier for a particular job schedule. This serves as the business key for the entity along with the profileId. JobSchedule is a config type entity belonging to batch profile purpose. | N.A. | Some name that explains the business purpose of the JobSchedule. |
| JobTypeId | Identifier of the job type to which this schedule is tied to. This field maps to a JobTypeDefinition (jobTypeId column). There is no DB relationship between these two tables, JobSchedule and JobTypeDefinition are linked through data only. | N.A. | Should be the JobTypeId of the JobTypeDefinition for which the JobSchedule has been created |
| CronExpression | String to represent the cron expression for the job schedule. Please refer to https://freeformatter.com for creating your cron. This field is used to build the cron trigger | null | Some cron based on the business need that defines the execution cadence for the particular job schedule. |
| IsDisabled | Flag to denote whether the job schedule is disabled(paused) for the time being. Default value is false, i.e enabled. Is there is a need to stop a schedule from executing for some time and you do not want to delete it yet, this flag can be set to true. This will temporarily disable a schedule until it is enabled back by setting this flag to false | false | false Unless you want to disable a schedule |
| IsAdhoc | Flag to denote whether the job schedule is a dummy schedule created for adhoc jobs. The schedule will be deleted after the execution has been completed. This flag is used entirely for internal purposes and to support ad-hoc jobs (one time execution jobs that can run with any given parameter provided as input). | false | false |
| TimeZone | Timezone in which schedule needs to be executed/triggered. UTC is considered by default. POINT TO NOTE There is a specific format that BatchFramework (and component-scheduler) supports for the timezone input. Please refer to this page for the supported values : https://en.wikipedia.org/wiki/List_of_tz_database_time_zones | null | null Unless there is a business need to run your job at a particular timezone. Most of the repeated jobs should not worry about timezones as they would run at specific intervals. Default NULL implies UTC. |
Fields of JobParameters
This table is the direct child of JobSchedule entity and is used to provide input parameters for the job as a key-value pair
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| InputKey | JobParameters are key-value pairs which are given as input during the job execution. This field is the key field of the pair. | null | N.A. |
| InputValue | JobParameters are key-value pairs which are given as input during the job execution. This field is the value field of the pair. | null | N.A. |
Fields of JobConfiguration
This table is a way of configuring the jobs through DB entities. This configuration pertains to only batchV2 type of jobs.
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobConfigurationId | Unique identifier for the job configuration. Serves as business key | N.A. | Some name that explains the business purpose of the batchV2-JobConfiguration. |
| DataListSize | Used by the work distributors to break the data in batches. Each batch is a List of documents. Each batch will be processed independently by the business logic | 1 | 1 Unless you want to group multiple individual entities together to process them as a batch. Your service should be able to handle multiple entities together if you set a higher value |
| DataFormat | This attribute works in conjunction with DataListSize and will be only applicable when DataListSize=1. If DataListSize=1 and the data needs to be published as a LIST then make the DataFormat=LIST | singleton | singleton Unless you want to group multiple individual entities together. |
| PageMessageType | Intermediate message type used by readers or workdistributors to break the paged data into chunks. The listener will process each page independently. | batchv2ProcessSegment | batchv2ProcessSegment Unless you wish to route your segment messages to a separate intermediate queue. If not specified otherwise, all BatchV2 jobs configured for a component, will share the same batchv2ProcessSegment queue. |
Authors
- Subhajit Maiti: Director, ActivePlatform™, R&D.
Feedback
Was this page helpful?