High Availability and Scalability
Introduction
ActivePlatform™ utilizes the power and flexibility of Kubernetes to ensure high availability of compute resources, services, and application components while allowing for horizontal scaling of synchronous and asynchronous workload processors to meet volume requirements. ActivePlatform™ is built on the principles of redundancy and concurrency, making it adaptable to inevitable compute failures, resource starvation, and application faults.
Maintaining Availability & Uptime
ActivePlatform™ is built with a 3-dimensional fault-tolerance design to maintain high availability and uptime of the deployed applications:
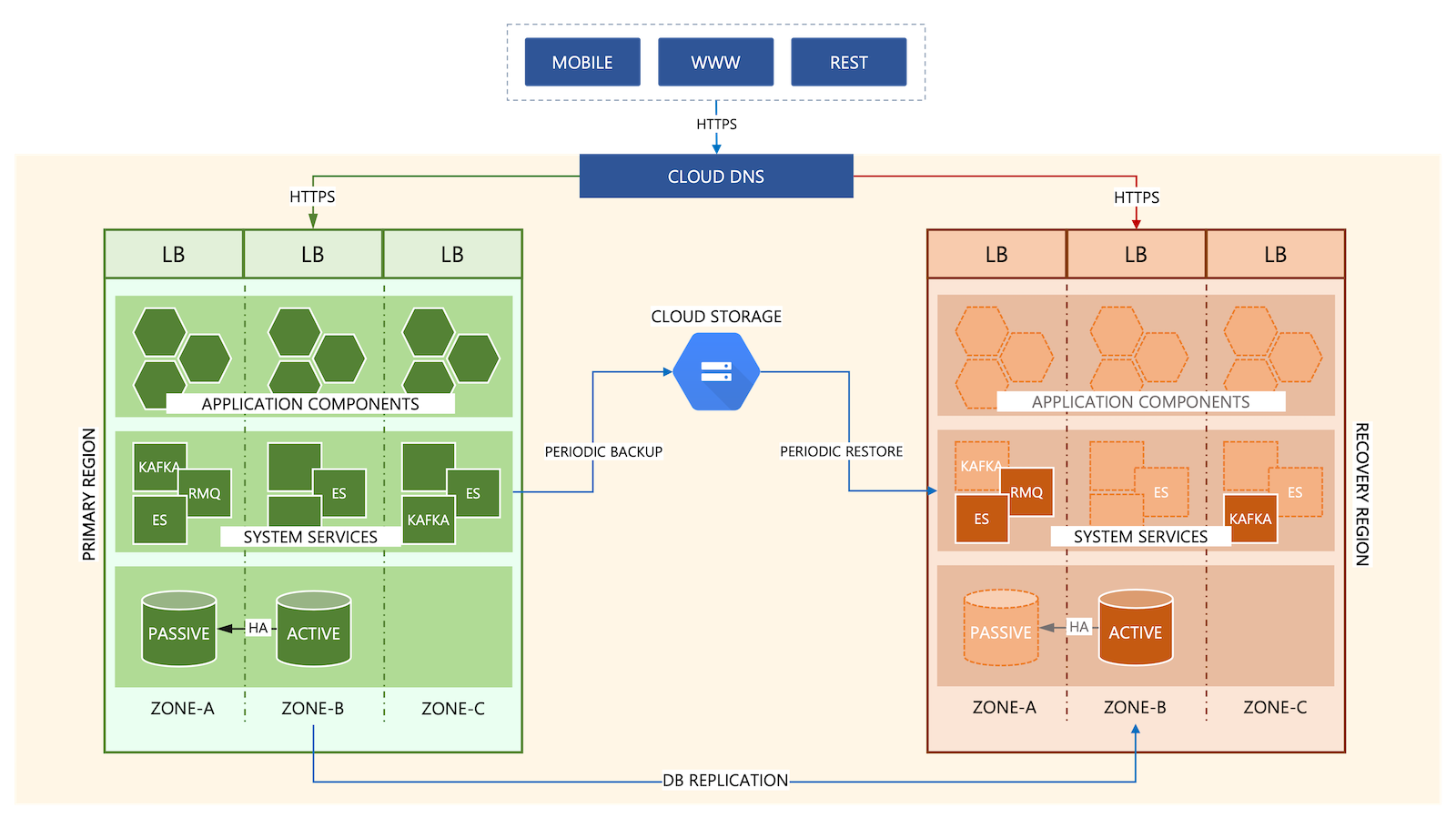
- Availability of Persistence: Database instance maintaining the transactional data is deployed as 2-instances in an active-passive HA topology, spread across two availability zones. In case of unavailability of the primary database instance, the connection automatically and transparently switches over to the secondary database instance. Likewise, other persistent services are deployed as 2+ node cluster with independent persistent volumes across availability zones.
- Availability of Compute: The Kubernetes cluster that hosts ActivePlatform™ runtime is deployed in multiple availability zones within a geographical region. Redundancy of compute resources and network across availability zones allows for contingency in case of potential failures or unavailability of one of the zones in the region.
- Availability of the Application: The Kubernetes
DeploymentandStatefulSetthat run the application components and system services are deployed (and auto-scale) as multiple replicas. This allows for contingency in case of potential failures or unavailability of one of the replicas of the application components or services. Moreover, system and application updates are applied using a “rolling” strategy to ensure zero downtime upgrades.
All customer environments are deployed using a standard deployment framework that follows a consistent deployment topology, with variations based on the environment designation:
- Production: regional deployments (3 zones), with database HA.
- VPT: regional deployments (3 zones), without database HA.
- Staging and Development: zonal deployments (1 zone), without database HA.
Disaster Recovery
A regional deployment of ActivePlatform™ stack on multiple availability-zone helps with high availability and fault-tolerance to protect against partial or full unavailability of a zone. However, a regional deployment does not protect when an entire compute region suffers a loss due to a significant outage in that region. To ensure business continuity during such events, Manhattan offers an optional disaster recovery deployment of ActivePlatform™ on a remote compute region located geographically away from the primary region.
When the disaster recovery option is selected, Manhattan commits to well-defined recovery objectives as part of the service level agreement of the customer contract:
- The Recovery Point Objective (RPO) is the age of files that must be recovered from backup storage for normal operations to resume if a computer, system, or network goes down because of a hardware, program, or communications failure. ActivePlatform™ DR Option commits to an RPO of less than or equal to 1 hour
- The Recovery Time Objective (RTO) is the targeted duration of time and a service level within which a business process must be restored after a disaster (or disruption) to avoid unacceptable consequences associated with a break in business continuity. ActivePlatform™ DR option commits to an RTO of less than or equal to 4 hours
The ActivePlatform™ disaster recovery deployment is an instance identical to the primary instance. The DR instance is deployed with minimal workload necessary to act as the “warm” data backup of the primary instance. Business data is replicated or synchronized to achieve the committed RPO and RTO agreements. In the event of a disaster, ActivePlatform™ Operations will the standard operating summarized described below:
- Bring up the remainder of the application components and persistent services to activate the disaster recovery instance as the primary instance.
- Rewire the application endpoints via the Cloud DNS so that the application URLs in use by the customer remain unchanged.
- Work with customers following standard service interruption protocols. The Customer Status page will be updated to reflect the DR event.
The ActivePlatform™ disaster recovery deployment is enabled for customers purchasing the option. The deployment is tested and audited by a certified 3rd party semi-annually as part of Manhattan’s SOC 2 compliance programs. Contact Manhattan Sales or Professional Services for more information about implementing Disaster Recovery.
The illustration below summarizes the regional (primary instance with multiple availability zones) and multi-regional (additional disaster recovery instance) deployments of ActivePlatform™:
Scalability
Having the ability to increase compute capacity elastically proportional to the increasing traffic and volume is essential to maximizing the throughput and performance of software deployment. Conversely, the ability to shrink compute capacity when the volume of business workload shrinks is also key to reducing the overallocation of compute resources, costs, and the carbon footprint of the deployment. Scalability is an integral part of the core architecture of ActivePlatform™, enabling optimal throughput while minimizing the total cost of ownership for Manhattan and the customers.
Container Auto-scaling
ActivePlatform™ relies on concurrency and disposability of its microservices architecture and the power of Kubernetes to enable horizontal scaling of the deployments. Horizontal scalability allows ActivePlatform™ to minimize application downtime and scale the application seamlessly, while continuously adjusting the size of the deployment to handle the spikes and drops in workloads.
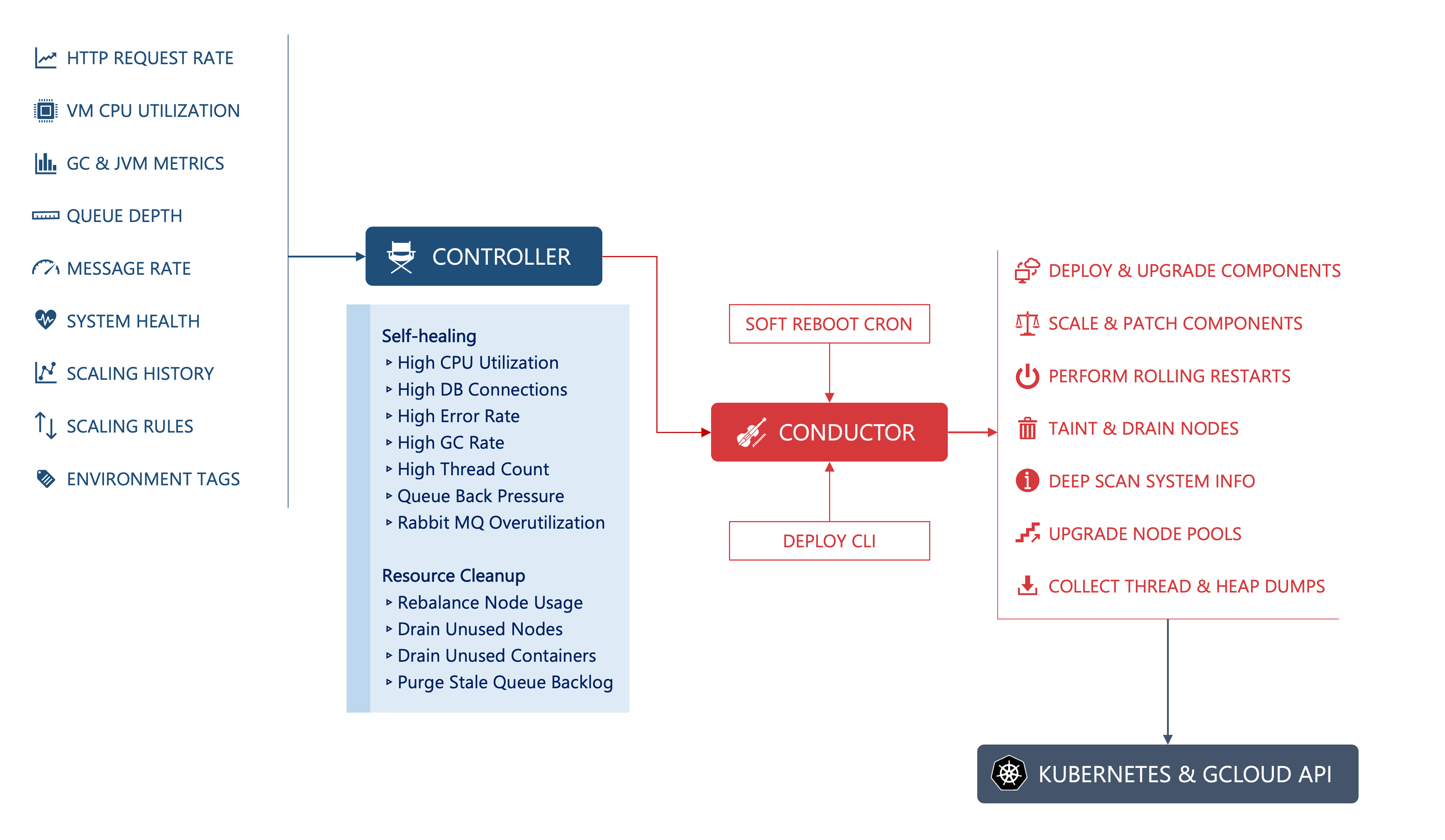
ActivePlatform™ consists of an auto-scaling engine at the core of its architecture. The engine comprises two key components:
- Controller is the “brain” behind the auto-scaling; it continuously monitors various system metrics such as incoming traffic, processing rate, queue depths, average volume served by a specific business function, and the CPU utilization across the Kubernetes cluster. By evaluating these metrics, Controller computes the need for scaling and issues commands to Conductor to perform the scaling operation.
- Conductor is the “brawn” behind the auto-scaling; it receives commands from Controller and performs the scaling operations. Conductor manages the
DeploymentandStatefulSetof the Kubernetes cluster and invokes the Kubernetes API to update the scaling parameters of the underlying deployments. Conductor additionally performs maintenance functions such as node taints, workload movements, container reboots, and rolling updates to help with scaling and cleanup.
Horizontal scaling performed by the auto-scaling engine can be classified into two categories:
- Responsive, or Reactive scaling: Scaling performed as a response to the increasing or decreasing size of the business workload based on the real-time computations performed by Controller. Responsive scaling is important for the application to cope with bursts and slumps in the incoming volume or throughput requirements.
- Managed, or Proactive scaling: In certain cases, larger resource availability may be necessary to be in place ahead of time when there are predictable increases in incoming volume or throughput requirements. The prediction may be predictive, scheduled, or preemptive:
- Predictive scaling: The auto-scaling engine determines the future scaling needs based on the historical trend of the throughput requirements
- Scheduled scaling: A recurring definition of the scaling needs that are placed ahead of time based on prior experience
- Rules-based scaling: A decision maker defining the scaling rules ahead of time, which results in scaling commands being executed before the burst or drop in volume
Compute Auto-scaling
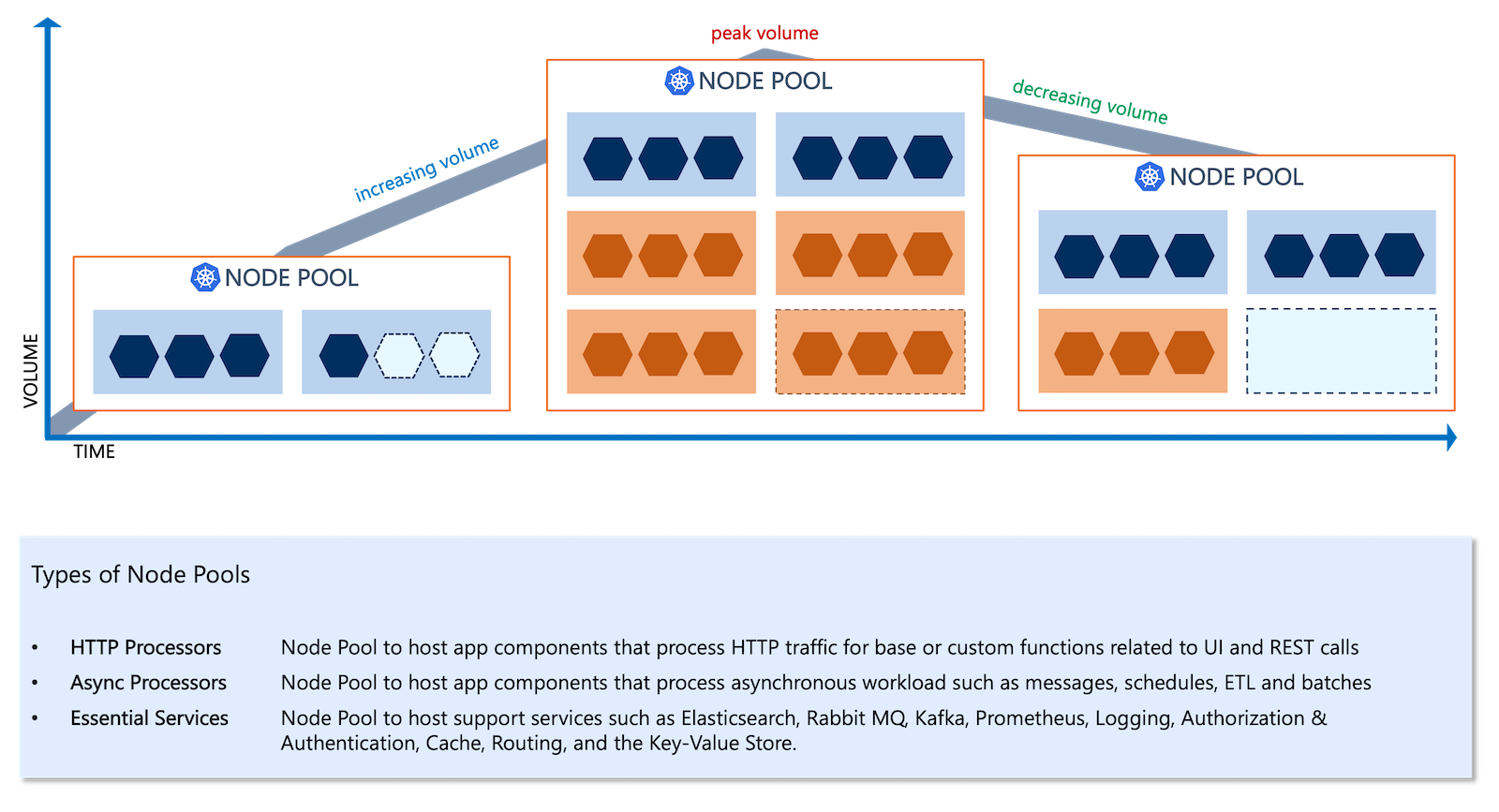
Conductor performs updates of the desired replica counts on the target Deployment or StatefulSet, effectively updating the number of running container Pods. When the CPU or memory requirements to run these Pods go beyond the currently available compute capacity, Kubernetes issues commands to deploy additional virtual machine nodes to the node pool. Likewise, when the CPU or memory requirements shrink, Kubernetes will accordingly adjust the node pool sizes by freeing up surplus compute capacity.
Compute scaling based on the capacity requirements is managed by Kubernetes based on configured values of minimum, desired, and maximum node counts of the underlying node pools that allocate the virtual machines (or “nodes”). As illustrated below, the node pools scale up and down proportionately to the volume trend. With increasing volumes, the node pools will add new nodes while draining the nodes when the volume decreases.
Learn More
Author
- Kartik Pandya: Vice President, ActivePlatform™, R&D.
Feedback
Was this page helpful?