Data Stream
Introduction
Data Stream is a sub-system of ActivePlatform™ that is responsible for replicating data from the production MySQL database to a configurable set of target data stores. Production data is replicated by reading the MySQL binary logs and is synced with the target (near) in real time. Data Stream is built using open-source microservices and a framework developed by Manhattan called Gravina.
Change Data Capture, or CDC, is a well-established software design pattern for a system that monitors and captures the changes in data so that other software can respond to those changes. CDC captures row-level changes to database tables and passes corresponding change events to a CDC stream. Applications can read these change event streams and access these change events in the order in which they occurred. change data capture helps to bridge traditional data stores and new cloud-native event-driven architectures.
Gravina Overview
Gravina is an internal system and framework library built by Manhattan that reads the source MySQL binary log, converts each event into a message in a CDC capturing mechanism (Kafka), and relays them to the target system in a format the target system can interpret.
Customers can implement Data Stream to replicate production data to a set of supported target systems, which, as of the writing of this document, include the following:
- Google Cloud SQL
- Certain other MySQL implementations (but not all)
ActivePlatform™ engineering team continues to build support for additional replication targets based on product management and customer requirements.
Gravina Architecture
Following is the summary of the Gravina microservices that enable the Data Stream functionality:
Extractor
Gravina Extractor is a Spring Boot microservice that embeds Shyiko mysql-binlog-connector-java and integrates with Apache Kafka. Extractor reads binary logs from the source MySQL database, converts each event into a message, and publishes them to Kafka. The extraction process executes as a single-threaded background job.
Kafka
Apache Kafka plays the role of CDC capture system in Gravina architecture. It is used to stream events from the Extractor into the target consumer, which is one of the supported Gravina replicator microservices. The messages in Kafka are partitioned by database entity groups into separate Kafka topics so that they can be consumed concurrently by the replicators.
Replicator
Gravina Replicator is a Spring Boot microservice that subscribes to the Kafka topics mentioned above to read the CDC events. These events are then converted to a payload format suitable for the target system. Each replicator implementation is specific to the target it serves (for example, replicator implementations for Google Cloud Pub/Sub targets and a MySQL replica on a customer’s Google Cloud SQL endpoint). As shown in the diagram above, to increase throughput, multiple instances of the replicator can be run to process CDC events from Kafka topics in parallel. Likewise, multiple types of Gravina replicators can also coexist in the same environment to transmit the replication events to different types of target systems concurrently.
Supported Replication Modes
While Gravina can technically replicate the data stream to a wide range of target stores, currently Manhattan supports the following replication modes as generally available options:
Data Save with Google Cloud SQL
Production data is replicated to a Google Cloud SQL instance owned and managed by Manhattan. The customer has private access to the database instance and a read-only authorization to query and report from this database. Manhattan remains responsible for operating, monitoring, and maintaining the database instance.
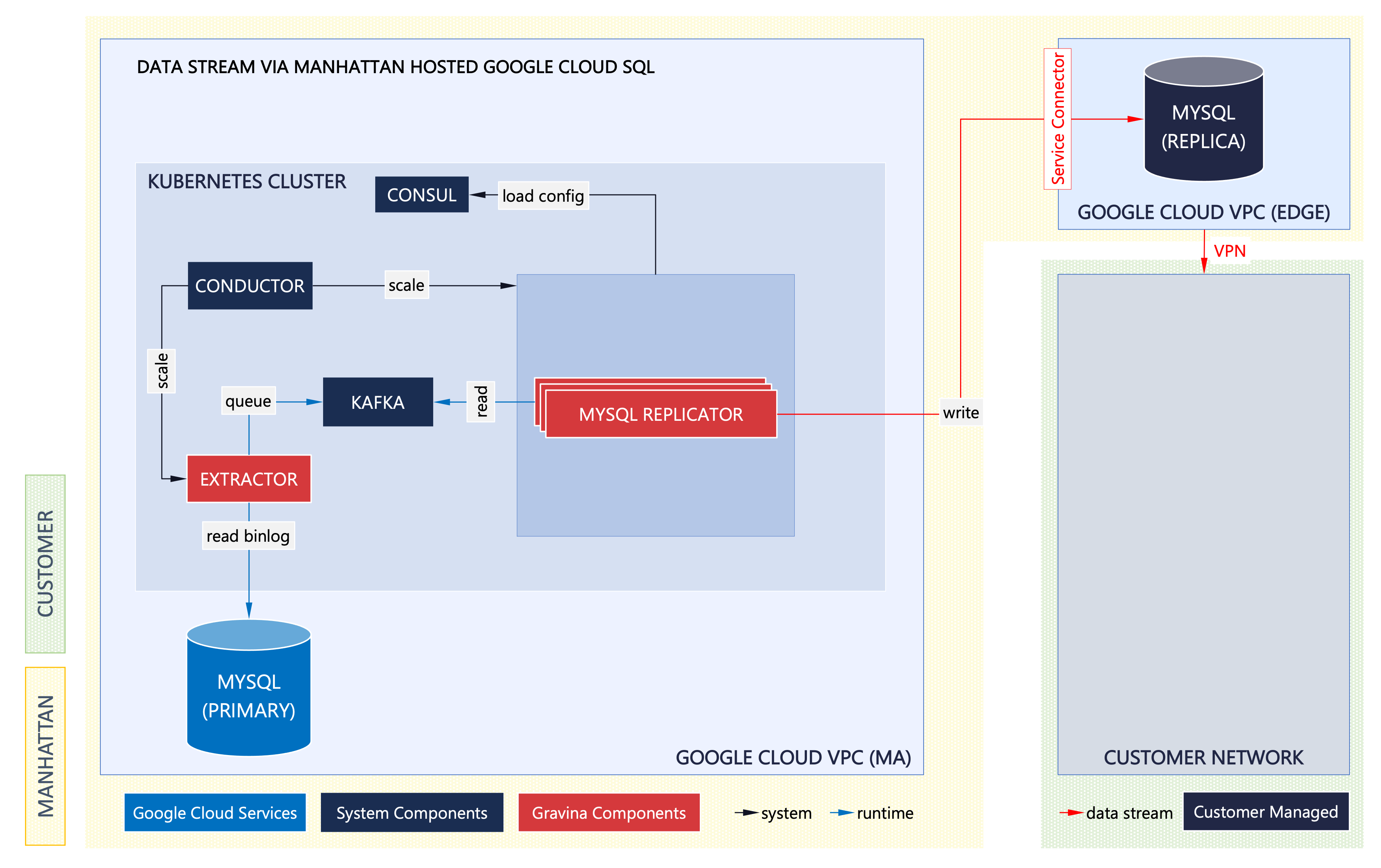
Data Stream with Google Cloud SQL
Production data is replicated to a Google Cloud SQL instance owned and managed by the customer. Manhattan will need authorization and network access to write the replication events to this database instance. The customer remains responsible for operating, monitoring, and maintaining the database instance.
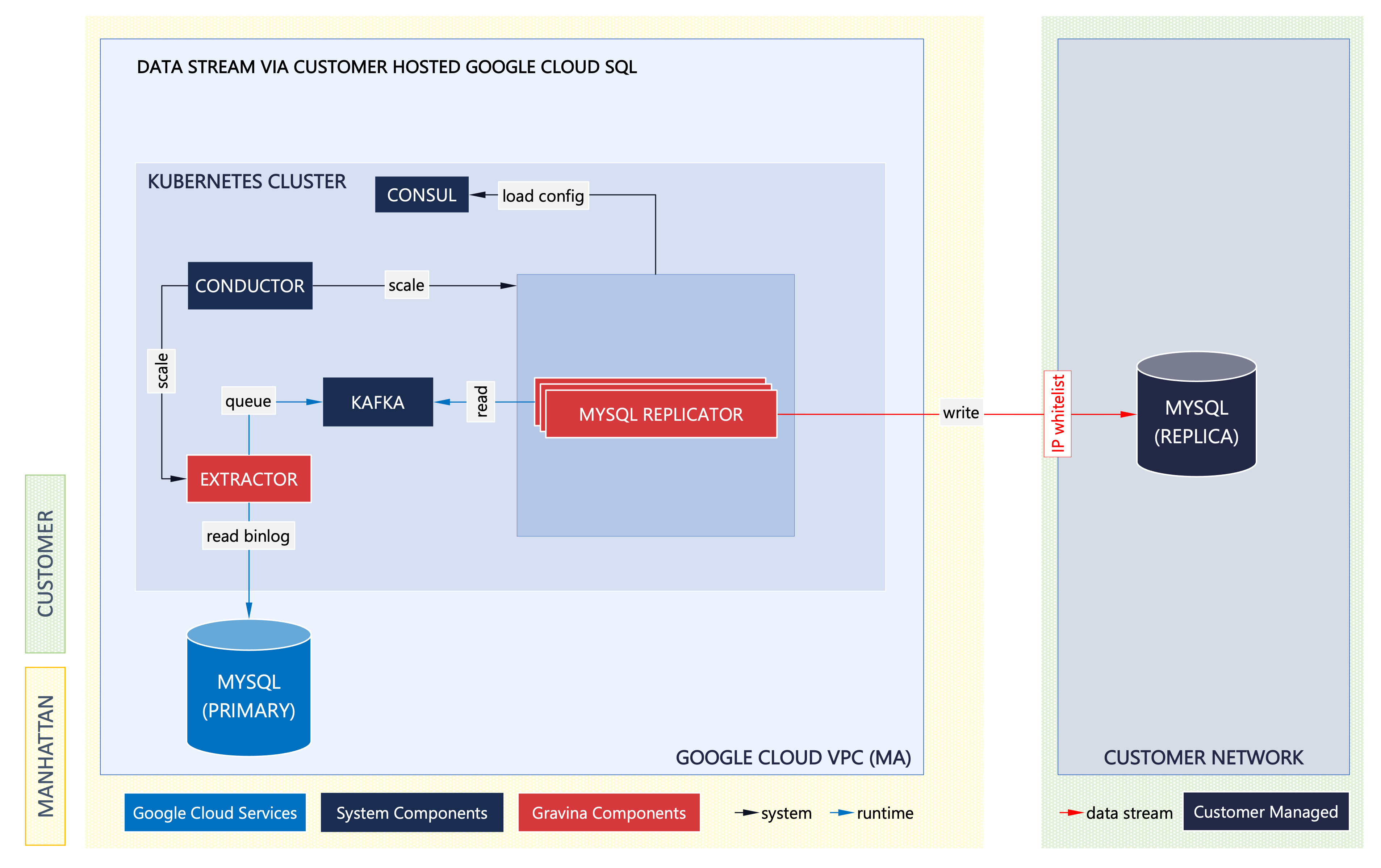
Learn More
Author
- Kartik Pandya: Vice President, ActivePlatform™, R&D.
Feedback
Was this page helpful?