Asynchronous Workload Processing
Introduction
The Asynchronous Workload Processing Framework (or “AWPF” for short) is a framework instrumented in every microservice that runs as part of the ActivePlatform™. AWPF enables extensibility, messaging, and batch execution within the business flows, and provides an abstract way to handle asynchronous communication between the microservices, or to- and from- the microservices and external systems. There is also a mechanism for helping components implement a basic “pipeline” – a data-defined sequence of states and corresponding services. This document covers the concepts of extension points and handlers, message types (inbound and outbound), service definitions, intermediate queues and payloads.
AWPF Features
- Simple configuration: Abstract out the configuration of queues through simple database entities
- Multi broker support: Ability to connect to multiple message brokers like - RabbitMQ, Kafka, Google Pub/Sub, Amazon SQS
- Connection and security: Manage the connectivity and security for asynchronous communication
- Failed message handling: handle retries for the failed messages and capabilities to replay the failed messages with or without data correction
- Zero message loss: Ensure zero message loss through multiple message persistence techniques
- Consolidation and De-deduplication: Ability to consolidate similar messages together and de-duplicate messages
- Scheduled delivery: Ability to schedule the delivery of a message at a particular point of time. Send now, get it delivered later
- Conditional messaging: Ability to send or suppress a message based on a MVEL condition, evaluated against the message content
- Transformation: Ability to transform message contents through freemarker and velocity templates
- Metrics and dashboards: Provide visibility through runtime metrics and intuitive dashboards
AWPF Message Types
AWPF simplifies queue configuration for every microservice that defines one or more queues. From a microservice’s perspective, it can either send a message to a queue, or receive a message from a queue. Or in the asynchronous messaging speak, a microservice can either produce a message or consume it. A microservice defines the queues it sends messages to through the OutboundMessageType configuration. Similarly, it defines the queues it receives the messages from through the InboundMessageType configuration. OutboundMessageType and InboundMessageType are defined via configuration entities in the database. Other connection details such as the messaging service (i.e., the “broker”), host names, port and credentials are abstracted from the microservice code and are configured in the database.
At a high level, the message flow between microservices or via the external system integration can be described as the following:
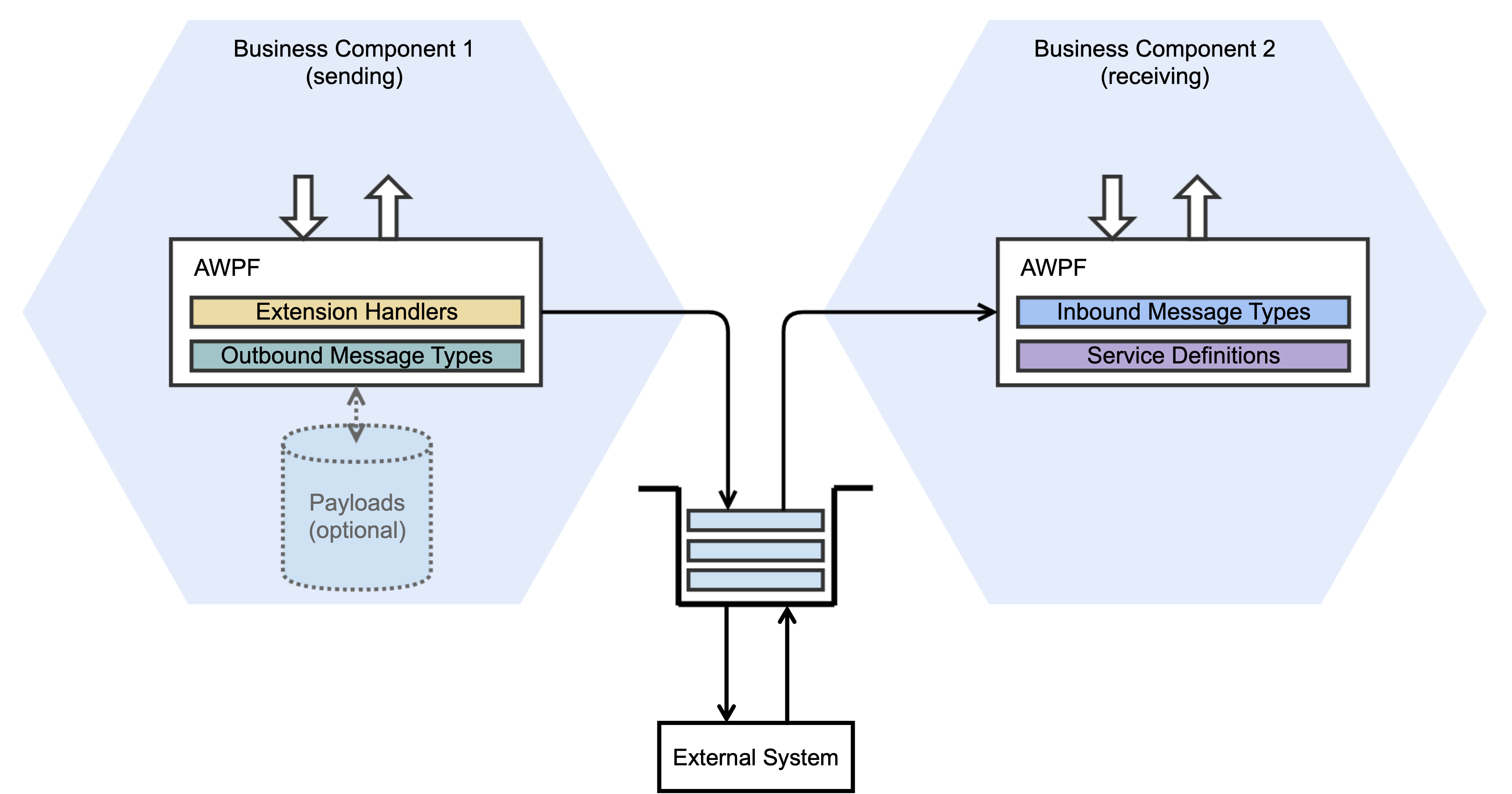
There are different ways a message type is mapped to an actual queue:
- The queue name directly maps to the message type name. This is the most commonly used pattern.
- Inbound and Outbound message types support defining a specific queue name if it is different from the message type name
- The queue name may carry a system property placeholder in it, which is evaluated by AWPF and replaces the placeholder to the configured property value at runtime
- A queue can also be defined with an absolute queue name by marking it is
fullyQualified.
For more detailed reference, see AWPF Message Types
Batch framework and Scheduler
Microservices may need to execute batch jobs for processing data in bulk. A batch job defines two properties: (1) what should the job do, and (2) when to execute the job. The Batch Framework enables these capabilities via configuration that a microservice can leverage to define the jobs and the execution cadence.
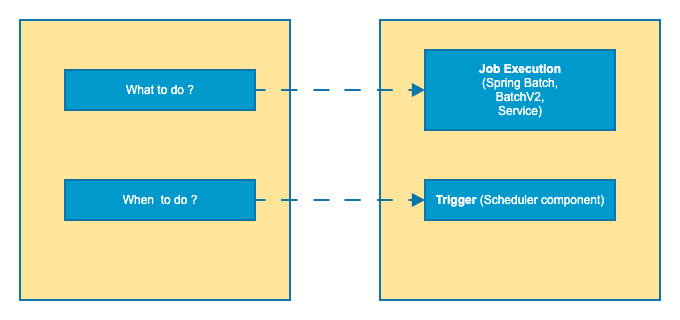
Batch framework features
- Simple configuration: Abstraction of complex details of a job via simple configuration mechanism
- Multiple varieties of jobs: Batch framework supports different types of jobs such as Spring-batch jobs, Service jobs, BatchV2 jobs and Agent jobs.
- Status monitoring and completion callback: When a batch job executes asynchronously, this feature helps the user visualize the progress of the job execution by tracking the messages produced by the execution. Once a job is complete, the user can receive a callback with the the execution status through the callback handler.
- Facility/BU level jobs: While the job configuration entities are defined at an organization-profile level, there is provision to configure Node/BU level jobs through job parameters.
- Heel-to-toe executions: If you want your next job execution to commence only when the previous execution goes to a completion, you can use the heel-to-toe property for a job.
- Timezone support: You can configure you job to run in a particular timezone. By default, all jobs execute in UTC timezone.
- Ad hoc job trigger: A job does not need to always be scheduled. A job can be executed without defining a recurring schedule for it by using the ad hoc job trigger.
- On-demand trigger: If there is a need to trigger an other scheduled recurring job out of turn, the on demand trigger can be used to to trigger the job, without disrupting the regular cadence of the job.
Refer to this page for the job configuration details
Scheduler features
- One-stop-shop for job related queries: Scheduler maintains a copy of all job configurations across microservices. It also maintains a record of upcoming and past executions. The Scheduler microservice provides user interface and API to collect this information.
- High availability: Scheduler ensures high availability by electing one of the
RESTstereotype instances as the primary. If the primary instance is unavailable for any reason, another instance automatically elects itself as the primary and continues triggering the jobs. - Useful REST endpoints: Scheduler provides a REST API to initialize the jobs, create future execution backlogs, etc.
- Internal housekeeping jobs: Scheduler has a few internal housekeeping jobs to help it manage the job triggers more effectively.
Refer to this page for details about scheduler component
Learn More
Authors
- Subhajit Maiti: Director, ActivePlatform™, R&D.
Feedback
Was this page helpful?