This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Overview
- 1.1: Technology Overview
- 2: Getting Started
- 3: Accessing from Manhattan Active® Solutions
- 4: How To
- 4.1: Call Manhattan Active® API
- 4.1.1: Authenticate to Manhattan Active® API
- 4.1.2: Call Manhattan Active® API from your code
- 4.1.3: Call Manhattan Active® API using Postman
- 4.1.4: Manhattan Active® API Reference
- 4.2: Configure login modes
- 4.3: Configure Data Stream for Google PubSub
- 4.4: Configure OAuth Clients
- 4.4.1: Access Management 1.0
- 4.4.2: Access Management 2.0
- 4.5: Configure Identity Providers
- 4.5.1: IDP Initiated Login with Okta and AccessManagement 2.0 via SAML 2.0
- 4.5.2: Configure Azure Entra ID SAML 2.0 IdP for JIT & Non JIT
- 4.5.3: Configure Okta SAML 2.0 IdP for JIT
- 4.5.4: Configure Okta OIDC IdP for JIT
- 4.5.5: Configure Azure Identity Providers
- 4.6: Clearing IDP Assocations for Users with Access Management 2.0 API
- 4.7: Handling IDP Key Rotation in AM 2.0
- 5: Concepts
- 5.1: High Availability and Scalability
- 5.2: Manhattan Active® Platform Security
- 5.3: Auditability
- 5.4: Extensibility & Configurability
- 5.5: Enterprise Integration - Async vs Sync
- 5.6: Asynchronous Workload Processing
- 5.7: Data Stream
- 6: Reference
- 6.1: Manhattan Active® Apps
- 6.1.1: Manhattan Active® Omni
- 6.1.1.1: Alternate Payments
- 6.1.1.1.1: Afterpay
- 6.1.1.1.2: Amazon Pay
- 6.1.1.1.3: Klarna
- 6.1.1.1.4: PayPal
- 6.1.1.2: Address Verification
- 6.1.1.2.1: Avalara
- 6.1.1.2.2: Canada Post AVS
- 6.1.1.2.3: Experian QAS
- 6.1.1.2.4: Loqate
- 6.1.1.2.5: Strikeiron
- 6.1.1.2.6: UPS
- 6.1.1.3: Credit Card Payments
- 6.1.1.3.1: Alliance (ADS)
- 6.1.1.3.2: Adyen
- 6.1.1.3.3: Arvato
- 6.1.1.3.4: Aurus
- 6.1.1.3.5: Chase
- 6.1.1.3.6: CyberSource
- 6.1.1.3.7: First Data
- 6.1.1.3.8: Fiserv
- 6.1.1.3.9: Mercado Pago
- 6.1.1.3.10: Webpay
- 6.1.1.4: Customer Master
- 6.1.1.4.1: Salesforce Commerce Cloud
- 6.1.1.5: Fraud
- 6.1.1.5.1: Adyen
- 6.1.1.5.2: ClearSale
- 6.1.1.5.3: CyberSource
- 6.1.1.5.4: Signifyd
- 6.1.1.6: Gift Cards
- 6.1.1.6.1: Clutch
- 6.1.1.6.2: Eigen
- 6.1.1.6.3: Givex
- 6.1.1.6.4: SmartClixx
- 6.1.1.6.5: SVS
- 6.1.1.6.6: ValueLink (First Data)
- 6.1.1.6.7: Voucher Express
- 6.1.1.6.8: Worldpay
- 6.1.1.7: Parcel Carrier
- 6.1.1.7.1: Blue Express
- 6.1.1.7.2: Canada Post
- 6.1.1.7.3: CanPar
- 6.1.1.7.4: Channel Advisor
- 6.1.1.7.5: Chilexpress
- 6.1.1.7.6: Coordinadora
- 6.1.1.7.7: CrossLog
- 6.1.1.7.8: Cycleon
- 6.1.1.7.9: DHL
- 6.1.1.7.10: FedEx
- 6.1.1.7.11: Fiege
- 6.1.1.7.12: Logistyx
- 6.1.1.7.13: Loomis
- 6.1.1.7.14: MetaPack
- 6.1.1.7.15: Proship
- 6.1.1.7.16: Purolator
- 6.1.1.7.17: Starken
- 6.1.1.7.18: UPS
- 6.1.1.7.19: United States Postal Service
- 6.1.1.8: Loyalty & Rewards
- 6.1.1.8.1: 500friends
- 6.1.1.9: Promotions
- 6.1.1.9.1: Oracle Relate
- 6.1.1.9.2: Salesforce
- 6.1.1.9.3: XCCommerce
- 6.1.1.10: Tax
- 6.1.2: Manhattan Active® Supply Chain
- 6.1.2.1: Integrated Automation & Robotics
- 6.1.2.1.1: Grey Orange
- 6.1.2.1.2: Locus Robotics
- 6.1.2.2: Parcel Carrier
- 6.1.2.2.1: MetaPack
- 6.2: Access Management 2.0 FAQ
- 6.3: Activity Stream FAQ
- 6.4: Asynchronous Communication with Manhattan Active® solutions via Google Pub/Sub
- 6.5: Overview of AWPF message types
- 6.6: Overview of batch job configuration
- 6.7: Cloud Networking
- 6.8: Create Client Custom Rest API in Access Management 2.0
- 6.9: CUPS overview, setup, and best practices
- 6.10: Extension points and handlers
- 6.11: Access Management 2.0 Identity Provider UI Field Concepts (OIDC)
- 6.12: Overview of scheduler features
- 6.13: Manhattan Active® Supply Chain Intelligence
- 6.13.1: JSON Store Columns in SCI Reports
- 6.13.2: SCI Limits and Guidelines
- 6.13.3: Manhattan Active SCI Status
- 6.13.3.1: Troubleshooting Guidelines
- 6.14: Glossary of key terminology
- 6.15: UI-based Automated Tests
1 - Overview
Manhattan Active® Solutions are the most feature rich SaaS applications in the industry. Most, if not all, of the capabilities needed are already in our products and may be activated by business users through our friendly user interfaces.
However, if the need arises to integrate more fully with your business systems, Manhattan Active® Platform is there for you.
What is Manhattan Active® Platform?
Manhattan Active® Platform is the cloud native platform and associated products and tools that powers Manhattan Active® Solutions:
- MA Active® Supply Chain
- MA Active® Omni and Enterprise Promise & Fulfill
- MA Active® Supply Chain Planning
Why do I want it?
Use Manhattan Active® Platform to adapt your Manhattan Active® Solution to work with your own custom applications. This includes no code, low code, and your code solutions.
For example, for any Manhattan Active® Solution, you can configure SSO login, manage OAuth clients, or call an api.
What is next?
- Get Started: Get started activating your Manhattan Active® Solution.
- Technology Overview: Learn more about our technology
- Call an API: Dive right in and call Manhattan Active® API
1.1 - Technology Overview
Manhattan Active® Platform is a cloud-native platform for deploying and managing Manhattan’s Active® SaaS solutions such as the Manhattan Active® Omni, Supply Chain, and Inventory. The platform is built using innovative design, cutting-edge technology, software engineering expertise, and modern software development practices. This document is an overview of the objectives, architecture, and inner workings of Manhattan Active® Platform.
The reader is expected to be familiar with the architectural nuances of a modern enterprise SaaS solution and technologies such as Java, Spring framework, Docker, and Kubernetes. Familiarity with deployment architecture concepts such as load balancing, high availability, security, and operations management is also recommended.
Manhattan Active® Platform Objectives
The fundamental goal of Manhattan Active® Platform is to provide a scalable, highly available, secure, and resilient runtime for the Manhattan Active® solutions. To achieve this goal, three core objectives and the corresponding architectural principles are woven into the design of the platform:
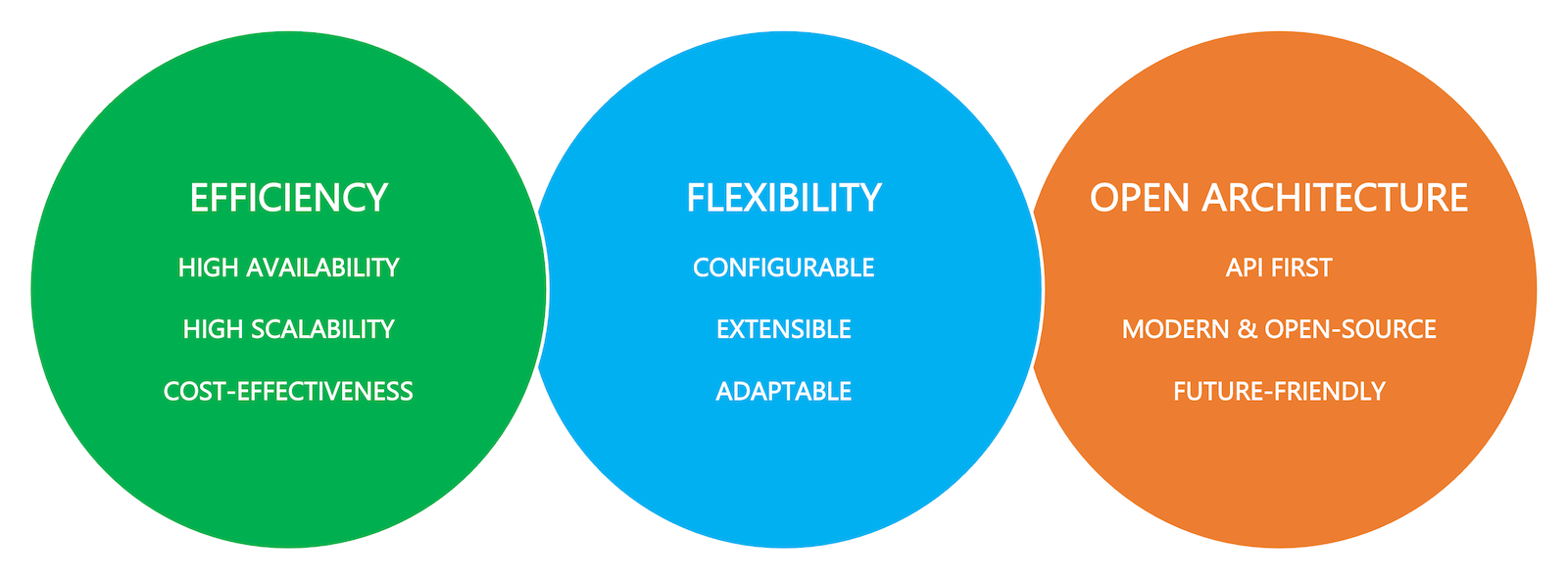
Efficiency
The Manhattan Active® Platform is designed to run as an efficient machine to serve customers with varying volume and throughput requirements at the maximum throughput while minimizing the cost of ownership for Manhattan and the customers. The efficiency of Manhattan Active® Platform comes from its ability to run business transactions with:
- High availability to maximize the uptime of the applications and to maintain business continuity based on the committed SLAs
- Elasticity to proactively scale compute proportional to the size of the business workloads
- Cost-effectiveness to maximize the value of compute resource consumed while keeping the costs of compute low by eliminating overcommitment and waste
Flexibility
Users are most productive when the software fits well in the existing ecosystem without mandating modifications to established usage practices that require additional training efforts or incurring sizable upgrade costs. In other words, software must be malleable to fill the business gaps in an existing ecosystem. Flexibility is built into the Manhattan Active® Platform for it to be:
- Configurable based on the purpose, use cases, and requirements of the customer
- Extensible to allow customizations of business workflows and data models
- Adaptable to allow seamless integration with other applications in the customer’s environment
Open Architecture
Manhattan Active® Platform leverages modern open-source technologies and cloud-native architecture to make it polyglot and pluggable to a variety of compute vendors. Because of its open architecture, Manhattan Active® Platform can:
- API-First: Business interfaces and data operations are exposed as well-documented REST API endpoints that work equally well for both custom integration and Manhattan Active® Solution user interfaces
- Open-source: Developed, tested, delivered, deployed, and managed using well-accepted and commonly available open-source languages, frameworks, and runtimes
- Current: Remain current with the latest bugfixes and security updates offered by the open-source community
- Future Friendly: Remain future-friendly by adopting modern technologies promptly and often
Cloud-Native Microservices Architecture
The microservice architecture emphasizes modularizing the application into smaller and physically decoupled functional modules, where each module runs and functions independently while presenting a holistic business solution to the end-users. The functional modules can run as one or more instances in a separate, isolated process. Each instance of these functional modules is deployed as a disposable process and interacts with other parts of the system via a lightweight remote communication protocol built using REST/HTTP. A microservice is generally defined as a functional module with a set of key characteristics:
- Bounded context: Well-defined and minimal set of functional responsibilities
- Loosely coupled: Fewest dependencies on other functional modules, and a private state
- Service-oriented: Publishes flexible, yet backward compatible service contracts
- Disposable: Remains stateless with graceful startup and shutdowns, and is reusable
- Concurrent: Can scale horizontally as one or more ephemeral processes on demand
By contrast, applications built with monolithic architecture have multiple, tightly coupled tiers and are typically written as a single large process with a shared state spanning the entire process. Tightly coupled functional modules and a shared state make it harder and more expensive to scale, update, or upgrade the applications.
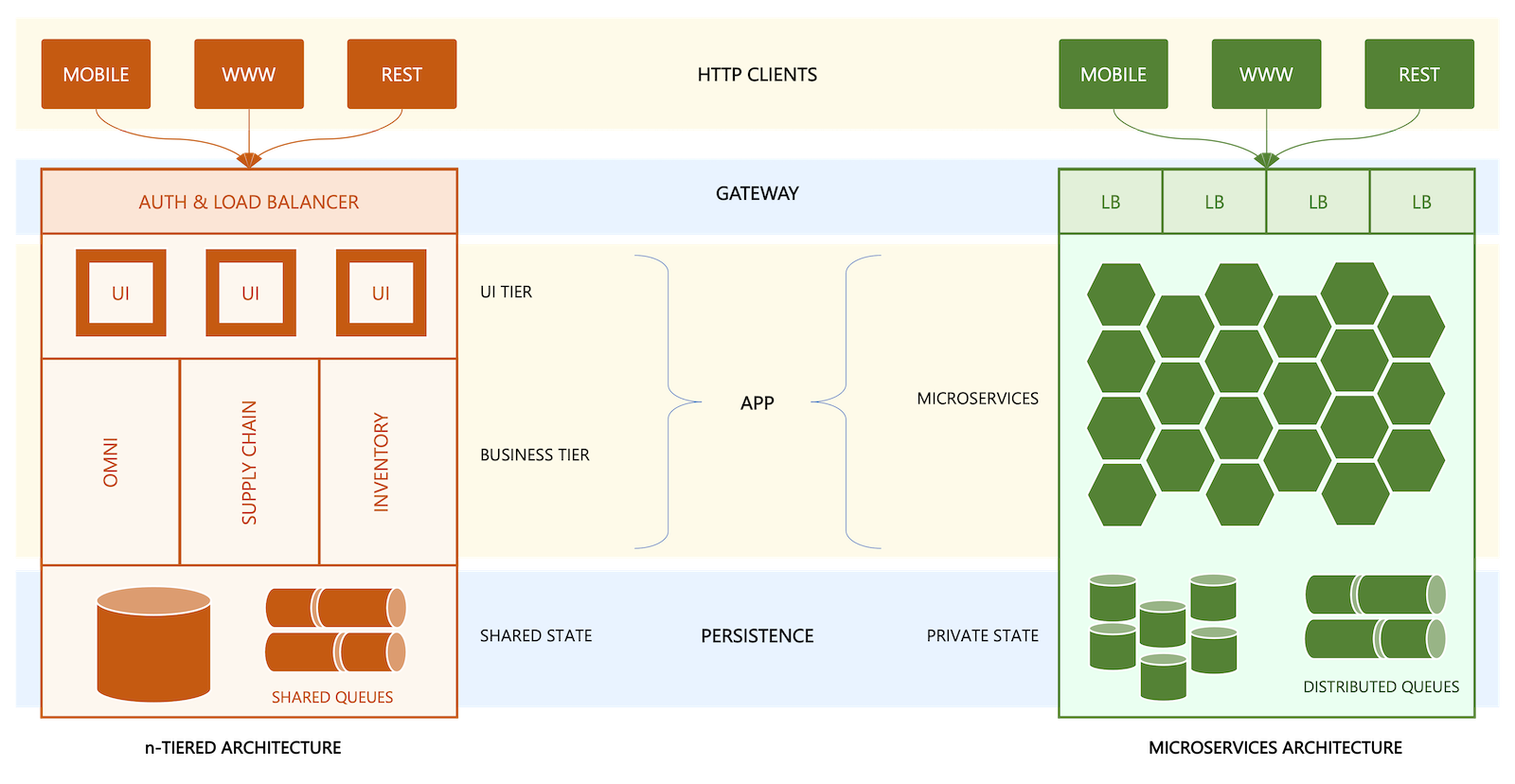
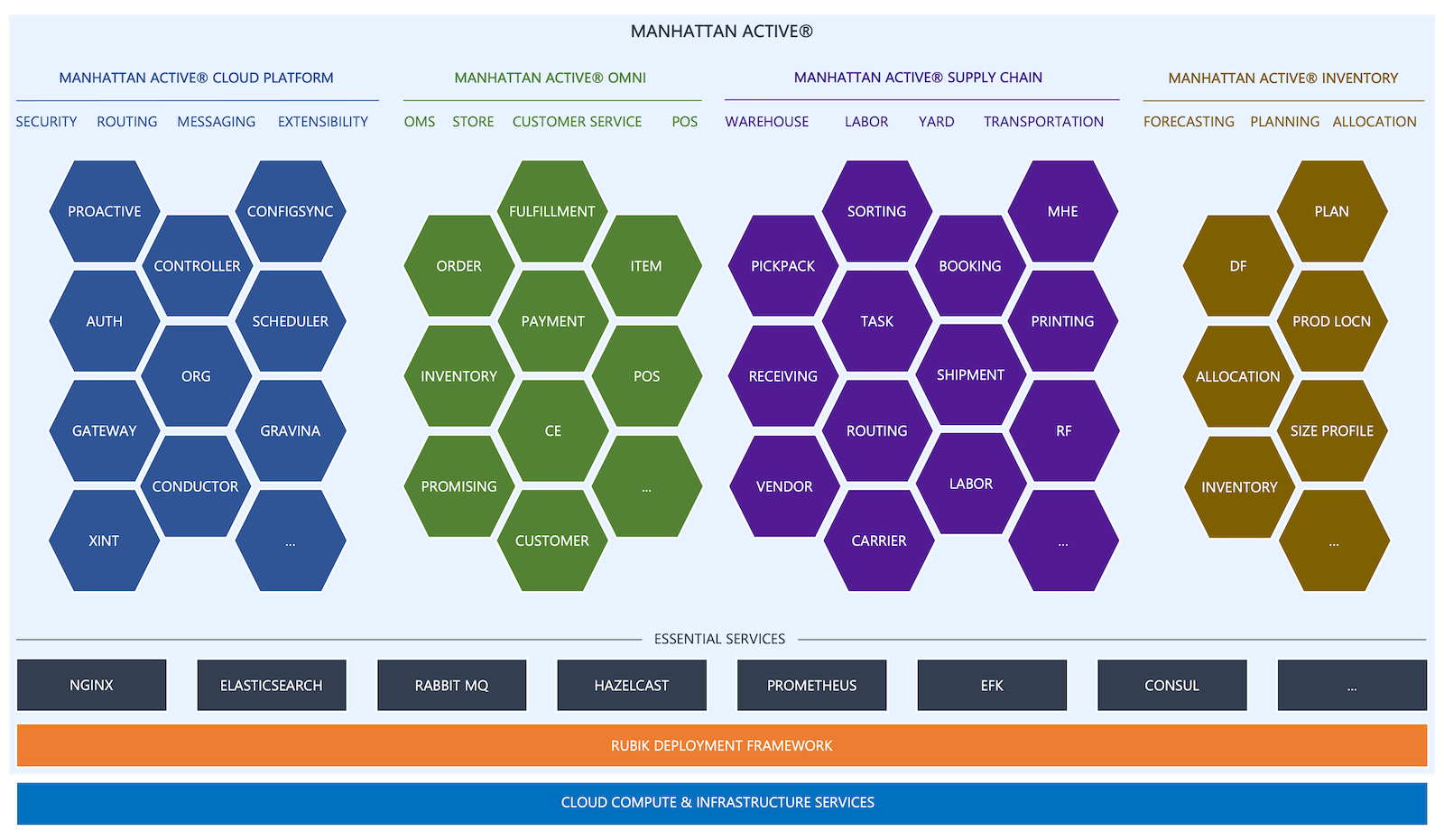
From its conception, Manhattan Active® Platform is built to run microservices as decoupled, independent, and scalable processes. The platform comprises over 250 microservices including:
- The application components and custom extensions to feature the business functionality
- The system services for indexing, messaging, identity & authorization, service discovery, monitoring and logging
- The lifecycle services for automated deployments, upgrades, scaling, healing, and configuration management
Groups of these microservices represent one or more Manhattan solutions such as Manhattan Active® Omni, Supply Chain, or Inventory. Manhattan Active® Platform provides a cloud-native runtime for these microservices, while constantly accommodating new microservices as Manhattan continues to innovate and expand its solutions and business features.
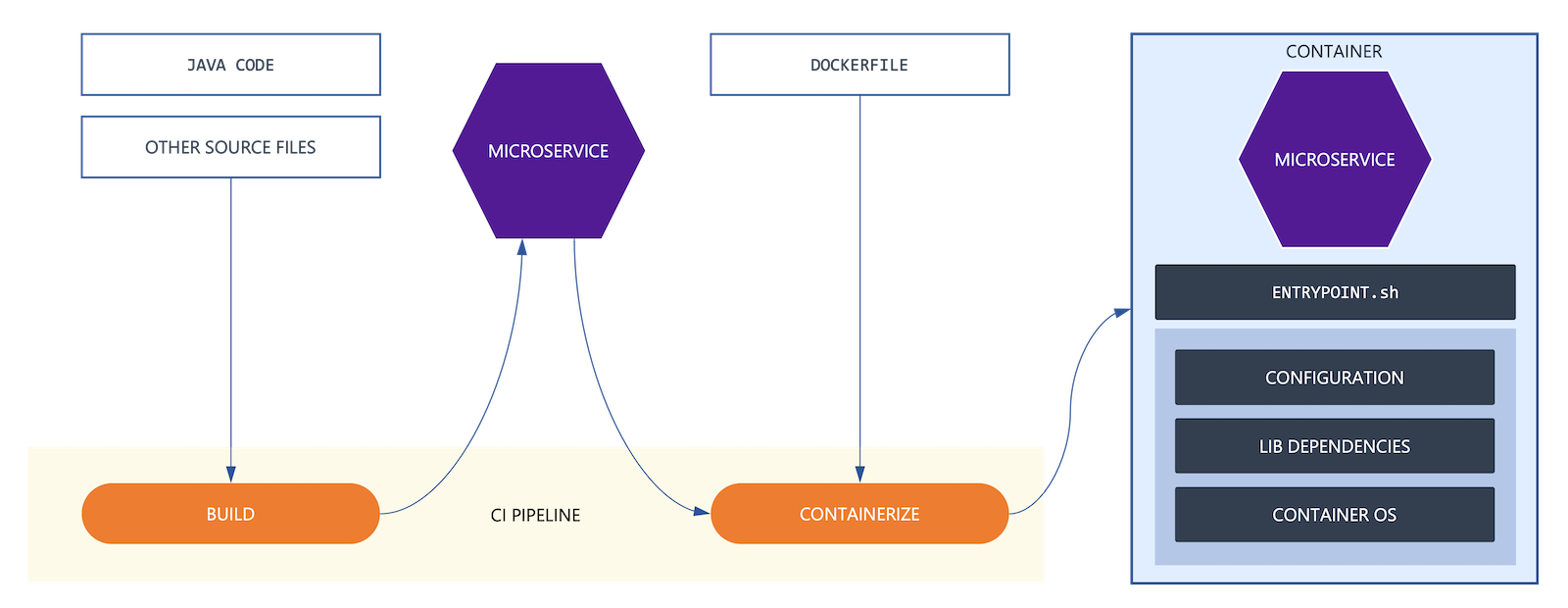
Containers
While the microservices architecture paves the way for building an elegant solution for decoupling, flexibility, and scalability, it wouldn’t be advantageous without an equally reliable deployment architecture. Manhattan Active® Platform relies on modern deployment methods to implement an equally elegant deployment architecture, using containers and Kubernetes at its core. The microservices, or the building blocks of the Manhattan Active® solutions, are built, delivered, and deployed as Docker images. Containerization offers several benefits to the release management processes for these microservices:
- Immutability of the contents of the image for consistency and authenticity of delivery
- Encapsulation of code, configuration, and dependencies into a single delivery instrument
- Isolation of microservice processes by “jail-celling” their execution runtime
- Portability across a variety of supported Docker platforms without the host OS dependency
The Continuous Integration Pipeline which builds, tests, and releases the software binaries, is responsible for containerizing the microservices and publishing them to the container registry for downstream delivery and deployment. Manhattan Active® Platform uses a Debian-based openjdk image as the base FROM layer. As part of the CI pipeline, the layers of the Docker images are scanned for known security vulnerabilities and patched promptly based on the severity of the vulnerability. To ensure a consistent Docker image structure and build process, Manhattan Active® Platform has put in place automated tooling to provision a single Dockerfile template for building the images for all application components.
Container Orchestration
Manhattan Active® Platform uses Kubernetes to manage the microservices containers. The application components and supporting services of Manhattan Active® Platform are configured, clustered, deployed, and orchestrated using pure Kubernetes, without syntactic dependencies on the underlying IaaS provider. Using Kubernetes as the abstraction layer between Manhattan Active® Platform runtime and the IaaS provider allows for a clean decoupling between the two, keeping the Manhattan Active® Platform portable to other IaaS providers.
RUBIK DEPLOYMENT FRAMEWORK
Rubik is the deployment framework built by Manhattan that provides deployment and management abstraction over the underlying infrastructure and the control plane. The Rubik deployment framework automates the deployment of the runtime components of Manhattan Active® Platform. Rubik consists of a set of modular shell scripts, YAML templates for the Kubernetes specifications, and bundles compatible versions of command-line interfaces for kubectl and other infrastructure services. Rubik is built and delivered as a containerized tool-set to the Manhattan Cloud Operations team, which uses it to perform management operations on the target instances.
To ensure that the deployment framework does not become tightly coupled with the underlying cloud provider and to maintain flexibility in choosing cloud providers, Rubik provides a set of consistent commands that work across multiple cloud providers.
RUBIK STACK
Every customer environment is deployed in a network-isolated instance that Manhattan calls a Rubik Stack or simply a Stack. A stack consists of the Kubernetes cluster responsible for orchestrating the containers and a set of infrastructure services.
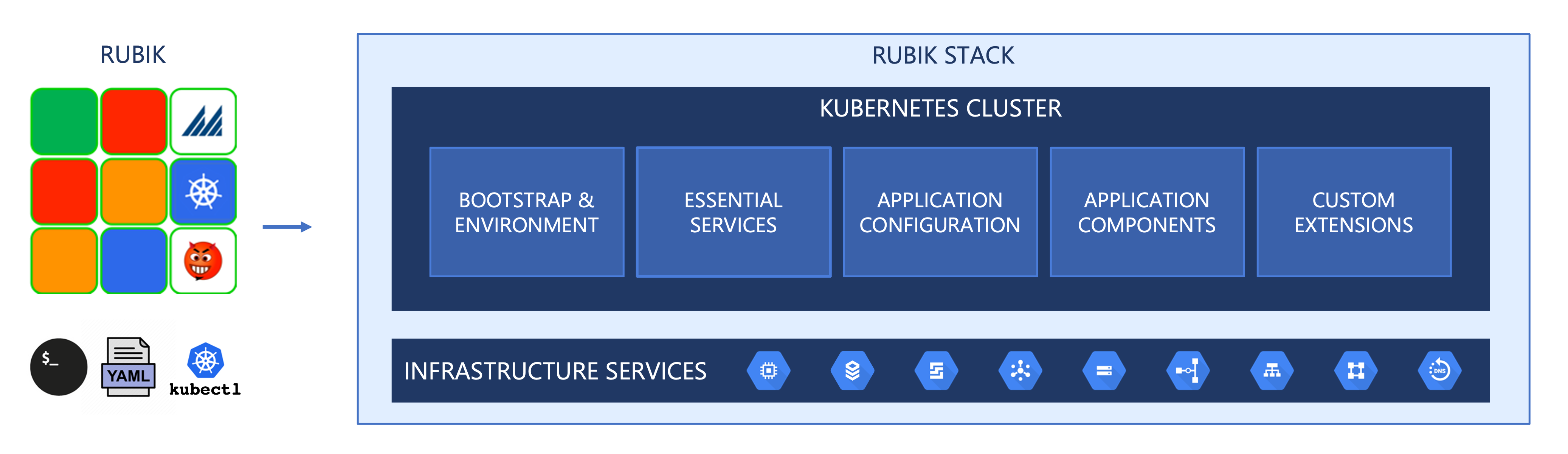
A stack is created using the Rubik deployment framework commands. A newly created stack consists of:
- A Kubernetes Cluster that orchestrates compute resources, network, certificates, environment configuration, and the containers for the application microservices, essential services, and custom extensions
- A set of Infrastructure Services such as the database, IAM, DNS, messaging, and persistent storage.
KUBERNETES CONFIGURATION
The application components and supporting services are configured as Kubernetes specification files for deploying them on a Kubernetes cluster. Some of these specification files are listed below as examples:
StatefulSetspecs are used for defining stateful microservices such as the system services that offer support for persisting state.Deploymentspecs are used for defining stateless microservices such as the application components.Servicespecs are used for binding and load balancing the incoming TCP traffic from the caller to the target container.DaemonSetspecs are used for operations that run as background processes.JobandCronJobspecs are used for performing maintenance tasks on an ad hoc or recurring schedule.ConfigMapandSecretspecs are used for storing configuration or sensitive data used by other runtime services.Ingressspecs are used for defining the gateway endpoints for the incoming traffic.
Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
2 - Getting Started
If you are unfamiliar with Manhattan Active® Platform and would like to learn more about what it is and why you should use it, please visit the Overview.
Before you begin
You will need access to the Manhattan Active® Platform application website, and a System Administrator role to perform most setup tasks. The URL for the Manhattan Active™ Platform will look like the following:
https://<unique_id>.omni.manh.com
https://<unique_id>.sce.manh.com
https://<unique_id>.scp.manh.com
Setup
You may need to configure authentication for your users and create your API OAuth clients:
- Single Sign On
- OAuth Clients for API access
Try it out!
When your setup is complete, try calling an API.
3 - Accessing from Manhattan Active® Solutions
Useful developer content for Manhattan Active® solutions is available for subscribing customers. With the 2023Q3 release of available solutions, a menu item enables customers to access this protected content.
Prerequisites
Users must be granted access to login to the Manhattan Active® solution and have resource grants to access the menu. The Active Release ID of the environment must be 2023Q3.
Grants
To access the Developer Hub link in a solution, ensure the following grants are included in the roles assigned to your user(s):
- sceui::facade::menu::developerHub (Supply Chain)
- omui::order::menu::DeveloperResources (OMNI)
The Developer Menu
With the appropriate release and resource grants, the protected developer site content is just a click away!
Simply click on the help icon and select the Developer Hub option as illustrated:

Available Solutions
4 - How To
4.1 - Call Manhattan Active® API
Manhattan Active® API follows the REST architectural style. Our API has predictable resource-oriented URLs, accepts and returns JSON, and uses standard HTTP response codes, authentication, and verbs.
What’s next
4.1.1 - Authenticate to Manhattan Active® API
Before you begin
Before authenticating to an API, it is necessary to have an authorized user (OAuth resource owner) and an OAuth client.
Authentication information
Manhattan Active® API supports the following OAuth 2.0 authorization grants (OAuth flows):
- Authorization Code Grant (web server flow)
- Resource Owner Password Credentials Grant (password flow)
Please contact your organization’s Manhattan Active® Platform administrator for the following OAuth settings:
| Setting | Description | Example |
|---|---|---|
| API URL | Manhattan Active API URL | https://<unique_id>.omni.manh.com |
| Username | The resource owner username | user@manh.com |
| Password | The resource owner password | h3ll0 |
| Client Id | API client id | <custom_client_id_created_by_your_admin> |
| Client Secret | API client password | <custom_client_secret_created_by_your_admin> |
| Token URL | URL for access token endpoint | https://<unique_id>-auth.omni.manh.com/oauth/token |
| Authorization URL | Authorization Code URL (web server flow) | https://<unique_id>-auth.omni.manh.com |
Authenticate from your code
For access to Manhattan Active® API from your software, please see Call from your code
Authenticate using Postman
For access to Manhattan Active® API from Postman, please see Call using Postman
What’s next
To learn more about calling an individual Manhattan Active® API, please see the REST API documentation in our product sites:
4.1.2 - Call Manhattan Active® API from your code
This how-to guide will walk you through a very simple Python command line utility (CLI). The utility will obtain an access token for Manhattan Active® API using the OAuth 2.0 Resource Owner Password Credentials Grant. That token will then be used to call the following to get information for the authenticated user:
GET /api/organization/user/allDetails/userId/
Before you begin
Before beginning, please assemble the authentication information.
Obtain an access token
The OAuth 2.0 Resource Owner Password Credentials Grant (direct access) may be used to obtain an API access token. The token endpoint may be called as follows:
def access_token(client_id, client_secret, token_url, username, password):
"""Return access token for Manhattan Active® API using the resource owner password credentials grant
Conforms to https://datatracker.ietf.org/doc/html/rfc6749#section-4.3
Must authenticate to token endpoint with client credentials:
https://datatracker.ietf.org/doc/html/rfc6749#section-3.2.1
Args:
client_id (str): client identifier <Consult your Administrator to obtain one>
client_secret (str): client password <Consult your Administrator to obtain one>
token_url (str): endpoint to obtain access token
username (str): the resource owner username
password (str): the resource owner password
Returns:
string: access token
Raises
HTTPError: http error
"""
# Access Token Request: https://datatracker.ietf.org/doc/html/rfc6749#section-4.3.2
response = requests.post(token_url, data={
"grant_type": "password",
"username": username, "password": password},
auth=(client_id, client_secret))
response.raise_for_status()
return response.json()["access_token"]
Call an API
To call the API, obtain an access token above and place it in the Authorization header as a Bearer token:
url = api + "/organization/api/organization/user/allDetails/userId/" + username
response = requests.request(
"GET", url, headers={'Authorization': 'Bearer ' + token}, data={})
response.raise_for_status()
print(json.dumps(response.json(), indent=2))
Run the code
Download the source code
Download the user.py python source code.
Install requests module
python3 -m pip install requests==2.27.1
Set environment variables
Environment variables may be used to store common information:
| Variable |
|---|
| ACTIVE_USERNAME |
| ACTIVE_PASSWORD |
| ACTIVE_API |
| ACTIVE_CLIENT_ID |
| ACTIVE_CLIENT_SECRET |
| ACTIVE_TOKEN_URL |
For example:
export ACTIVE_USERNAME=user@example.com
export ACTIVE_CLIENT_ID=<Custom_Client_Id_Created_By_Your_Administrator>
Run CLI
Run the user.py script to obtain information for the authenticated user.
# See help for getting user info
python3 user.py -h
# Sample call (assumes ACTIVE_PASSWORD and ACTIVE_CLIENT_SECRET environment variables set)
python3 user.py \
-c <Consult your Administrator to obtain the client_id> \
-t https://<environment>-auth.omni.manh.com/oauth/token \
-u user@system.com \
-a https://<environment>.omni.manh.com
Troubleshooting
If you receive a 400 Client Error: for url: https://...-auth.omni.manh.com/oauth/token, then your username and password are invalid for the authorization server.
4.1.3 - Call Manhattan Active® API using Postman
This guide will walk you through the steps for invoking an example REST API exposed by Manhattan Active®. The steps below will also assist you in establishing the authorization using OAuth v2.0 for invoking the API.
Before You Begin
- Download and install Postman or an equivalent tool of your choice. If you already have Postman installed, update it to v9.0.9 or newer.
- You will need the following information from the administrator who manages the implementation of Manhattan Active® applications for you:
- Application URL such as
https://<unique_id>.omni.manh.comorhttps://<unique_id>.sce.manh.comorhttps://<unique_id>.scp.manh.com. We will usehttps://example.omni.manh.comfor this document. - Authorization Server URL such as
https://<unique_id>-auth.omni.manh.comorhttps://<unique_id>-auth.sce.manh.comorhttps://<unique_id>-auth.scp.manh.com. We will usehttps://example-auth.omni.manh.comfor this document. - Values of
client_idandclient_secretparameters as configured by your administrator. Your administrator will need to create a custom client_id (documented elsewhere already) to be used with Postman. The administrator can look up the value of the respectiveclient_secret. We will refer the client_secret as <client_secret> as the value ofclient_secretfor this document. Please use your own client_secret value exclusive for your use cases. - A valid username and password for you to authenticate yourself. We will use
jerrythomas@example.comandp455w0rdrespectively as the username and password for this document. These are not valid credentials at all. Please use valid credentials for your purposes.
- Application URL such as
- As a sample REST API, we will use the endpoint that returns the details of your user. You may replace it with any other REST API that you have access to.
Steps
The step-by-step instructions below include the steps to obtain the authorization token for invoking the target REST API, followed by the invocation of the API.
Obtaining the Authorization Token
1. Open Postman and click on “New”

2. In the pop-up dialog, select “HTTP Request”

3. Click on the “Authorization” tab in the request section under “Untitled Request”

4. Click on the “Type” drop-down and select “OAuth v2.0”.

5. In the right-hand section, scroll down to the sub-section titled “Configure New Token”, and enter the values as shown below:
- Token Name:
my-first-auth-token - Grant Type: Authorization Code
- Callback URL:
https://www.getpostman.com/oauth2/callback - Auth URL:
https://example-auth.omni.manh.com/oauth/authorize - Access Token URL:
https://example-auth.omni.manh.com/oauth/token - Client ID: <client_id> should be created by your Administrator
- Client Secret: <client_secret> should be created by your Administrator
- Scope: leave empty
- State: leave empty
- Client Authentication: Send as Basic Auth header

Click the “Get New Access Token” button to fetch the token.
6. Sign in with your username and password in the pop-up dialog. The pop-up may look different from the screenshot shown below depending on the Manhattan Active® application you are using.

7. Upon a successful login, Postman will display the access token in the UI, and give you an option to use it.

8. In the “Current Token” section of your REST API request, select my-first-auth-token from the list to make use of the token you obtained.

Invoking the REST API call
1. To invoke the API to get the details of your username, set the URL to the value shown below:
http://example.omni.manh.com/organization/api/organization/user/allDetails/userId/jerrythomas@example.com
Set the HTTP method to GET. The inputs will look like this:

Verify that the “Access Token” is set to my-first-auth-token in the “Current Token” section.
Click on the “Send” Button.
2. The API response in JSON format will be displayed in the section on the bottom

You can inspect the response content and headers by switching the response tabs.
Pro Tip
With the access token, you can also invoke the API using curl as a command line option instead of Postman:
curl -L -X GET -H 'Authorization: Bearer eyJhbGciOiJSUzI1Ni...' 'http://example.omni.manh.com/organization/api/organization/user/allDetails/userId/jerrythomas@example.com'
Learn More
4.1.4 - Manhattan Active® API Reference
To learn more about calling an individual Manhattan Active® API, please see the API documentation in our solution sites:
- MA Active® Supply Chain
- MA Active® Omni and Enterprise Promise & Fulfill
- MA Active® Supply Chain Planning
- Manhattan Active® Platform
A complete reference for Manhattan Active® API across all solutions is available in the following site:
4.2 - Configure login modes
Objective
Manhattan Active® Platform Auth Server has administrative user interface to configure or modify several aspects of security such as the authentication and login modes and OAuth client setup. This document describes how you can configure the login modes for authenticating to Manhattan Active® Platform.
Before You Begin
You will need access to the Manhattan Active® Platform application, and a System Administrator role to configure security properties in the Auth Server user interface.
Manhattan Active® Cloud standardizes authorization with OAuth2 for all inbound HTTP traffic. For identity provisioning and active directory integration, Manhattan Active® Cloud supports a variety of authentication modes with Open ID and SAML:
- External Authentication Mode with Open ID is a login configuration where the user is exclusively authenticated via an external Identity Provider using Open ID as the identity protocol. In this mode, all users are maintained by the external Identity Provider.
- External Authentication Mode with SAML is a login configuration where the user is exclusively authenticated via an external Identity Provider using SAML as the identity protocol. In this mode, all users are maintained by the external Identity Provider.
- Mixed Authentication Mode with User Discovery is a login configuration where the user identity is managed either in the Native authentication source by Manhattan Active® Cloud, or by an External Identity Provider with Open ID or SAML. The determination for the authentication mode for the actual user is made in real-time when the user attempts to log in, based on the user’s username. In this mode, the user is first prompted to enter their username, and the UI then redirects to the authentication mode configured for that user.
- Native Authentication Mode is a login configuration where the user is exclusively authenticated by Manhattan Active® Cloud. In this mode, the user directory, and credentials (in the form of usernames and passwords) are maintained in Manhattan Active® Cloud database. Users that are maintained with the native authentication mode are referred to as native users to distinguish them from the users that are maintained in the corporate directory. If no other authentication mode is configured, Native Authentication Mode is the default configuration.
Manhattan supports known Open ID and SAML Identity Providers for configuring as the External Authentication Mode. Integration with the IDPs listed below has been tested and supported:
- Microsoft Azure AD: Open ID & SAML
- ADFS: Open ID & SAML
- Okta: Open ID & SAML
- CA SiteMinder: Open ID
- Ping Identity: Open ID
- MITREid: Open ID
- KeyCloak: Open ID & SAML
- IBM Security Access Manager: SAML
Do note, that IDPs may have their nuances - not all IDPs support the full Open ID and/or SAML standards or may support additional features that are not part of the standards. In such cases, Manhattan offers technical support and consulting to accommodate the testing and validation necessary for a specific IDP to fully integrate with Manhattan Active® Cloud.
To access the administration UI, go to your Auth Server URL (https://<stack_name>-auth.<domain_name>). After you log in, you should see the Administration option as a button that you can use to navigation to the administration UI:

The admin panel is accessible only to the users with the System Administrator role.

There are two main concepts that are important to understand:
Authorization providers
An authorization provider is a configuration for an external identity provider. For example, you could have the following authorization providers stored in the Auth Server configuration:
- OpenID with Okta
- Backup OpenID with Okta
- OpenID with Azure
- SAML external IDP
One of these providers could be used when setting the identity type to external or mixed.
Login mode
The login mode defines how your users will authenticate in the Auth Server.
- Active login mode will be loaded on the Auth Server startup and defines how the users authenticate.
- Pending login mode will be marked when setting a new login mode. If there is a pending login mode when the Auth Server starts it will be marked as Active and the previous Active login mode will be marked as Inactive.
Steps
Click on Configure Login Mode

Select the identity type between database, external or mixed and click Next

If you choose external or mixed in Step 2, it will show the list of available providers. You can also add new ones. Click on Add Authentication Provider to add a new one and select the protocol.

You can also click Show Templates to see predefined providers

Select a template

This will copy the pre-configured parameters, you will have to provide a unique Name that cannot be edited later. Click on Save button

This will create a provider. You can view it under Authentication Providers tab

The new login mode will be Pending until the next restart of the Auth Server.
Global Properties
There are other properties that are not exclusive of either OpenId or SAML. In the Global properties tab you can edit these properties.

Note that these properties will only be loaded when manh.security.dbmode=true and a proper login mode is configured. Properties can be of three types: string, number or boolean.
Learn More
Author
- Shipra Choudhary: Senior Software Engineer, Security, Manhattan Active® Platform, R&D.
4.3 - Configure Data Stream for Google PubSub
Objective
This guide will walk you through the steps for enabling the Data Streaming from Manhattan Active® to Google Cloud Pub/Sub endpoint owned and managed by the customer. The below steps also guides authorization and network access required to post events to this Pub/Sub endpoint.
Gravina is Manhattan Active® Platform’s data replication solution to provide most real-time data streaming service to target systems. It provides set of distributed services that capture row-level changes in databases so that applications can see and respond to those changes. DataStream utilizes JSON for exchanging data between internal & external components.
Google Cloud Pub/Sub provides messaging between applications. Cloud Pub/Sub is designed to provide reliable, many-to-many, asynchronous messaging between applications. Publisher applications can send messages to a “topic” and other applications can subscribe to that topic to receive the messages.
Before You Begin
Deployment model:
- The current scope of this document considers the target Google Cloud Pub/Sub, is owned and managed by Customer. To meet customer business and preferences, we continue to extend our ability to support multiple deployment models.

- The current scope of this document considers the target Google Cloud Pub/Sub, is owned and managed by Customer. To meet customer business and preferences, we continue to extend our ability to support multiple deployment models.
Target Google Cloud Pub/Sub configuration:
- Google Project: Customer owned Google project.
- Region/Location: Google Cloud Pub/Sub is Global Service. but, we prefer to have both producer and subscriber in the same region.
- Pub/Sub topic name ( Optional ): Any preferred topic name to use. By default, Manhattan Active® uses the default gravina_cdc_stream_<customer
Network Connectivity & whitelist:
- Pub/Sub Targets: At present we support Google Cloud Pub/Sub.
- Network Traffic: Since both Source and targets are managed in GCP, traffic is routed through Google backbone interface.
- Access whitelist : If Customer Google Cloud Pub/Sub endpoint is allowed to connect only from the trusted IP sources, then Manhattan Active® Platform NAT range needs to whitelist in Customer network.
Data inclusion list for DataStreaming
- By default, Gravina ignores all tables for DataStreaming unless we define to include in replicator configuration.
- Get the list of database schemas and tables required to enable for DataStream to target system.
Subscription Strategy:
- By default, gravina creates the default subscription which can be used by Customer Application to process the data stream events from Pub/Sub
- Customer owns the configuration of target application subscription(s) and attach to Pub/Sub topic and processing of messages.
Steps
Generate service-account & Key:
- Login to Google Cloud Console –> Go to Google Cloud Project –> IAM & Admin
- Service Accounts
- Create Service Account : Ex: gravina-pubsub-sa
- Go to “Keys”
- ADD KEY –> Create New Key –> Select Key Type : JSON –> Create –> The JSON Key file gets downloaded.
- Provide the JSON Key file to Manhattan CLoud Ops Team in secured way.
- Login to Google Cloud Console –> Go to Google Cloud Project –> IAM & Admin
Grant Pub/Sub Editor permissions to service-account:
- Login to Google Cloud Console –> Go to Google Cloud Project –> IAM & Admin
- IAM
- Click on “ADD”
- Give the gravina-pubsub-sa as principle & Role as “Pub/Sub Editor”
- Save
- Login to Google Cloud Console –> Go to Google Cloud Project –> IAM & Admin
Provide the configuration details to Manhattan Cloud team for replicator configuration.
- Send the Service account “JSON Key file” which have the following details
- project_id
- service-account-id
- Key & secret
- Pub/Sub Topic Name ( If any explicitly needs to configure )
- Inclusion Table List ( If only required specific tables )
- Send the Service account “JSON Key file” which have the following details
Configure Network Access Whitelist in Customer Google Cloud project:
- If the Customer Google project is restricted access, then Manhattan team provide the NAT IP range from which the traffic will be initiated to Pub/Sub endpoint.
- Customer needs to whitelist the NAT IP range in Google Cloud Project to allow the access.
Target Pub/Sub topic Subscription:
- The configuration of subscription to topic and processing of messages are completely managed by Customer based on customer business needs.
- By default, gravina creates the subscription which can be configured and used by Customer Application to process the data stream events from Pub/Sub topic.
Monitoring & Alerts:
- Google Cloud Console provides the default monitoring statistics & metrics.
- Publish message request count.
- Average message size.
- Unacked message count.
- Oldest unacked message age.
- Customer responsible to configure the required monitoring and Alerting based on the business needs.
- Google Cloud Console provides the default monitoring statistics & metrics.
Learn More
Authors
- Srinivasa Rao Jammula: Director, Manhattan Active® Platform, R&D.
4.4 - Configure OAuth Clients
Objective
Manhattan Active® Platform Access Management has administrative screens that manage various aspects of security, including authentication, login modes, and OAuth client setup. Documents that describe OAuth client setup for external integration are based on the version of Access Management.
Identifying Access Management Version
You can identify the version of Access Management based on its URL.
When you enter the environment hostname or the Access Management hostname as the address in your browser, you will be redirected to the login page of the Access Management server.
https://<unique_id>.<domain_name>(environment hostname)https://<unique_id>-auth.<domain_name>(Access Management hostname)
The URL of the login page may be used to identify the version of Access Management -
| Access Management URL | Version |
|---|---|
https://<unique_id>-auth.<domain_name>/org-login | Access Management 1.0 |
https://<unique_id>-auth.<domain_name>/auth/realms/maactive/... | Access Management 2.0 |
4.4.1 - Access Management 1.0
Objective
Manhattan Active® Platform Auth Server has an administrative user interface to configure or modify several security aspects, such as the authentication and login modes and OAuth client setup. This document describes how to set up OAuth clients for external integration and calling the REST API.
Before You Begin
You will need access to the Manhattan Active® Platform solution and a System Administrator role to configure security properties in the Auth Server user interface.
To access the administration UI, go to your Auth Server URL (https://<unique_id>-auth.<domain_name>). After you log in, you should see the Administration option as a button that you can use to navigate to the administration UI:
The admin panel is accessible only to the users with the System Administrator role.
Clicking on the “OAuth Clients” option in the menu will take you to the UI to manage the configuration for OAuth Clients.

The UI has two sections in it:
- Custom clients: includes the clients that are created by users. These clients can be edited and deleted.
- Default clients: pre-configured clients. These cannot be edited but cloned.
Steps
- Go to Custom clients tab and click on the Add button
- Add client details like Client Id and Client secret. The value of the Client secret will be encoded and stored. Optionally, you can set the value of Access token validity and Refresh token validity. Select appropriate Scopes and Grants for this client. For each Scope selected, you have the option if you’d like to auto-approve the requests. You can add one or more Redirect URIs and Resource Ids to this client.
- Hit the Save button, and this creates a new client.
Learn More
Author
- Shipra Choudhary: Senior Software Engineer, Security, Manhattan Active® Platform, R&D.
4.4.2 - Access Management 2.0
Objective
Manhattan Active® Platform Access Management 2.0 (AM 2.0) has an administrative user interface to configure or modify several security aspects, such as the authentication and OAuth client setup. This document describes how you can set up OAuth 2.0 clients for external integration and for calling the REST API.
Before You Begin
You will need access to the Manhattan Active® Platform solution and a System:SystemAdministrator or System:KeycloakAdministrator role to be able to configure security properties in the AM 2.0.
To check your access in the administration UI, go to your AM 2.0 URL (https://<unique_id>-auth.<domain_name>/auth/admin/maactive/console/) and login. Administration UI will look something like this:

Note: The panel is accessible only to the users with the System:SystemAdministrator or System:KeycloakAdministrator role.
Managing OpenID Connect clients
Clients are entities that request authentication on behalf of a user. Clients come in two forms. The first type of client is an application that wants to participate in a Single Sign On. These clients are only looking for security from AM 2.0. The other type of client is the one that requests an access token so that it can invoke other services on behalf of the authenticated user.
Note: In case you have a custom client that you might have created in Access Management 1.0, then you will see that this client should already be migrated to Access Management 2.0. In this case, you will only need to perform client secret updation activity for the same client in the Access Management 2.0 portal. If you have the client’s secret handy, then you can go to the Credentials tab of this client and update the credentials.

If you do not have the secret value, you can create a custom client following the below steps.
Steps
There are two ways to create a new OpenID Connect client. First way is simpler one using the REST API. The second one is creating it using AM 2.0 admininstration UI.
I. Creating client using REST API
Creating a custom client using this approach is much easier and a recommended approach. It does the standard configuration of a client and creates Manhattan specific custom user attributes that will be populated in JWT token for this particular client. In case you have additional configuration requirements in a custom client, please use this approach to create a new client and then login to the administration UI and edit the configurations further.
Below is an example of a REST API that will create a custom client with password and auth-code grant.
Request
POST https://<stack-name>-auth.<domain-name>/clients
Header Parameter
Basic Auth header
Content-Type: application/json
{
"client_id": "testclient",
"client_secret": "xxxxxx",
"scope": ["openid", "testscope"],
"authorized_grant_types": ["password", "authorization_code"],
"redirect_uri": "https://www.getpostman.com/oauth2/callback",
"access_token_validity": 1800
}
Note: access_token_validity is a number field indicating token expiry in seconds. i.e. a value of 1800 represents 30 minutes. Max allowed value is 24 hrs (1 Day).
Example Responses
🟢 Success:
HTTP Status: 200
Response Text: Client (testclient) created successfully under maactive realm.
🔴 Error:
HTTP Status: 401: Authentication Failure. Make a request using valid token in authorisation header.
HTTP Status: 403: Authorization Failure. Access token being used in Authorisation header should belong to a user having SystemAdministrator or KeycloakAdministrator role in Org DB.
HTTP Status: 400: Bad request/Validation error
HTTP Status: 500: Internal Server Error
Response Text: Client (testclient) creation failed.
II. Creating client using the AM 2.0 admininstration UI
Under the Manage menu, click on Clients.

Click on Create client.
Under General Settings, leave the Client type set to OpenID Connect

Enter a Client ID
This is an alphanumeric string that specifies ID reference in URI and tokens.Enter a Name for this client.
Specify the display name of this client.You can optionally give a description of this client in the Description field.
Click on Save. This action will create a client for you.
Next, under Capability config, we have a toggle button to enable/disable Client authentication. This setting depends on the type of OIDC you would like to create.
Select ON if the server-side clients perform browser logins and require client secrets when requesting for an Access Token.
Select OFF if the client-side clients perform browser logins where secrets cannot be kept safe.
Select Authentication flow as needed. Hover over the question mark ? icon to show a tooltip text that describes which AM 2.0 Authentication Flow Maps to which OAuth2 Grant Type.
Click on Next.
Enter the Valid redirect URIs as needed.
This is the place where the browser redirects after a successful login.
NOTE: If you want to use Postman to get an access token using this client for Authorization Code Grant, configure this URL in the Valid redirect URI field - https://www.getpostman.com/oauth2/callback
You will be redirected to the basic client configuration page. You can review or modify any other details needed on this page.

In case the Client Authentication was set to true in step 8, you will see a Credentials tab. Click on it. Take note of the Client Secret to be used during the authentication of this created client against AM 2.0.

The next step is to add claims that will be sent as part of the access token, or to be returned during the user info endpoint call. Go to the Client scopes tab. A dedicated scope will be automatically created for this client. Click on this scope.

This scope will initially be empty. Here is where we need to add the user attributes. Click on Configure a new mapper.

From this list of mappings, select the User Attribute mapper.

In this example, we will see how to configure the “sub” attribute.
Enter Name as sub.
Enter User Attribute as sub.
Enter Token Name Claim as sub.
Select Claim JSON Type as String.
Toggle ON Add to access token.
Hit Save.
We can see that the sub claim is now added to this client’s dedicated scope.

Similarly, you can add other claims as per application requirements. To add another claim, click the Add Mapper dropdown and select the By configuration option.

Repeat the same steps from 16-18 to map all the attributes (similar to sub attribute) as listed in the table below.
User Attribute Token Claim Name Claim Type Present in Access Token Present in ID Token Multivalued sub sub String TRUE FALSE FALSE organization organization String TRUE FALSE FALSE userOrgs userOrgs String TRUE FALSE TRUE bulkOrganizationAccess bulkOrganizationAccess boolean TRUE FALSE FALSE userBusinessUnits userBusinessUnits String TRUE FALSE TRUE excludedUserBusinessUnits excludedUserBusinessUnits String TRUE FALSE TRUE bulkBusinessUnitAccess bulkBusinessUnitAccess boolean TRUE FALSE FALSE userDefaults userDefaults JSON TRUE FALSE TRUE userLocations userLocations JSON TRUE FALSE TRUE largeStoreAccess largeStoreAccess boolean TRUE FALSE FALSE locale locale String TRUE TRUE FALSE edge edge String TRUE FALSE FALSE tenantId tenantId String TRUE FALSE FALSE userTimeZone userTimeZone String TRUE FALSE FALSE authorities authorities String TRUE FALSE TRUE reporting_roles reporting_roles String TRUE FALSE TRUE user_name user_name String TRUE FALSE FALSE Navigate to Scope tab of this dedicated scope and toggle OFF the Full scope allowed option.

Learn More
Author
- Shipra Choudhary: Senior Software Engineer, Security, Manhattan Active® Platform, R&D.
4.5 - Configure Identity Providers
Objective
Manhattan Active® Platform Access Management has administrative screens that manage various security aspects, including authentication, login modes, OAuth client setup, and Identity Provider Configuration. Documents that describe various flavors of Identity Provider Setup for external integration are based on the type of Identity Provider Integration Sought. There are two available:
- Azure Ad
- Okta.
Introduction
As a premier SaaS provider in the market, Manhattan prioritizes the security of its Active Platform software. In alignment with this commitment, we are pleased to announce the release of an enhanced version of the Manhattan Identity & Access Management (IAM) system, named Access Management 2.0. This updated version not only delivers enhanced security features but also offers improved integration capabilities with customer-owned identity platforms such as Azure and Okta. Previously, the Manhattan Active Platform supported Just In Time (JIT) user provisioning exclusively for the SAML 2.0 protocol. With Access Management 2.0, JIT support has been extended to include the OpenID Connect (OIDC) protocol as well. The subsequent sections provide comprehensive guidance, including illustrative screen captures, on configuring Access Management 2.0 alongside Azure and Okta as external Identity Providers (IdPs) for both JIT and non-JIT use cases within the OIDC protocol.
Assumptions
- The configuration screens shown for both Azure and Okta could change with time.
- This document will be kept in alignment when that happens.
- If further assistance is needed during configuring Access Management 2.0 for OIDC JIT/Non-JIT, please reach out to your Manhattan Services Representatives to seek help and report any issues with this document.
Special Note
- Access Management 2.0 creates a Local User for every external Identity Provider (IdP) User.
- After creation in the JIT Flow, such external Users are also created in the Organization Database.
- If, subsequently, the same user is deleted and recreated through the JIT process, to remove roles/orgs/locations, such deletion is:
- First, not needed
- Second, it blocks the same user from logging in because Access Management 2.0 cannot find the Id of the internal user
- To proceed, usually add and remove roles/org/location, and the JIT process will update the same user in the Organization DB.
- If such users must be deleted, please reach out to Manhattan Operations for a subsequent cleanup in the Access Management 2.0 DB.
4.5.1 - IDP Initiated Login with Okta and AccessManagement 2.0 via SAML 2.0
Introduction
In AccessManagement 2.0, an IDP-initiated login enables users to begin the authentication process directly from an Identity Provider (IDP), like Okta, instead of a Service Provider (SP) or application. In this flow, the IDP sends a SAML authentication response to AccessManagement 2.0, which verifies the response and grants the user access to the target application. Common in SAML-based single sign-on (SSO) configurations, this approach allows users to log in from a central IDP-managed portal, streamlining access across applications and improving user experience with a single, centralized login point. Here, we will detail how to set up an IDP-initiated login between Okta and AccessManagement 2.0 via SAML 2.0. The section is segregated into two parts: the first section is related to changes on AccessManagement 2.0’s side, and the second section is related to changes on Okta’s side. As a pre-requisite, please have the SAML 2.0 IDP created. To create an OKTA SAML2.0 IDP, please follow the steps mentioned here if needed.
Section 1: Changes on AccessManagement 2.0’s side
Step 1
AccessManagement 2.0 needs to understand how to handle SAML assertions from Okta, which is accomplished by exporting and importing the correct metadata and establishing a Client. Log in to the admin console. Go to your already created IDP and click on the SAML 2.0 Service Provider Metadata link. Copy and save the contents from the metadata link in a .xml file.


Figure: Sample content of SAML 2.0 service provider metadata
Step 2
Go to the Clients section of the maactive realm and click Import client. On the next page, click Browse and import the .xml file exported in Step 1. Then, scroll down and click Save.


Step 3
Go to the IDP-Initiated SSO URL name on the same page and give a name to your app.

Step 4
Go to IDP Initiated SSO Relay State and enter the stack URL.

Step 5
Ensure that Force POST binding is On. Scroll down and disable Front channel logout. Once done, click Save.


Step 6
Scroll to the top and click the Advanced section. Scroll down and add the stack URL in the Assertion Consumer Service POST Binding URL.


Step 7
Remove content from Assertion Consumer Service Redirect Binding URL

Step 8
Remove the content of the Logout Service POST Binding URL.

Step 9
Scroll down and select Browser Flow as MA first broker login from the dropdown. Click Save. This concludes all changes at AccessManagement 2.0’s end.

Section 2: Changes on IDP’s (Okta) end
Step 1
Log in to Okta, go to your application, and click on the General tab. Scroll down and click on Edit in the SAML settings section.

Step 2
Click Next in the General Settings of the Edit SAML Integration section.

Step 3
Compose the Single Sign On URL by entering the AssertionConsumerService (ACS) URL, followed by /clients/<name of your app>. The ACS URL can be obtained from the XML file imported in Step 2 of Section 1, and the app name is the name given in Step 3 of Section 1. This is the endpoint in AccessManagement 2.0 where the IDP sends the SAML assertion (authentication response) after a user has successfully authenticated.

Step 4
Ensure that the value of Audience URI (SP Entity ID) is the entityID. The entityID can be obtained from the XML file imported in Step 2 of Section 1. Also, enter the value of Default RelayState as the stack URL.

Step 5
On the same page, click the Show Advanced Settings section and scroll down. Look for Other Requestable SSO URLs and enter the AssertionConsumerService (ACS) URL. The ACS URL can be obtained from the XML file imported in Step 2 of Section 1. This step is necessary if the same IDP has to work for SP-initiated flow as well. This concludes all changes needed on IDP’s(Okta) end.

Authors
- Mustaque Rashid, Technical Lead, R&D-Cloud platform.
- Kaveen Jagadeesan, Technical Director - Software Engineering, R&D-Cloud platform.
- Binit Datta, Technical Director - Software Engineering, R&D-Cloud platform.
4.5.2 - Configure Azure Entra ID SAML 2.0 IdP for JIT & Non JIT
Objective
This page describes the Microsoft Entra ID SAML 2.0 setup with JIT and Non JIT flows.
It has a detailed step-by-step guide for registering an enterprise SAML 2.0 application in Microsoft Entra ID as an Identity Provider and configuring Access Management 2.0 as a Service Provider (SP) to enable SAML-based identity federation.
Introduction
Configuring Microsoft Entra ID as Identity Provider (IdP) with Access Management 2.0 (AM 2.0) as Service Provider (SP) using SAML 2.0 protocol.
This documentation provides a comprehensive guide to setting up and configuring Microsoft Entra ID (formerly Azure Active Directory) as the IdP and Access Management 2.0 as the SP using SAML 2.0 protocol. This setup enables secure single sign-on (SSO) capabilities for enterprise applications while leveraging the robust identity and access management features of Microsoft Entra ID and the flexibility of AM 2.0.
Additionally, this guide covers the implementation of Just-In-Time (JIT) provisioning, which automatically creates user accounts in Access Management 2.0 as they log in, streamlining user management and enhancing operational efficiency.
Prerequisites
Before proceeding, ensure you have the following:
- Microsoft Entra ID Tenant: Administrative access to configure enterprise applications in the Azure portal.
- Access Management 2.0 Server: A working AM 2.0 instance installed and accessible with administrative privileges.
- Basic knowledge of SAML 2.0: Familiarity with SAML 2.0 terminology and workflow, including metadata exchange, assertions, and bindings.
- SSL/TLS Setup: Both Microsoft Entra ID and AM 2.0 should be configured to use HTTPS for secure communication.
Key Features
Seamless SSO with SAML 2.0/ This integration leverages SAML 2.0 to provide a secure and seamless SSO experience for users, allowing them to authenticate through Microsoft Entra ID and access applications managed in AM 2.0 without needing to re-enter credentials.
JIT Provisioning Support/ With JIT provisioning enabled, user accounts are dynamically created or updated in Access Management 2.0 the first time a user authenticates through Microsoft Entra ID. This eliminates the need for manual user synchronization, reducing administrative overhead.
Flexible Configuration/ This guide provides step-by-step instructions for:
- Registering and configuring an enterprise application in Microsoft Entra ID as an IdP.
- Exchanging metadata between Microsoft Entra ID and AM 2.0 to establish trust.
- Mapping SAML attributes to AM 2.0 user properties to support JIT provisioning.
Customizable Role and Attribute Mapping/ The configuration supports advanced mappings of user roles and attributes from Microsoft Entra ID to Access Management 2.0, enabling fine-grained access control and dynamic policy enforcement.
Scope of the Documentation
This document is divided into the following sections:
Registering a SAML 2.0 Application in Microsoft Entra ID:
- How to create and configure an Enterprise Application in Microsoft Entra ID.
- Configuring SAML settings, including identifier (Entity ID), reply URL (Assertion Consumer Service URL), and signing certificate.
Configuring Access Management 2.0 as a SAML Service Provider:
- Importing IdP metadata into AM 2.0.
- Defining SAML client settings, including binding, principal type, and signature settings.
- Mapping SAML attributes to AM 2.0 user properties.
Enabling Just-In-Time (JIT) Provisioning in Access Management 2.0:
- Configuring user attribute mappings for automatic account creation and updates.
- Customizing role assignments and group memberships during provisioning.
By the end of this guide, you will have a fully functional SAML 2.0 integration between Microsoft Entra ID and AM 2.0, complete with JIT provisioning support for a scalable and efficient user authentication workflow.
Steps to achieve AM 2.0 integration with Microsoft Azure
Step 1: Sign in to the Azure Portal
- Navigate to the Azure Portal.
- Sign in using an account with administrative permissions for Microsoft Entra ID.
Step 2: Create a New Enterprise Application in the Azure portal
Click on the Enterprise Application icon.

Click on New Application.

Click on Create your own application.

Give a name to your application.

Select Integrate any other application you don’t find in the gallery (Non-gallery application) radio button.
Click Create. This creates a basic SAML application in the Azure portal and now you will land on its overview page.

After the application is created, click on Set up single sign-on tile.

Select SAML as the single sign-on method.

In the SAML Certificates tile, you will be able to see the App Federation Metadata URL field which has IDP metadata. Keep this URL handy for step 4.

Step 3: Sign in to the AM 2.0 portal
Login to AM 2.0 Admin Console. Select the maactive realm.
Note: In case you have Restricted Admin Access on AM 2.0, then use this URL:
https://<stack_name>-auth.<domain_name>/auth/admin/maactive/console/
Step 4: Create an IDP config in the AM 2.0 portal
Click on the Identity Providers option from the left panel and select SAML v2.0 from the drop-down.

Enter the Alias. This will be the default display name on the login page.
Please note that the Alias forms a part of the redirect URL. In case it does not reflect, you can create the Redirect URI yourself and keep the URL handy.
Eg. if Alias is set as - samlazure
Redirect URI -https://localdocker:8443/auth/realms/sample/broker/samlazure/endpoint
Optionally, enter Display Name. This is the name that will be displayed in case you need it to be different from the alias.
Take note of the Service provider entity ID value from the same page.
In the Service entity descriptor field, paste the URL you copied from step 2.9. If the URL is correct, you will see a green tick on the right.
Click on Add. This will create a basic SP configuration on AM 2.0 for this Azure application.
Scroll down and set the Want AuthnRequests signed option to be On.

Now scroll to the bottom of AM 2.0’s provider configuration page and select First Login Flow and Post Login Flow, if not already pre-selected.

Click on Save.
Step 5: Configure AM 2.0 details in Azure IDP
In the Single sign-on tab, edit the Basic SAML Configuration and fill in the Entity ID from step 4.4.

Copy the redirect URI from step 4.2 and paste it into the Add reply URL.

Hit the Save button on the top. You will see a confirmation message after doing so.

Step 6: Configure User.UserId Mapper on AM 2.0 as well as Azure side
To add mappers in AM 2.0, click the Mappers tab on the same SP configuration page. Click on the Add mapper button.

Configure User.UserId mapper by filling in the fields as shown in the image below.

Click on Save.
Now to add this attribute on the Azure IDP side, go to the Single sign-on tab and edit the Attributes & Claims tile.

Click on Add new claim and then add User.UserId as an attribute as shown below.


Step 7: Configure Mapping for JIT (this step is mandatory only if you would like to enable SAML JIT)
To add mappers in AM 2.0, click the Mappers tab on the same SP configuration page. Click on the Add mapper button.
Similarly, configure the User.LocaleId mapper by filling in the fields as shown in the image below.

Click on Save.
Similarly, configure User.PrimaryOrgId mapper by filling in the fields as shown in the image below.

Click on Save.
Similarly, configure User.Roles mapper by filling in the fields as shown in the image below.

Click on Save.
Now, to add these attributes on the Azure IDP side, go to the Single sign-on tab and edit the Attributes & Claims tile.
Click on Add new claim, then add the User.LocaleId, User.PrimaryOrgId, and User.Roles attributes individually.
Step 8: Additional attributes configuration
In case additional attributes are needed, they can be configured as well. Below is a list of attributes that can be configured.\
You will have to pass these exact attribute names from Azure to receive on AM 2.0.
Attributes shown below can be configured on IDP, as well as SP.
| Access Management 2.0 SAML Attribute Name | |
|---|---|
| User.UserId | |
| User.PrimaryOrgId | |
| User.FirstName | |
| User.LastName | |
| User.LocaleId | |
| User.DateOfBirth | |
| User.UserOrgs | |
| User.Locations | |
| User.Gender | |
| User.Address1 | |
| User.Address2 | |
| User.City | |
| User.State | |
| User.PostalCode | |
| User.Country | |
| User.Phone | |
| User.Email2 | |
| User.UserTimeZone | |
| User.AvailableUserLocales |
Author
- Shipra Choudhary: Senior Software Engineer, Security, Manhattan Active® Platform, R&D.
4.5.3 - Configure Okta SAML 2.0 IdP for JIT
Objective
This page describes the Okta SAML 2.0 setup with JIT and Non JIT flows.
Integrating Access Management 2.0 with Okta SAML 2.0
This section shows how to integrate Access Management 2.0 (AM 2.0) with Okta, where Okta will serve as the Identity Provider (IdP). The protocol used for authentication is SAML 2.0. Steps involve exchanging the IdP Metadata (URL generating XML) and the Service Provider Metadata URL between the IdP and the AM 2.0 SP.
Step 1: Identity provider in AM 2.0.
Login to AM 2.0 Admin Console. Select the maactive realm.
Note: In case you have Restricted Admin Access on AM 2.0, then use the URL:
https://<stack_name>-auth.<domain_name>/auth/admin/maactive/console/Click on the Identity Providers option from the left panel and select SAML v2.0 from the list of providers.

Enter the Alias. This will be the default display name on the login page.
Please note that the Alias forms a part of the redirect URL. In case it does not reflect, you can create the Redirect URI yourself and keep the URL handy.
Eg. if Alias is set as - samlokta
Redirect URI - https://localdocker:8443/auth/realms/sample/broker/samlokta/endpoint
Optionally enter Display Name. This is the name that will be displayed, in case you need it to be different from the alias.
Take note of the Service provider entity ID value from the same page.
Step 2: SAML 2.0 App Registration in Okta
Next, we need to create an IDP in Okta. In the Okta admin page, go to Applications → Click Create App Integration.

Select the SAML 2.0 radio button, and click Next.

Provide the application name under the App name, and click Next.

Copy Redirect URI from AM 2.0’s provider page, from Step 1. Configure this URL in the Single sign on URL field.

Copy the Service Provider Entity ID from AM 2.0’s provider page, from Step 1 and configure this URL in the Audience URI field.
Leave other fields to default values. Hit Next. Select the fields as indicated below and select Finish.

Step 3: Get the IdP Metadata URL From Okta
Now in the same Okta application configuration page, click on the Sign On tab. You will find the metadata URL here. Please copy this URL and we will configure this in AM 2.0

Step 4: Configure AM 2.0 With IdP Metadata
Paste the metadata link from Okta in the SAML entity descriptor field on AM 2.0’s provider page. If the URL is correct, you will see a green tick on the right.

Click on Add. This will create a basic SP configuration on AM 2.0 for this Okta application.
Step 5: Configure other fields on AM 2.0
Scroll down and set the Want AuthnRequests signed option to be On.

Now scroll to the bottom of AM 2.0’s provider configuration page and select First Login Flow and Post Login Flow, if not already pre-selected.

Click on Save.
Step 6: Configure Mapping for JIT (this step is mandatory only if you would like to enable SAML JIT)
In case a customer requires SAML JIT need to be enabled, we need to add 4 mandatory mappers on both sides - AM 2.0 as well as Okta. In case SAML JIT is not required, please skip this step entirely.
To add mappers in AM 2.0, click the Mappers tab on the same SP configuration page. Click on the Add mapper button.

Configure User.UserId mapper by filling in the fields as shown in the image below.

Click on Save.
Similarly, configure User.LocaleId mapper by filling in the fields as shown in the image below.

Click on Save.
Similarly, configure User.PrimaryOrgId mapper by filling in the fields as shown in the image below.

Click on Save.
Similarly, configure User.Roles mapper by filling in the fields as shown in the image below.

Click on Save.
To add mappers on the Okta side to support SAML JIT, go to the General settings tab and click on the Edit button in SAML Settings.

Navigate to the SAML Tab by clicking on the Configure SAML button. Go to the Configure SAML tab and add the 4 attributes as shown below.

Note: the values shown in the above image in the Okta side mapper configuration are only for example. Please enter values as per your requirements.
Click on Next and then click on Finish. You are now done with the SAML JIT configuration.
Step 7: Configure logout
To configure logout, a Signing certificate needs to be extracted from AM 2.0 and saved on the Okta side.
To extract this Signing certificate from AM 2.0, go to Realm settings → Keys → Certificate.

The certificate will look like below:

Follow the template shown below to create a new certificate file.
—–BEGIN CERTIFICATE—–
<PASTE THE CERT HERE!>
—–END CERTIFICATE—–Replace the text “<PASTE THE CERT HERE!>” with the copied certificate data from above. It should look like this after the replace:

This file needs to be saved on the Okta side. Now on the Okta side, go to the General settings tab and click the Edit button in SAML Settings. Click on Show Advanced Settings.

The certificate saved goes in the Signature Certificate field.

Get the Single Logout URL from the AM 2.0 metadata URL of this realm. The metadata link can be found on the IDP configuration page, as shown below.

The metadata will look like below:

Extract this URL and save it in the Single Logout URL field.
The SP issuer will be the same as the SP Entity ID, which we saw in Step 1.
After saving all of these changes, go to the Sign On tab in Okta and get the metadata URL.

Okta metadata will now have a SingleLogoutService field populated to reflect the Logout URL.

Use this URL to configure the logout on the AM 2.0 side. Save the change.

Step 8: Additional attributes configuration
- In case additional attributes are needed, they can be configured as well. Below is a list of attributes can be configured. You will have to pass the attribute from the IDP side to receive on SP side.
| Keycloak Attribute Name | SAML Attribute Name | Multi Valued or Not |
|---|---|---|
| User.UserId | User.UserId | No |
| User.PrimaryOrgId | User.PrimaryOrgId | No |
| User.FirstName | User.FirstName | No |
| User.LastName | User.LastName | No |
| User.LocaleId | User.LocaleId | No |
| User.DateOfBirth | User.DateOfBirth | No |
| User.UserOrgs | User.UserOrgs | Yes |
| User.Locations | User.Locations | Yes |
| User.Roles | User.Roles | Yes |
| User.Gender | User.Gender | No |
| User.Address1 | User.Address1 | No |
| User.Address2 | User.Address2 | No |
| User.City | User.City | No |
| User.State | User.State | No |
| User.PostalCode | User.PostalCode | No |
| User.Country | User.Country | No |
| User.Phone | User.Phone | No |
| User.Email2 | User.Email2 | No |
| User.UserTimeZone | User.UserTimeZone | No |
| User.AvailableUserLocales | User.AvailableUserLocales | Yes |
4.5.4 - Configure Okta OIDC IdP for JIT
Objective
This page describes the Okta OIDC setup with JIT and Non JIT flows.
Integrating Access Management 2.0 with OKTA OIDC
This section shows how to integrate Access Management 2.0 with OKTA, where OKTA will behave as the Identity Provider (IdP). The protocol used for authentication is OIDC. Steps involve creating an OIDC client on both sides.
Step 1: Identity provider in Access Management 2.0.
- Login to the Access Management 2.0 admin console. Select the correct realm, here it’s maactive.
https://xxxxxx-auth.sce.manh.com/auth/

If you only have Restricted Admin Access, then use the URL:
https://<stack_short_name>-auth.<domain_name>/auth/admin/maactive/console/
- Verify the Realm.

- Click Identity Providers → Add providers and select OpenID Connect provider from the list of providers.

- Enter the Alias and the Display name.
Alias also forms part of Redirect URL. For example, if the Alias is scoeoidc, then the Redirect URI is:
https://xxxxxx-auth.sce.manh.com/auth/realms/maactive/broker/scoeoidc/endpoint
Copy this redirect URI to register the application In OKTA.

Step 2: App Registration in OKTA
The instructions described below can be used to integrate the Manhattan Active Cloud Platform with OKTA Login
- Login to your OKTA Account → Go to Applications → Click Create App Integration.

- Select OIDC - OpenID connect radio button and then Web/Native Application radio button on the Application Type Panel, and click Next.
Provide the name of the application and paste that Redirect URI from step1-C to Okta Sign-in redirect URIs



The below screen will be displayed after Save Operation on Okta.

- Follow the below steps to create a client_secret key.
Edit and select client secret → save. As soon as you hit Save, you see Client Secret. Copy this for further configuration. Unselect Proof Key for Code Exchange (PKCE)

Copy the Client ID, Client Secret from the above screen, and Metadata Well known URI as below to register it in Access Management 2.0.
There is a concept in OIDC Application called the Metadata Well Known URI.
The general format (in Okta) is https://host:<port>/oauth2/default/.well-known/openid-configuration. In our case:
https://dev-95801423.okta.com/oauth2/default/.well-known/openid-configuration
- Assign users to the application in OKTA.
Step 3: Integrating Access Management 2.0 with OKTA OIDC
- Go to Access Management 2.0 Admin and paste the OpenID connect metadata URI in the Discovery endpoint as shown below (click on show metadata to see the rest of the endpoints).

- Select Client Authentication as Client secret sent as basic auth, paste the client ID and client secret value, and then hit add.

- Next, click on advanced to add the default scopes as shown below.

Next, choose the First Login Flow as MA first Broker login if not already configured. Once done, choose the MA post login flow as the Post Login Flow drop down. This is an important step, and it is needed for the IDP login to work fine.

Manually add users to the application with appropriate roles. This completes the integration of Access Management 2.0 and OKTA using the OIDC protocol.
Click on the application URL and use the icon in the UI to log in through OKTA-ODIC. In our case it is
scoeoidc
Step 4: Enabling JWT-OIDC-JIT – OKTA
Creating/adding mappers in Access Management 2.0:
To add mappers in Access Management 2.0, go to Access Management 2.0’s provider configuration page, Select the identity providers (Scoeoidc) and click on the Mappers tab.

Click on Add mapper and create the below mappers by filling in the fields as shown in the below screenshots.
- User.UserId:

- User.FirstName:

- User.LastName:

- User.Primary_Org_Id:

- User.Roles:

- User.LocaleId :

Step 5: Adding Custom claims in OKTA:
Login to OKTA portal https://okta-devok12.okta.com/
Login to your OKTA Account → Go to Directory → Click Profile Editor → select User (default).

Next, click on Add Attribute to add the required customer user attributes.

- primary_org_id:

- preferred_roles:

- LocaleId:

Save and Next:

Once the attributes are added to the profile-editor, custom attributes fields will be displayed for the user under the profile.
- → Go to Directory → Click People → select User(ltadimarri@manh.com) → profile → Edit.
Define the values for custom attributes.

Next is Add claims, go to Security tab on the left-hand side, and select the API option.

Under the Authorization Servers tab, select the default authorization server.

Under the claims header, click on the Add Claim button.

Create a new claim called “primary_org_id” as shown below. Click save.

Create a new claim called “preferred_roles” as shown below. Click save.

Create a new claim called “LocaleId” as shown below. Click save.

Follow the above steps to add attributes based on customer requirements.
- Next, assign users to this application in OKTA.
Step 6: Viewing Claims and Attributes in Okta’s Token Preview
Okta provides a way to view the custom claims or attributes passed under the token preview in the authorization server.
- In the Okta admin console, navigate to Security > API > Authorization Servers, select default authorization server, and then go to the Token Preview.
Select the properties for your token request to preview a token payload (ClientID, Grant type, user, and scopes).

Once properties are selected, click on the token preview to view the attributes and claims.

Note: By default, the claims for preferred_username, first name (given_name), and last name (family_name) will be available in the Okta token.
Step 7: JWT-OIDC-JIT Required claims in OKTA.
Note: Please take special care to make sure values mapped to your Identity Provider do not have any unwanted spaces, commas, or other invalid characters before or after the values.
Attributes Shown Below can be configured on IDP as well as SP.
| Access Management 2.0 Attribute Name | Okta OIDC Claim Name |
|---|---|
| User.UserId | preferred_username |
| User.PrimaryOrgId | primary_org_id |
| User.FirstName | given_name |
| User.LastNameA | family_nam |
| User.LocaleId | LocaleId/locale |
| User.DateOfBirth | birthdate |
| User.UserOrgs | user_orgs |
| User.Locations | locations |
| User.Gender | gender |
| User.Address1 | street_address |
| User.Address2 | street_address2 |
| User.City | locality |
| User.State | region |
| User.PostalCode | postal_code |
| User.Country | country |
| User.Phone | phone_number |
| User.Email2 | |
| User.UserTimeZone | zoneinfo |
| User.AvailableUserLocales | available_user_locales |
4.5.5 - Configure Azure Identity Providers
Objective
This page describes Azure Ad OIDC Setup with JIT and Non JIT Flows.
Integrating Access Management 2.0 with Azure OIDC
This section shows how to integrate Access Management 2.0 with Azure AD, where Azure will behave as an Identity Provider (IdP). The protocol used for authentication is OpenID Connect (OIDC). Steps involve creating an OIDC client on both sides.
Step 1: Identity provider in Access Management 2.0.
- Login to the Access Management 2.0 Admin console and select the correct realm, here it’s maactive.
https://mpsos-auth.sce.manh.com/auth/

If you only have Restricted Admin Access, then use the URL.
https://<stack_short_name>-auth.<domain_name>/auth/admin/maactive/console/
- Verify the Realm.

- Click Identity Providers → Add providers and select OpenID Connect provider from the list of providers.

- Enter the Alias and the Display name.
Alias also forms part of the Redirect URL. For example, if Alias is scoeoidcazure, then the redirect URI is:
https://mpsos-auth.sce.manh.com/auth/realms/maactive/broker/scoeoidcazure/endpoint
Copy this redirect URI to register the application In Azure.

Step 2: OIDC App Registration in Microsoft Azure AD
The instructions described below can be used to integrate Manhattan Active Cloud Platform with Microsoft Azure AD Login:
- Login to https://portal.azure.com/#home as an Administrator or Co-Administrator to create a new Application.
- Select App Registration from the homepage or search for the same from the search bar.

- Select New Registration to create an OIDC application.

- Set the application name, select web application from the drop-down, and paste the redirect URI that has been copied from Access Management 2.0:
https://mpsos-auth.sce.manh.com/auth/realms/maactive/broker/scoeoidcazure/endpoint
Once the redirect URI is pasted, register the application.


This creates the new application (client) in Azure Portal. Note down the client ID, which is also the application ID.

- Creation of client secret Key.
- Select the application (
scoeoidc) → select certificate and secrets to create a new secret key. - Select New client secret. Describe this secret. Hit Add.
- Select the application (

Note: Write down the Client secret value, and make sure you register the key “Value”.
This will be the only chance to capture the key. Never send the secrets over emails.

- Enable permission for this application
- Select API permissions.
- Click on Grant admin consent. Confirm in yes.

- Copy Endpoints for this client to configure in Access Management 2.0. These endpoints can be captured by clicking on Endpoints, as shown below.

Copy the OpenID Connect metadata document (also known as the OIDC Well Known URL across the Security Industry, like SAML IdP Metadata) to configure it in Access Management 2.0.
Configure the OpenID Connect application using OpenID Connect Application Endpoints in Access Management 2.0.
- Assign the users or groups to this application in Azure.
Step 3: Integrating Access Management 2.0 with Azure OIDC
- Go to Access Management 2.0 Admin Console and paste the OpenID connect metadata in the Discovery endpoint as shown below (click on show metadata to see the rest of the endpoints).

- Select Client Authentication as Client secret sent as basic auth, paste the client ID and Client secret value, then hit Add.

- Next, click on Advanced to add the default scopes as shown below.

- Next, choose the First login flow as MA first Broker login if not yet configured.
Also, choose Post login flow as MA post login flow if not configured already. This is an important step, and it is needed for the IDP login to work fine.

- Ensure users were added to the application with appropriate roles.
This completes the integration of Access Management 2.0 and Azure using the OIDC protocol.
- Click on the application URL and use the icon in the UI to log in through Azure-ODIC. A better-looking screen is expected soon. The number of IdP Login buttons/Options will depend on how many IdPs the user has configured within Access Management 2.0. In our case, it is
scoeazure-oidc.

Step 4: Enabling JWT-OIDC-JIT - Azure
In case Just In Time (JIT) User Provisioning is not needed, please skip this step 4.
If JIT needs to be enabled, we need to add six mandatory mappers on each side in Access Management 2.0, as well as Azure.
- To add mappers in Access Management 2.0, go to the Access Management 2.0 provider configuration page, select the identity providers (
Scoeazure-oidc), and click on the Mappers tab.

Click on Add mapper and create the below mappers by filling in the fields as shown in the screenshots below.
- User.UserId:

- User.FirstName:

- User.LastName:

- User.Primary_Org_Id:

- User.Roles:

- User.LocaleId:

Step 5: Adding Custom claims in Azure AD
Login to Azure portal https://portal.azure.com/#home
We have multiple options in Azure AD to pass the required claims in the response token.
Steps for Enabling Optional claim for OIDC in Azure:
- In AZURE AD, go to Token Configuration → Add optional claim ID → select preferred_username and add available required claims as well.

If we do not have options to pass the required attributes/claims in token configuration, we can pass it through managed claims.
Go to Enterprise applications →
Single Sign-on → Attributes and claims. Go to Enterprise applications and search for the application (in our case:
scoeoidc)

- Select the application and click on the Single sign-on Tab.

Edit the attributes & Claims. Click on Add new claim. Provide the Claim Name and the Source attribute value:
- primary_org_id

Similarly, add other attributes as well.

- To make these changes work and send the attributes in the ID token, we need to update the acceptMappedClaims to true in the application manifest.
Go to App registrations → <application name(scoeoidc)> → manifest.

Next, assign users to this application.
Once the above steps are performed, the user will be created in the application.
- JWT Token response using Postman.
We can check the sent claims/attributes in the JWT token response using Postman. Use the token endpoint, client ID, and client secret key to get the token response ID of the user in Postman.
POST Request:

A successful request would get HTTP 200 OK responses having an ID token and access token, as shown below.

- Go to https://jwt.io/ and paste the ID token in the debugger to know what response is sent from the token.

Step 6: JWT-OIDC-JIT Required claims in Azure.
Note: Please take special care to make sure values mapped to your Identity Provider do not have any unwanted spaces, commas, or other invalid characters before or after the values.
The attributes in the table below can be configured on both IDP and SP by following the steps above.
| Azure OIDC Claim Name |
|---|
| primary_org_id |
| given_name |
| family_nam |
| LocaleId/locale |
| birthdate |
| user_orgs |
| locations |
| gender |
| street_address |
| street_address2 |
| locality |
| region |
| postal_code |
| country |
| phone_number |
| zoneinfo |
| available_user_locales |
4.6 - Clearing IDP Assocations for Users with Access Management 2.0 API
Clearing Identity Provider Associations in Keycloak
In identity federation scenarios, users in Keycloak may be linked to external Identity Providers (IdPs) through two specific user attributes:
- BROKER_LINK: Stores the federation link between a Keycloak user and an external identity provider, capturing the IdP alias, the user’s external identity, and the associated realm details.
- FEDERATED_USER: Stores the reference to a user managed by an external storage provider, linking the user ID to its storage provider and realm.
When Is This Needed?
These associations may need to be removed for a user for a number of reasons including -
- Allow users to re-register with a different Identity Provider
- Remove obsolete or broken identity links
- Support migration between Identity Providers
API Specification: Clear Federated User Associations
This secure API endpoint may be used to clear both BROKER_LINK and FEDERATED_USER attributes for a given user, effectively removing thier federation association.
Endpoint
POST {{authurl}}/user/clearCachedUser?userId={{userId}}
Method
POST
Description
Clears the following identity federation attributes for the specified user:
BROKER_LINKFEDERATED_USER
Example Auth URL:
https://abcds-auth.sce.manh.com
Note: This endpoint must use the authentication (auth) URL, not the regular application URL.
Clear Cached User API – Expected Responses
This section describes typical response scenarios for the {{auth_url}}/user/clearCachedUser API, including success and edge cases.
Scenario 1: Successful Attribute Clearance
Scenario 2: Specified User Not Found
Scenario 3: Missing or Invalid userId Parameter
Scenario 4: Bulk Clearance Completed
Scenario 5: Access Token Validation Failed
Scenario 6: Successful Authentication
Note
Only users with one of the following roles are authorized to access this API:
- admin-maactive (SystemAdministrator / KeycloakAdministrator) — Restricted Admin
- admin — Super Admin
Any requests made with tokens that do not include one of these roles will receive an Access Denied (403 Forbidden) response.
4.7 - Handling IDP Key Rotation in AM 2.0
Objective
A signing certificate is a crucial component in securing SAML communications, ensuring that authentication requests and responses are trusted. This document provides guidance on the changes needed to Access Management 2.0 (AM 2.0) to handle a SAML signing key change on the IDP side. By completing this activity, we will maintain the integrity and security of our SAML authentication process, avoid service disruptions, and ensure a smooth, secure transition to the new certificate.
Note: In AM 1.0, a simple restart of authserver pods would fetch the latest certificate information from the IDP metadata URL and handle the change. However, this is not the case with AM 2.0.
Before you begin
You will need access to the AM 2.0 Admin Console.
Steps
Follow the steps below to incorporate the change in the SAML signing key made on the IDP side.
Log in to the AM 2.0 Admin Console. Select the maactive realm.
Note: If you have Restricted Admin Access on AM 2.0, then use the URL:
https://<stack_name>-auth.<domain_name>/auth/admin/maactive/console/The Admin Console will appear as shown below:
Now, click on the Identity providers tab on the left panel and select the IDP provider for which you would want to change the IDP signing certificate.
Scroll down in this IDP configuration. For the SP to be able to validate the signatures, you should have the Want Assertions Signed and Validate Signatures fields toggle switched ON.
Next, update the IDP certificate on the SP side. Clear out the certificate that is already present on AM 2.0 from the field Validating X509 certificates. Paste a valid X509 certificate that the SP should now start using to validate the assertions coming from IDP.
Hit the Save button at the bottom.
You should be able to successfully set a new IDP signing certificate on the SP side.
Note: No component restart is required to reflect this change.
Author
Shipra Choudhary: Tech Lead, Security, Manhattan Active® Platform, R&D.
5 - Concepts
5.1 - High Availability and Scalability
Introduction
Manhattan Active® Platform utilizes the power and flexibility of Kubernetes to ensure high availability of compute resources, services, and application components while allowing for horizontal scaling of synchronous and asynchronous workload processors to meet volume requirements. Manhattan Active® Platform is built on the principles of redundancy and concurrency, making it adaptable to inevitable compute failures, resource starvation, and application faults.
Maintaining Availability & Uptime
Manhattan Active® Platform is built with a 3-dimensional fault-tolerance design to maintain high availability and uptime of the deployed applications:
- Availability of Persistence: Database instance maintaining the transactional data is deployed as 2-instances in an active-passive HA topology, spread across two availability zones. In case of unavailability of the primary database instance, the connection automatically and transparently switches over to the secondary database instance. Likewise, other persistent services are deployed as 2+ node cluster with independent persistent volumes across availability zones.
- Availability of Compute: The Kubernetes cluster that hosts Manhattan Active® Platform runtime is deployed in multiple availability zones within a geographical region. Redundancy of compute resources and network across availability zones allows for contingency in case of potential failures or unavailability of one of the zones in the region.
- Availability of the Application: The Kubernetes
DeploymentandStatefulSetthat run the application components and system services are deployed (and auto-scale) as multiple replicas. This allows for contingency in case of potential failures or unavailability of one of the replicas of the application components or services. Moreover, system and application updates are applied using a “rolling” strategy to ensure zero downtime upgrades.
All customer environments are deployed using a standard deployment framework that follows a consistent deployment topology, with variations based on the environment designation:
- Production: regional deployments (3 zones), with database HA.
- VPT: regional deployments (3 zones), without database HA.
- Staging and Development: zonal deployments (1 zone), without database HA.
Disaster Recovery
A regional deployment of Manhattan Active® Platform stack on multiple availability-zone helps with high availability and fault-tolerance to protect against partial or full unavailability of a zone. However, a regional deployment does not protect when an entire compute region suffers a loss due to a significant outage in that region. To ensure business continuity during such events, Manhattan offers an optional disaster recovery deployment of Manhattan Active® Platform on a remote compute region located geographically away from the primary region.
When the disaster recovery option is selected, Manhattan commits to well-defined recovery objectives as part of the service level agreement of the customer contract:
- The Recovery Point Objective (RPO) is the age of files that must be recovered from backup storage for normal operations to resume if a computer, system, or network goes down because of a hardware, program, or communications failure. Manhattan Active® Platform DR Option commits to an RPO of less than or equal to 1 hour
- The Recovery Time Objective (RTO) is the targeted duration of time and a service level within which a business process must be restored after a disaster (or disruption) to avoid unacceptable consequences associated with a break in business continuity. Manhattan Active® Platform DR option commits to an RTO of less than or equal to 4 hours
The Manhattan Active® Platform disaster recovery deployment is an instance identical to the primary instance. The DR instance is deployed with minimal workload necessary to act as the “warm” data backup of the primary instance. Business data is replicated or synchronized to achieve the committed RPO and RTO agreements. In the event of a disaster, Manhattan Active® Platform Operations will the standard operating summarized described below:
- Bring up the remainder of the application components and persistent services to activate the disaster recovery instance as the primary instance.
- Rewire the application endpoints via the Cloud DNS so that the application URLs in use by the customer remain unchanged.
- Work with customers following standard service interruption protocols. The Customer Status page will be updated to reflect the DR event.
The Manhattan Active® Platform disaster recovery deployment is enabled for customers purchasing the option. The deployment is tested and audited by a certified 3rd party semi-annually as part of Manhattan’s SOC 2 compliance programs. Contact Manhattan Sales or Professional Services for more information about implementing Disaster Recovery.
The illustration below summarizes the regional (primary instance with multiple availability zones) and multi-regional (additional disaster recovery instance) deployments of Manhattan Active® Platform:

Scalability
Having the ability to increase compute capacity elastically proportional to the increasing traffic and volume is essential to maximizing the throughput and performance of software deployment. Conversely, the ability to shrink compute capacity when the volume of business workload shrinks is also key to reducing the overallocation of compute resources, costs, and the carbon footprint of the deployment. Scalability is an integral part of the core architecture of Manhattan Active® Platform, enabling optimal throughput while minimizing the total cost of ownership for Manhattan and the customers.
Container Auto-scaling
Manhattan Active® Platform relies on concurrency and disposability of its microservices architecture and the power of Kubernetes to enable horizontal scaling of the deployments. Horizontal scalability allows Manhattan Active® Platform to minimize application downtime and scale the application seamlessly, while continuously adjusting the size of the deployment to handle the spikes and drops in workloads.
Manhattan Active® Platform consists of an auto-scaling engine at the core of its architecture. The engine comprises two key components:
- Controller is the “brain” behind the auto-scaling; it continuously monitors various system metrics such as incoming traffic, processing rate, queue depths, average volume served by a specific business function, and the CPU utilization across the Kubernetes cluster. By evaluating these metrics, Controller computes the need for scaling and issues commands to Conductor to perform the scaling operation.
- Conductor is the “brawn” behind the auto-scaling; it receives commands from Controller and performs the scaling operations. Conductor manages the
DeploymentandStatefulSetof the Kubernetes cluster and invokes the Kubernetes API to update the scaling parameters of the underlying deployments. Conductor additionally performs maintenance functions such as node taints, workload movements, container reboots, and rolling updates to help with scaling and cleanup.

Horizontal scaling performed by the auto-scaling engine can be classified into two categories:
- Responsive, or Reactive scaling: Scaling performed as a response to the increasing or decreasing size of the business workload based on the real-time computations performed by Controller. Responsive scaling is important for the application to cope with bursts and slumps in the incoming volume or throughput requirements.
- Managed, or Proactive scaling: In certain cases, larger resource availability may be necessary to be in place ahead of time when there are predictable increases in incoming volume or throughput requirements. The prediction may be predictive, scheduled, or preemptive:
- Predictive scaling: The auto-scaling engine determines the future scaling needs based on the historical trend of the throughput requirements
- Scheduled scaling: A recurring definition of the scaling needs that are placed ahead of time based on prior experience
- Rules-based scaling: A decision maker defining the scaling rules ahead of time, which results in scaling commands being executed before the burst or drop in volume
Compute Auto-scaling
Conductor performs updates of the desired replica counts on the target Deployment or StatefulSet, effectively updating the number of running container Pods. When the CPU or memory requirements to run these Pods go beyond the currently available compute capacity, Kubernetes issues commands to deploy additional virtual machine nodes to the node pool. Likewise, when the CPU or memory requirements shrink, Kubernetes will accordingly adjust the node pool sizes by freeing up surplus compute capacity.
Compute scaling based on the capacity requirements is managed by Kubernetes based on configured values of minimum, desired, and maximum node counts of the underlying node pools that allocate the virtual machines (or “nodes”). As illustrated below, the node pools scale up and down proportionately to the volume trend. With increasing volumes, the node pools will add new nodes while draining the nodes when the volume decreases.

Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
5.2 - Manhattan Active® Platform Security
Introduction
Security of the customer’s data, intellectual property and business workflows is one of the highest priorities of Manhattan. Special emphasis has been put to ensure that the security aspects of communication, authentication, authorization, and access control are designed and implemented with a mindset of a security-driven software development lifecycle. Moreover, the architecture and design of Manhattan Active® Platform are continuously enhanced based on the feedback from various forms of security testing (such as static, dynamic and penetration) and reviews by InfoSec.
The topics below highlight the key design considerations of Manhattan Active® Platform security.
Deployment Security
Manhattan Active® Platform is deployed as a distributed application using Google Kubernetes Engine on Google Cloud Platform. Each customer environment is deployed as a single-tenant stack, isolated for other stacks for the customer, and other customer environments. Isolation between environments creates a two-dimensional sandbox for each environment:
- Resource isolation: Compute resources and application runtime are grouped in separate Google projects, one per customer environment. Isolation at the project level provides physical separation of processes, virtual machines, database and storage between environments, forbidding resource access across environments.
- Network isolation: Networks and the CIDR for each customer environment are unique and independent to restrict access from one environment into another. The network firewall and ACL rules for each environment forbid network-level access across environments.

The network isolation is governed using Virtual Private Cloud networks. A VPC is configured per project (and per stack) to create a “jail cell” for the resources and addressable endpoints such that their access is limited within the VPC. Manhattan Active® Platform supports two ways of inbound communication:
- HTTPS traffic: Manhattan Active® Platform exposes two HTTPS endpoints: Authentication endpoint, and Application endpoint. All inbound HTTP traffic must use TLS v1.2 or higher. The inbound HTTPS load balancer listens to port 443. The HTTPS endpoints accept traffic from Manhattan Active® Platform web user interface, mobile applications, and REST clients.
- Asynchronous traffic: All inbound messages are received via Google Pub/Sub topics, which are then processed by Manhattan Active® Platform to be placed on internal queues for subsequent message handling. Access to Google Pub/Sub is restricted using stack specific service accounts and are shared with the customers for external integration.
Additionally, Manhattan Active® Platform supports a few administrative endpoints exclusively for the use by Manhattan Active® Operations teams. The administrative endpoints are restricted and governed for access strictly by only the members of Manhattan Active® Operations team. The diagram shown below illustrates the access control measures of the Manhattan Active® Platform control-plane (administrative access) and data-plane (application access):

As an option, Manhattan also offers technology consulting service and custom options for additional network security configurations such as the options listed below. Additional network security options may be considered and supported at Manhattan’s discretion.
- Source IP whitelisting: As a default deployment, customer environments are accessible over the (public) Internet. While the HTTP traffic to Manhattan Active® Platform is always encrypted via TLS v1.2 or higher, customers may opt to whitelist source IP addresses to allow inbound traffic to Manhattan Active® Platform only from a set of known IP addresses.
- Destination IP whitelisting: Outbound traffic from Manhattan Active® Platform originates from a set of known static IP addresses. Customers may opt to whitelist these IP addresses to allow traffic from Manhattan Active® Platform into the customer network.
Communication Security
Communications to, from and within Manhattan Active® Platform is a complex ecosystem. Manhattan Active® Platform architecture ensures that all aspects of the communication system remain secure and protected from parties with potentially malicious intent. This section lists key paths of the communication security and encryption:
- All network traffic between Google Cloud Platform data centers is encrypted (TLS v1.2+)
- All inbound network traffic to Manhattan Active® Platform is encrypted (TLS v1.2+)
- All network traffic between Manhattan Active® Platform and Google Cloud services (such as Google Cloud SQL, Cloud Storage or Pub/Sub) is encrypted (TLS v1.2+)
- All outbound network traffic from Manhattan Active® Platform is encrypted (TLS v1.2+). This applies to the invocations built into the base product; there could be additional custom invocations to 3rd party systems that may not support HTTPS traffic. While customers are highly discouraged from using unencrypted traffic, such invocations are not forbidden.
Service Accounts and Security Context
Asynchronous communication to- and from- the Manhattan Active® Platform and customer’s host systems is achieved using messaging via Google Cloud Pub/Sub. To authorize the messages, and to establish an authenticated system-user context, Manhattan Active® Platform relies on Google IAM Service Accounts and Roles.
To authorize Manhattan Active® Platform to pull and post messages to Pub/Sub, a built-in Service Account is used that is instrumented in the containers via a Kubernetes Secret. This Service Account has limited access to perform Pub/Sub operations necessary for topic management and message processing.
To authorize the customer to pull and post messages to Pub/Sub, a Service Account is created per deployment and shared with the customer via secure encrypted channel. This Service Account has limited access to perform Pub/Sub operations necessary for the business use-cases of the client and with restrictions to allow access only to the Pub/Sub topics that relate to the customer. The Service Accounts shared with the customers can be recycled based on the customer’s request. Manhattan does not require a regularly scheduled recycling of the Service Account keys.
Upon receipt of an authorized message via Google Cloud Pub/Sub, Manhattan Active® Platform establishes a security context for the message using the username, organization name and tenant ID from the message header and processes the message within that context. Regardless of depth of the call stack, or the length of the chain of application components that process the message, the security context is always preserved. The context helps maintain the security and privacy of the data in the message by ensuring that the exposure of this data is limited to the processing elements pertaining to that user, organization, and tenant.
Data Encryption & Encoding
Manhattan takes customer data security very seriously and commits to rigorous compliance and protection policies for the customer data. To ensure data security and to prevent unauthorized access to data in case of a network security breach, data in Manhattan Active® Platform is encrypted in transit and at rest:
- Encryption of data in transit: As described in the Deployment Security section above, inbound HTTP and messaging traffic is accepted only over HTTPS; application endpoints of Manhattan Active® Platform and Google Pub/Sub require traffic to use TLS v1.2 or higher.
- Encryption of data at rest: Persistent volumes used by Manhattan Active® Platform services (Database, Elasticsearch and RabbitMQ) are encrypted by default. All persistent volumes offered by Google Compute Engine are encrypted out-of-the-box.
- Encryption of payment data: In addition to storage encryption, Manhattan Active® Platform also encrypts payment data (such as gift card numbers, expiration dates, payment codes etc.) using a high-strength encryption algorithm (Blowfish) supported by JDK.
- Encryption of sensitive properties: All sensitive configuration properties, such as API keys, account numbers, passwords, and access codes, are encrypted using a high-strength encryption algorithm provided by the Spring Crypto library (AES)
- Password hashing: User passwords and PINs are hashed using a high-strength hashing algorithm provided by the Spring Crypto library (BCrypt)
Application Security
As shown in the diagram below, the HTTP access to Manhattan Active® application resources is restricted to the users or system authorized to access those resources. The restrictions are controlled via user authentication, grants-driven permission control and data access. The authorization mechanism is implemented using the industry standard OAuth2 protocol and Spring Security framework.
- Manhattan Active® Platform supports Open ID or SAML for identity verification and authentication.
- The user sign-ons are SSO enabled. The OAuth2 access token obtained with the sign-in process is used throughout the session spanning across applications.
- The invocations from the mobile application are stateless (no session maintained on the server). The invocations originating from the mobile app are OAuth2 enabled.
- The invocations from the browser are stateful (a session is maintained per user sign-in on the server). The invocations originating from the browser are session ID enabled, where the access token is maintained in the server-side session.
- The access tokens are created with a predefined expiration period. The token becomes invalid when it expires.
The illustration below describes the authentication and access control flow for a user or system invoking the HTTP endpoints of Manhattan Active® Platform:

Authentication Modes
Manhattan Active® Platform standardizes authorization with OAuth2 for HTTP traffic. For identity provisioning and active directory integration, Manhattan Active® Platform supports a variety of authentication modes with Open ID and SAML:
- External Authentication Mode with Open ID is a login configuration where the user is exclusively authenticated via an external Identity Provider using Open ID as the identity protocol. In this mode, all users are maintained by the external Identity Provider.
- External Authentication Mode with SAML is a login configuration where the user is exclusively authenticated via an external Identity Provider using SAML as the identity protocol. In this mode, all users are maintained by the external Identity Provider.
- Mixed Authentication Mode with User Discovery is a login configuration where the user identity is managed either in the Native authentication source by Manhattan Active® Platform, or by an External Identity Provider with Open ID or SAML. The determination for the authentication mode for the actual user is made in real-time when the user attempts to log in, based on the user’s username. In this mode, the user is first prompted to enter their username, and the UI then redirects to the authentication mode configured for that user.
- Native Authentication Mode is a login configuration where the user is exclusively authenticated by Manhattan Active® Platform. In this mode, the user directory, and credentials (in the form of usernames and passwords) are maintained in Manhattan Active® Platform database. Users that are maintained with the native authentication mode are referred to as native users to distinguish them from the users that are maintained in the corporate directory. If no other authentication mode is configured, Native Authentication Mode is the default configuration.
Manhattan supports known Open ID and SAML Identity Providers for configuring as the External Authentication Mode. Integration with the IDPs listed below has been tested and supported:
- Microsoft Azure AD: Open ID & SAML
- ADFS: Open ID & SAML
- Okta: Open ID & SAML
- CA SiteMinder: Open ID
- Ping Identity: Open ID
- MITREid: Open ID
- KeyCloak: Open ID
- IBM Security Access Manager: SAML
Do note, that IDPs may have their nuances - not all IDPs support the full Open ID and/or SAML standards or may support additional features that are not part of the standards. In such cases, Manhattan offers technical support and consulting to accommodate the testing and validation necessary for a specific IDP to fully integrate with Manhattan Active® Platform.
User & Identity Types
Manhattan Active® Platform supports two user types for authentication:
(Human) users: The user accounts which are configured for the human users who use the application’s user interface and login via a web browser or a mobile application to access the system interactively.
- Human users cannot access API endpoints, nor can invoke the application in a non-interactive mode.
- Human users can be configured either via the Native Authentication (see the section above) or could be maintained by an external Identity Provider. Manhattan Active® Platform supports the Mixed Authentication mode, where a subset of the users (typically, temporary or non-corporate) users are maintained by the Native Authentication, while the rest of the users (typically, permanent or corporate) users are maintained by the external Identity Provider.
- Certain (configurable) password restrictions and policies apply to human users maintained by Native Authentication.
Robot users: The user accounts which are configured for system-to-system integration for non-interactive access of Manhattan Active® application.
- Robot users cannot access the browser or mobile app user interface.
- All Robot users are exclusively maintained by Native Authentication and cannot be maintained by an external Identity Provider.
- Password restrictions or policies do not apply to robot users. Their passwords can be cycled as needed, but the password cycling is not mandatory.
For more, see Auditability understand how Manhattan Active® Platform captures activities and changes that can be used for tracking, troubleshooting, forensics, and learning.
Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
5.3 - Auditability
Introduction
Manhattan Active® Platform has built-in mechanisms to track and audit user activity, HTTP traffic, extension events, and changes to application configuration. Depending on the type of the tracking and auditing data, it can be accessed and viewed by the customer via the application UI, REST API, Pub/Sub integration or data replication. The sections below summarize the tracking and auditing mechanisms:
Activity Stream
Activity Stream is a module in Manhattan Active® Platform responsible for tracking and logging all system interactions that involve the applications deployed on the platform. These interactions include:
- Inbound HTTP invocations: All HTTP calls received by Manhattan Active® Platform, including REST API invocations and traffic originating from the web UI or mobile apps.
- User Authorization requests: All requests for accessing the user’s OAuth2 access token, or reading or updating user information such as roles, grants, organization structure etc.
- Security configuration access: All requests for reading or updating security configuration such as IDP integration, Client IDs/secrets etc.
- Extension handler invocations: All events pertaining to the custom extension such as synchronous call-outs (user exits) and extension points
- Outbound HTTP invocations: All HTTP calls made by Manhattan Active® Platform, including REST API invocations made to customer’s host systems or custom 3rd party addresses
These system interactions, or “activities” are captured and published to a dedicated topic in Google Cloud Pub/Sub as messages with JSON payload in a standardized format. These messages can then be consumed via the Pub/Sub subscriptions. Customers can optionally choose to develop a Pub/Sub consumer using the authorized Service Account key delivered by Manhattan to store, index, and process the activity stream data in the system of their choice.
It should be noted that Manhattan Active® Platform does not track the user authentication when the authentication is carried out by an external identity provider such as Okta or Azure AD. The tracking and auditing events in Manhattan Active® Platform begins when it receives the request, or when it sends a request out to an external location.
The diagram shown below illustrates the basic design of Activity Stream, and the flow of the activities it captures:

Activity Stream data is used by Manhattan Reliability Engineering and ProdOps teams internally for monitoring, incident troubleshooting and change-detection purposes.
By default, the activities posted to Pub/Sub include only the message headers, and not the body of the message (meaning, the business data) due to potential privacy concerns that the customer may have. It is, however, possible to configure Activity Stream to capture the body of the messages if the customer desires to do so. If the capture configuration includes the message body, the storage and transmission costs may exceed the thresholds defined in the customer contracts, and the customer may be subjected to additional billing for the overages.
Contact Manhattan Sales or Professional Services for more information about implementing Activity Stream.
Audit Framework
Audit Framework is part of the Entity Framework library from the Manhattan Active® Platform. Audit Framework is instrumented in the application components as a runtime dependency and is responsible for capturing changes to configuration data on commit. Configuration data includes all entities that represent the metadata or settings of Manhattan Active® Platform and products that the customer may configure as part of the implementation process. While the full extent of Audit Framework functionality is out of the scope of this document, some examples of the configuration entities covered by the Audit Framework are listed below:
- Authorization and access control configuration such as Users, Organizations, Roles, Grants
- Business rules
- Business configuration such as Locations, Business Units, Stores, Schedules
- Payment configuration such as Payment Types, Parameters, Rules
- Batch job configuration such as Recurrence, Parameters, Schedules
- Custom extensions and message type configuration
Captured audit data (inserts, updates, and deletes) is indexed in Elasticsearch, and can be accessed via Audit user interface or REST API. More information about the Audit Framework can be found in the Manhattan Active® Platform product and platform documentation.
Audit data is used by Manhattan Reliability Engineering and ProdOps teams internally for monitoring, incident troubleshooting and change-detection purposes.
Change Detection
Manhattan has built a mechanism in Manhattan Active® Platform to be able to detect and capture changes that take place in the system. The Change Detection mechanism can detect several types of changes and store them in a structured way for future reference or, in some cases, for creating alerts in the system that can be investigated:
- Changes to deployment metadata and infrastructure: Container tag updates, Code Drop or Release ID changes, modification of global environment variables, sudden changes in compute allocation, etc.
- Changes to application’s properties and feature flags: Properties or feature flag configuration injected to the Spring Boot runtime and stack specific custom overrides
- Changes to application’s business configuration: Configuration that is created, updated, or deleted using the application user interface or REST API
- Changes to custom extensions & integration: Changes to custom extension or external integrations developed by the customer or Manhattan’s Professional Services staff
- Code changes between the previous and current Code Drop deploys

The Change Detection system exposes the detected changes (what changed, when, and how) in near real-time via user interface to the Manhattan Active® Operations team. While some of this information is also visible via the application’s user interface, most of it is used by Manhattan staff as part of managing the customer’s environment, and maintaining its availability.
Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
5.4 - Extensibility & Configurability
Introduction
Manhattan Active® Platform enables a comprehensive and flexible extensible model for customizing the business workflows, data models, user interface, and system behavior. Extensibility allows the Manhattan Professional Service team, and the customer to extend Manhattan Active® solutions without being impacted by (and without impacting) the base application upgrades or other maintenance activities carried out by the Manhattan Active® Operations. This document summarizes the set of extensibility methods available as part of the Manhattan Active® Platform:
Extensibility Methods
Manhattan Active® Platform supports a variety of extensibility methods as described below:

Custom Data Attributes is a mechanism in Manhattan Active® Platform for the customers to be able to introduce custom attributes as part of the base business objects. The custom data attributes can be added to virtually any base business objects. Once added, the custom attributes can be used just like the base data attributes: they can be used to create additional fields in the UI, be used for calculations in the business logic, be updated via the UI or through the REST API, or be part of the search queries, filters or business reports.
Extension Points: Manhattan Active® application components have built-in extension points for functional customizations. Call-outs to custom services can be configured at these extension points such that the custom services are invoked as part of a base workflow. The custom extension points are available throughout the base application functionality for a powerful extension model. Manhattan also evaluates the need for new extension points frequently and continues to insert them as part of application updates every few weeks. Extension points are designed to handle synchronous and asynchronous call-outs from the base flow, respectively.
User Interface Extensibility feature in Manhattan Active® Platform allows customization of the web (browser) and mobile app user interfaces by extending parts of the UI to introduce new data fields, to change the behavior of the UI functionality, or to add custom screens as part of existing UI workflows. Manhattan Active® Platform includes a built-in UI extensibility designer as part of ProActive tool-set that customers can use to extend the usability and look & feel of the UI without writing virtually any code.
REST API: Each Manhattan Active® Platform microservice publishes a REST API that handles virtually every business function and “CRUD” operations. Collectively, Manhattan Active® Platform exposes thousands of REST API endpoints which can be used as an instrument for integrating 3rd party systems with Manhattan Active® Platform. The REST API supports the same degree of access control that the Manhattan Active® Platform user interface provides. The REST API comes with Swagger documentation that outline the usage and references.
External Integration support in Manhattan Active® Platform allows customers to integrate the base application with external systems (3rd party or home-grown) in the customer’s IT landscape. The platform supports external integration for inbound and outbound traffic via HTTP (synchronous) and messaging (asynchronous) invocations. Inbound integration can be achieved either by invoking the platform REST API from an external system or by sending inbound messages via Google Cloud Pub/Sub. Likewise, Outbound integration can be instrumented by defining synchronous call-outs (user exits) to invoke external services via HTTP or by sending outbound events to external systems via Google Cloud Pub/Sub.
Business Configuration is a built-in mechanism in Manhattan Active® Platform to configure the hundreds of settings available to the customer to customize how the application behaves and operates. Business configurations can be done via the application’s user interface, or using the REST API exposed for the purpose. Examples of business configurations include:
- Authorization and access control configuration such as Users, Organizations, Roles, Grants,
- Business rules
- Business configuration such as Locations, Business Units, Stores, Schedules
- Payment configuration such as Payment Types, Parameters, Rules
- Batch job configuration such as Recurrence, Parameters, Schedules
- Message type configuration
Custom Config Store is a way to store custom configuration artifacts as part of the Manhattan Active® Platform such that they can be retrieved and referred to as part of other extensibility methods. The custom config store is also designed to handle encrypted artifacts including sensitive data such as 3rd party tokens or credentials, certificates, etc. that may need to be used for customizing the functional behavior of the application (for example, adding a new external integration to a payment system that requires an OAuth token for authorization). Data in the custom config store can be managed via its user interface, or by using its REST API. Data access of the custom config store is controlled by authorization and access control rules.
Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
5.5 - Enterprise Integration - Async vs Sync
Introduction
Manhattan Active® Platform is API-first, cloud-native, and microservices-based. All Manhattan Active® Solutions are born in the cloud, hosted on Manhattan Active Platform, and are highly available, elastic, scalable, secure, and resilient. For enterprise systems to integrate and communicate, Manhattan Active Platform provides both Synchronous and Asynchronous communication options. This document describes the integration landscape and compares options for enterprise integration with Manhattan Active® Solutions.
Integration Landscape
As depicted here, you may integrate with Manhattan Active Solutions using a variety of options. You do not need to use just one option, and can pick between them based on the use case, the nature and volume of the data being transmitted, and the amount of infrastructure you would like to manage. Some pros and cons are listed later in this document.

Note: Manhattan Integration Framework (MIF) is an optional offering. MIF is based on Software AG webMethods and is an enterprise integration tool that will help convert both inbound and outbound messages between Manhattan Active Solutions and any enterprise host system.
Synchronous REST Integration
All Manhattan Active® APIs follow the same calling mechanisms and uniformly communicate via JSON payloads. All APIs in Manhattan Active Solutions are accessed via HTTPS REST endpoints. So, an authenticated user can directly call any Manhattan Active API endpoint. With REST-based integration, feedback to the caller is immediate. However, the caller must have the necessary infrastructure to handle failures and scale calls to achieve the required throughput.
Asynchronous Queue Integration
Queue-based integration with Manhattan Active Solutions follows the same integration pattern for all interfaces. You build these asynchronous queue integrations using Google Pub/Sub and may choose from a wide range of integration options provided by Google that includes Pub/Sub APIs and a wide variety of client libraries. Once messages are posted into the dedicated Google Pub/Sub queue, Manhattan Active® Platform’s messaging infrastructure picks up and routes these messages to the target endpoints while supporting a full-featured message queue management system to manage the delivery of messages.
Note: Asynchronous Queue Integration delivers JSON messages to the same REST endpoints as Synchronous REST Integration with the added benefits of message queue management capabilities.
Integration Factors to Consider
This section provides guidance for choosing the appropriate approach for individual use cases by comparing Synchronous and Asynchronous capabilities against key integration requirements.
Scaling
Auto-scaling is the ability to automatically scale up or down to meet the fluctuations in demand for interface calls. This is a critical requirement for large-volume communication between external host systems and Manhattan Active Solutions.
| Synchronous REST Integration | Asynchronous Queue Integration |
|---|---|
| Manhattan Active Platform REST services are scaled up automatically to meet demand based on reasonable API call rates. | Message processing rates (throughputs) are benchmarked and published for key interfaces and processes. |
| Downstream systems must size and scale the number of threads to achieve a specific, required throughput. | Queue processors are scaled up and down to achieve required throughputs by dynamically adjusting to the API response times and queue depths. |
With Asynchronous Queue Integration, Manhattan Active Platform dynamically scales up and down the queue processors to meet the demands of large message inflows based on the response times of the target Manhattan Active API endpoints. It does this to account for variance in the response times stemming from the non-uniform nature of inbound payloads (for example: the save order endpoint will generally process an order with 10 lines faster than an order with 250 lines).
With Synchronous REST Integration, downstream systems will need to handle dynamic scaling by closely monitoring API response times and scaling up/down the number of threads making API calls to achieve the desired throughput. Manhattan Active Platform will automatically scale REST services based on the call rates but cannot guarantee response times due to the variability of the inbound payload. Also, note that there are appropriate guard rails in place to throttle the maximum number of calls allowed per second per API. In general, the rate limits set are higher than most reasonable business needs. Rate limits are necessary to protect the environment and maintain the overall health of the environment.
Typically, downstream systems integrating synchronously will require more infrastructure as they will need to wait for the synchronous calls to respond from the upstream system.
We recommend that if high throughput is a criterion, Asynchronous Queue Integration will typically achieve better overall throughput and require less infrastructure and management in the downstream systems.
Error Handling
Error handling is the ability to capture and handle errors. Errors can occur for various reasons, and such instances need proper handling.
| Synchronous REST Integration | Asynchronous Queue Integration |
|---|---|
| Immediate error reporting via HTTP error codes and business validations. | Detailed logs of infrastructure errors, data errors, and service errors. |
| Caller owns error handling, retries, and failure resolution. | Automatic Retries: Messages are reposted after standard intervals. |
| Failed Messages: Failures are captured and persisted for direct reposting, as well as data corrections. |
With Asynchronous Queue Integration, Manhattan Active Platform provides comprehensive error handling capabilities which allow automatic and manual resolution of errors. In the event of a message posting failure, Manhattan Active Platform automatically retries posting the message multiple times after a configurable interval. After exhausting the retry limit, the message is posted into a staged queue for remediation.
Customers have multiple options to monitor staged queues:
- Monitoring dashboard to periodically check for any error build-up.
- Purpose-built user interface to manage failed messages including capabilities to correct and repost data.
- API endpoints to programmatically manage failed messages as above.
- Capability to configure alerts based on customizable data conditions to get notified of any failures as they happen.
- Detailed logs of failures.
With Synchronous REST Integration, it is recommended that the caller captures and corrects errors, stages failed payloads and reposts payloads to continue business operations.
When immediate feedback is not a requirement, Asynchronous Queue Integration will provide better error handling and retry mechanisms. If the downstream system already has sophisticated error handling and retry mechanics, both approaches may be appropriate.
Traceability
Traceability is the ability to capture logs of service calls and the ability to debug/troubleshoot messages.
| Synchronous REST Integration | Asynchronous Queue Integration |
|---|---|
| Limited to HTTP response codes and error responses. | Detailed logs of payload and message processing status are available; can be queried on demand. |
| Caller must trace the errors and remediate them as appropriate. | Manhattan Active Platform provides visibility into message routes, hops, and payloads to show exactly what happened to a message. |
Like error handling above, traceability and audits of message inflow and status are your responsibility when Synchronous REST Integration is chosen. With Asynchronous Queue Integration, Manhattan Active Platform preserves detailed logs and payloads in addition to a full trace of errors encountered during message processing.
System Isolation
System isolation refers to the ability to independently operate one application regardless of the availability of another system to ensure systems don’t directly impact one another.
| Synchronous REST Integration | Asynchronous Queue Integration |
|---|---|
| Creates a tighter coupling between the upstream and downstream systems. | Messages in queues are automatically retried when APIs are momentarily unavailable. |
| Caller is responsible for error handling and exceptions occurring due to the unavailability of Manhattan Active APIs. | Failure management capabilities guarantee the eventual delivery of messages. |
Acknowledgement
The ability to receive a response or an acknowledgment after calling an API or posting a message.
| Synchronous REST Integration | Asynchronous Queue Integration |
|---|---|
| Immediate1 with standard HTTP response codes. | Fire and forget. Through technical configurations, Manhattan Active Platform can publish events2 as acknowledgments. |
Overall
Our experience shows that Asynchronous Queue Integrations typically provide better system isolation, error handling, traceability, and scaling whereas Synchronous REST Integration is the appropriate choice when an immediate response is needed for a business requirement.
5.6 - Asynchronous Workload Processing
Introduction
The Asynchronous Workload Processing Framework (or “AWPF” for short) is a framework instrumented in every microservice that runs as part of the Manhattan Active® Platform. AWPF enables extensibility, messaging, and batch execution within the business flows, and provides an abstract way to handle asynchronous communication between the microservices, or to- and from- the microservices and external systems. There is also a mechanism for helping components implement a basic “pipeline” – a data-defined sequence of states and corresponding services. This document covers the concepts of extension points and handlers, message types (inbound and outbound), service definitions, intermediate queues and payloads.
AWPF Features
- Simple configuration: Abstract out the configuration of queues through simple database entities
- Multi broker support: Ability to connect to multiple message brokers like - RabbitMQ, Kafka, Google Pub/Sub, Amazon SQS
- Connection and security: Manage the connectivity and security for asynchronous communication
- Failed message handling: handle retries for the failed messages and capabilities to replay the failed messages with or without data correction
- Zero message loss: Ensure zero message loss through multiple message persistence techniques
- Consolidation and De-deduplication: Ability to consolidate similar messages together and de-duplicate messages
- Scheduled delivery: Ability to schedule the delivery of a message at a particular point of time. Send now, get it delivered later
- Conditional messaging: Ability to send or suppress a message based on a MVEL condition, evaluated against the message content
- Transformation: Ability to transform message contents through freemarker and velocity templates
- Metrics and dashboards: Provide visibility through runtime metrics and intuitive dashboards
AWPF Message Types
AWPF simplifies queue configuration for every microservice that defines one or more queues. From a microservice’s perspective, it can either send a message to a queue, or receive a message from a queue. Or in the asynchronous messaging speak, a microservice can either produce a message or consume it. A microservice defines the queues it sends messages to through the OutboundMessageType configuration. Similarly, it defines the queues it receives the messages from through the InboundMessageType configuration. OutboundMessageType and InboundMessageType are defined via configuration entities in the database. Other connection details such as the messaging service (i.e., the “broker”), host names, port and credentials are abstracted from the microservice code and are configured in the database.
At a high level, the message flow between microservices or via the external system integration can be described as the following:

There are different ways a message type is mapped to an actual queue:
- The queue name directly maps to the message type name. This is the most commonly used pattern.
- Inbound and Outbound message types support defining a specific queue name if it is different from the message type name
- The queue name may carry a system property placeholder in it, which is evaluated by AWPF and replaces the placeholder to the configured property value at runtime
- A queue can also be defined with an absolute queue name by marking it is
fullyQualified.
For more detailed reference, see AWPF Message Types
Batch framework and Scheduler
Microservices may need to execute batch jobs for processing data in bulk. A batch job defines two properties: (1) what should the job do, and (2) when to execute the job. The Batch Framework enables these capabilities via configuration that a microservice can leverage to define the jobs and the execution cadence.

Batch framework features
- Simple configuration: Abstraction of complex details of a job via simple configuration mechanism
- Multiple varieties of jobs: Batch framework supports different types of jobs such as Spring-batch jobs, Service jobs, BatchV2 jobs and Agent jobs.
- Status monitoring and completion callback: When a batch job executes asynchronously, this feature helps the user visualize the progress of the job execution by tracking the messages produced by the execution. Once a job is complete, the user can receive a callback with the the execution status through the callback handler.
- Facility/BU level jobs: While the job configuration entities are defined at an organization-profile level, there is provision to configure Node/BU level jobs through job parameters.
- Heel-to-toe executions: If you want your next job execution to commence only when the previous execution goes to a completion, you can use the heel-to-toe property for a job.
- Timezone support: You can configure you job to run in a particular timezone. By default, all jobs execute in UTC timezone.
- Ad hoc job trigger: A job does not need to always be scheduled. A job can be executed without defining a recurring schedule for it by using the ad hoc job trigger.
- On-demand trigger: If there is a need to trigger an other scheduled recurring job out of turn, the on demand trigger can be used to to trigger the job, without disrupting the regular cadence of the job.
Refer to this page for the job configuration details
Scheduler features
- One-stop-shop for job related queries: Scheduler maintains a copy of all job configurations across microservices. It also maintains a record of upcoming and past executions. The Scheduler microservice provides user interface and API to collect this information.
- High availability: Scheduler ensures high availability by electing one of the
RESTstereotype instances as the primary. If the primary instance is unavailable for any reason, another instance automatically elects itself as the primary and continues triggering the jobs. - Useful REST endpoints: Scheduler provides a REST API to initialize the jobs, create future execution backlogs, etc.
- Internal housekeeping jobs: Scheduler has a few internal housekeeping jobs to help it manage the job triggers more effectively.
Refer to this page for details about scheduler component
Learn More
Authors
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
5.7 - Data Stream
Introduction
Data Stream is a sub-system of Manhattan Active® Platform that is responsible for replicating data from the production MySQL database to a configurable set of target data stores. Production data is replicated by reading the MySQL binary logs and is synced with the target (near) in real time. Data Stream is built using open-source microservices and a framework developed by Manhattan called Gravina.
Change Data Capture, or CDC, is a well-established software design pattern for a system that monitors and captures the changes in data so that other software can respond to those changes. CDC captures row-level changes to database tables and passes corresponding change events to a CDC stream. Applications can read these change event streams and access these change events in the order in which they occurred. change data capture helps to bridge traditional data stores and new cloud-native event-driven architectures.
Gravina Overview
Gravina is an internal system and framework library built by Manhattan that reads the source MySQL binary log, converts each event into a message in a CDC capturing mechanism (Kafka), and relays them to the target system in a format the target system can interpret.
Customers can implement Data Stream to replicate production data to a set of supported target systems, which, as of the writing of this document, include the following:
- Google Cloud SQL
- Certain other MySQL implementations (but not all)
Manhattan Active® Platform engineering team continues to build support for additional replication targets based on product management and customer requirements.
Gravina Architecture
Following is the summary of the Gravina microservices that enable the Data Stream functionality:
Extractor
Gravina Extractor is a Spring Boot microservice that embeds Shyiko mysql-binlog-connector-java and integrates with Apache Kafka. Extractor reads binary logs from the source MySQL database, converts each event into a message, and publishes them to Kafka. The extraction process executes as a single-threaded background job.
Kafka
Apache Kafka plays the role of CDC capture system in Gravina architecture. It is used to stream events from the Extractor into the target consumer, which is one of the supported Gravina replicator microservices. The messages in Kafka are partitioned by database entity groups into separate Kafka topics so that they can be consumed concurrently by the replicators.
Replicator
Gravina Replicator is a Spring Boot microservice that subscribes to the Kafka topics mentioned above to read the CDC events. These events are then converted to a payload format suitable for the target system. Each replicator implementation is specific to the target it serves (for example, replicator implementations for Google Cloud Pub/Sub targets and a MySQL replica on a customer’s Google Cloud SQL endpoint). As shown in the diagram above, to increase throughput, multiple instances of the replicator can be run to process CDC events from Kafka topics in parallel. Likewise, multiple types of Gravina replicators can also coexist in the same environment to transmit the replication events to different types of target systems concurrently.
Supported Replication Modes
While Gravina can technically replicate the data stream to a wide range of target stores, currently Manhattan supports the following replication modes as generally available options:
Data Save with Google Cloud SQL
Production data is replicated to a Google Cloud SQL instance owned and managed by Manhattan. The customer has private access to the database instance and a read-only authorization to query and report from this database. Manhattan remains responsible for operating, monitoring, and maintaining the database instance.

Data Stream with Google Cloud SQL
Production data is replicated to a Google Cloud SQL instance owned and managed by the customer. Manhattan will need authorization and network access to write the replication events to this database instance. The customer remains responsible for operating, monitoring, and maintaining the database instance.

Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
6 - Reference
6.1 - Manhattan Active® Apps
Integrate your Manhattan Active solution with common third party services such as tax calculations, promotions, and payment processing. Additional capabilities beyond what is available in the existing apps can be addressed by the services project team.
6.1.1 - Manhattan Active® Omni
Integrate your Manhattan Active Solution with common third party services such as tax calculations, promotions, and payment processing. Additional capabilities beyond what is available in the existing apps can be addressed by the services project team.
Please select a category from the list below for a summary of functionalities within the category. Within each category, select the third party vendor to understand what app functionalities are currently available.
Categories
6.1.1.1 - Alternate Payments
Manhattan Active Omni solutions provide clients the ability to manage the payment processing of an order paid for with alternative payment methods to traditional credit card and gift cards, such as buy now and pay later or secure digital wallets. Throughout the life cycle of each order, MAO uses the token information for the alternative payment method to process authorizations, settlements, and refunds through integration with the 3rd party payment gateway.
Manhattan Active Omni has pre-built apps with many 3rd party Alternative Payment Gateways for one or more of the above functionalities which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations




6.1.1.1.1 - Afterpay
What is Afterpay?
Afterpay is a payment processor which enables retailers to offer their customers the option to place an order now and pay in four installments with one installment due on order placement.
What does this integration include?
Manhattan Active Omni is not integrated with Afterpay out of the box. This integration enables communication with Afterpay version 2 by altering the base functionality in the following ways:
- Capture: Performs a capture (settlement) against an authorization. Multiple captures against the authorization are supported.
- Refund: Full or partial refunds.
- Void: Perform a void against an authorization. Afterpay only supports voiding the full authorization or if a payment has been partially captured then the remainder of the authorization.
- Update Shipping Courier: Updates Afterpay with a record of a fulfillment.
Capture
Manhattan Active Omni sends a capture request to Afterpay after a quantity is shipped for the shipment invoice amount. For split shipments, Manhattan Active Omni sends multiple capture requests against the single initial authorization and the order’s Afterpay transaction ID.
Refund
Manhattan Active Omni sends a refund request to Afterpay in the cases of return order creation after the entire authorization is captured as well as appeasements/adjustments created after the entire authorization is captured. Afterpay supports full or partial refunds against the order’s Afterpay transaction ID.
Void
Manhattan Active Omni sends a void request to Afterpay in the case that the order is cancelled, or the order completes with a final order total lesser than the initial order total. Afterpay only supports a full void of the remainder of an authorization, therefore the void amount is always sent for the difference between the initial and final order totals (which is $0 in the case of an order cancellation).
Update Courier
Manhattan Active Omni sends the shipping details to Afterpay as items ship using the Update Shipping Courier API, which allows Afterpay to provide better customer service.
6.1.1.1.2 - Amazon Pay
What is Amazon Pay?
Amazon Pay is an industry-leading payment solution that integrates with order creation host systems to handle payment processing for specific tenders. Amazon Pay is a commonly used online payment processing service that is owned by Amazon. Amazon Pay gives customers the option to pay with Amazon accounts on external merchant websites.
What does this integration include?
Manhattan Active Omni is not integrated with Amazon Pay out of the box. This integration enables communication with Amazon Pay using ILS Core version 6.05 by altering the base functionality in the following ways:
- Advanced Authorization
- Settlement
- Refund
- Notifications
This integration does not include Authorization or Void transactions and Amazon Pay is not an available payment tender through Manhattan Active Omni call center (imported orders only).
Advanced Authorization
MAO generates an Advanced Authorization synchronous call to Amazon Pay in the event of a split shipment. Amazon Pay accepts only one settlement record per authorization. Therefore, if a split shipment occurs and is settled in the same day, MAO obtains a new authorization for the remaining amount for that payment tender on the order.
Settlement
MAO generates synchronous settlement requests to Amazon Pay, in the Amazon Pay expected format, for open shipment invoices requiring capture. MAO is responsible for receiving the response and updating the payment transaction appropriately.
Refund
MAO generates synchronous refund requests to Amazon Pay, in the Amazon Pay expected format, for open refund invoices (for returns and appeasements) requiring capture. MAO is responsible for receiving the response and updating the payment transaction appropriately.
Notifications
In the event Amazon Pay initially sends MAO a capture or refund pending response, Amazon Pay later sends an asynchronous message containing the final transaction decision. This message is passed to MAO in JSON format, with the expectation that it is translated by a middleware. MAO is responsible for consuming the JSON message from a MAO queue and updating the payment transaction appropriately.
6.1.1.1.3 - Klarna
What is Klarna?
Klarna is a payment provider that allows customers to pay for orders in installment plans.
What does this integration include?
Manhattan Active Omni is not integrated with Klarna out of the box. This integration enables communication with Klarna by altering the base functionality in the following ways:
- Capture funds
- Refund
- Release Authorization
- Cancel
Capture
MAO generates synchronous settlement requests to Klarna, in the Klarna expected format, for open shipment invoices requiring capture. MAO is responsible for receiving the response and updating the payment transaction appropriately.
Cancel
When the order is cancelled prior to any part of it being shipped, Active Omni generates a cancellation call to Klarna.
Release Authorization
Release Authorization transactions occur anytime the remainder on the order has been cancelled after an initial capture is received. When the remaining unshipped order is cancelled, an authorization reversal transaction is generated. If this transaction amount is equal to the remaining to be paid, a void transaction is generated to Klarna to inform that this amount is no longer due by the customer.
Refund
MAO generates synchronous refund requests to Klarna in the Klarna expected format, for open refund invoices (for returns and appeasements) requiring capture. MAO is responsible for receiving the response and updating the payment transaction appropriately.
6.1.1.1.4 - PayPal
What is PayPal
PayPal is an online payment platform that facilitates payments between individuals and businesses.
Fueled by a fundamental belief that having access to financial services creates opportunity, PayPal (NASDAQ: PYPL) is committed to democratizing financial services and empowering people and businesses to join and thrive in the global economy. Our open digital payments platform gives PayPal’s 325 million active account holders the confidence to connect and transact in new and powerful ways, whether they are online, on a mobile device, in an app, or in person.
What does this integration include?
This integration enhances the current MAO out of box integration with PayPal as follows:
- To process full authorization reversals for the following scenarios:
- Cancelling an order
- Performing an order edit which results in the full or remaining authorization amount being voided. This can include cancelling an order line, applying an appeasement, reducing an order line quantity, etc.
- To process re-authorization of funds once the honor period expires but within the authorization validity period.
This integration implements additional functionality for Manhattan Active Omni (MAO) Point of Sale (POS) & ECOM / Call Center card payment flows with PayPal’s payment platform. The features include:
- POS Omni Cart Sale
- Follow On Refund
- POS Refund by Card Entry
- POS Mid Transaction Void
- POS Post Void
- POS End of Day Reconciliation
- Contact Center Hosted Checkout
- Authorization
- Re-authorization
- BOPIS Card on File
What is PayPal DoVoid?
PayPal is used as a payment method for placing an order on the retailer’s website. During the order creation, an authorization is performed by the merchant that applies a hold on the buyer’s funds which is typically valid for 29 days. PayPal allows settlement i.e., capturing less than the original authorization, full authorization amount, or even more than the authorization amount (up to 115% of the original authorization or $75 USD more, whichever is less).
However, during the order lifecycle if an order edit results in the full or partial authorized amount being voided then the funds can be released via a DoVoid call to PayPal.
MAO provides an out of box integration with PayPal using REST Service APIs for Signature and Certificate mode to process the payment transactions for Settlement and Refund. However, during scenarios when order edits result in the authorized amount being reversed to the buyers account, base MAO generates an authorization reversal transaction but does not send it to PayPal, or any Payment Gateway out of the box as a result of which the customer amount is held and unavailable for use till the authorization expires.
This feature adds the ability for MAO to send a PayPal DoVoid call to reverse (releases) complete or partial authorization amount on the buyer’s account when an authorization reversal is generated.
What is PayPal DoAuthorization?
For PayPal, an authorization places a hold on the funds and is valid for 29/90 days. After a successful authorization, PayPal recommends that you capture the funds within the honor period. Success of the capture is subject to risk and availability of funds on the authorized funding instrument.
Within the 29/90-day authorization period, a client can issue multiple re-authorizations after the honor period expires. A re-authorization generates a new authorization ID and restarts the honor period, and any subsequent capture should be performed on the new authorization ID. This feature adds logic for MAO to send the reauthorization API to PayPal.
POS OMNI-Cart Sale
This feature allows the POS application to process card present payment capture (settlement) for Pay & Carry lines and card not present payment authorization for Save the Sale lines with a single swipe of a credit card.
Follow-On Refund
Refunds are executed in MAO to process returns or negative exchanges. The Follow-on Refund, or Referenced Refund, refunds the original card that was used to execute the sale without the card being present. This applies to both POS and Call Center flows.
POS Refund by Card Entry
Refund by Card Entry, or Unreferenced Refund, refunds the card that is entered in the payment terminal via insert, tap or swipe, at the time of the transaction being executed. This flow applies only to POS not Call Center.
- Note standalone refunds by card token is not required for this App since PayPal’s transaction tokens do not expire and therefore all card not present refunds can be processed as follow-on refunds using transaction token regardless of the age of the return.
POS Mid-Transaction Void
This feature allows the store user to void or cancel a partial card payment applied to a POS transaction.
POS Post Void
This feature allows the POS application to reverse payments captured for a Pay & Carry Sale transaction that was completed and later post voided. Post Void is permitted only on the same business day as the original Sale.
POS End of Day Reconcilation
This feature allows POS to determine and record the result of an abandoned payment in order for the Cancel Order process to reverse it. Cancel Order process reverses any payments that were captured for orders that are eventually voided.
Contact Center Hosted Checkout
This feature allows the Contact Center application to capture a credit card payment method for an order which upon confirmation of the order is used to Authorize payment for that order. Card information is entered on an iframe that is hosted on the PayPal gateway and is tokenized by PayPal before returning to MAO.
Authorization
This feature allows MAO to Authorize funds for an order using a tokenized payment method. The funds authorized are to be captured upon fulfilment.
Re-Authorization
This feature allows MAO to obtain a new authorization in scenarios where a previous authorization expires before funds are captured for the same.
BOPIS Card on File
This feature allows the POS application to leverage an existing credit card payment method to complete a card not present charge for Pay & Carry orderlines added in-store to a BOPIS order upon fulfilment.
6.1.1.2 - Address Verification
Manhattan Active Omni solutions provide clients the ability to verify entered addresses across Manhattan solutions to prevent bad data and to ensure timely delivery by leveraging integration with an external Address Verification Service provider.
Manhattan Active Omni has pre-built apps with many 3rd party AVS providers which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations






6.1.1.2.1 - Avalara
What is Avalara?
Avalara is an industry-leading tax solution that integrates seamlessly with host systems to handle all tax calculation needs for eCommerce.
What does this integration include?
Manhattan Active Omni is not integrated with Avalara out of the box. This integration enables communication with Avalara by altering the base functionality in the following ways:
- Address verification request is sent in Avalara acceptable format when a user enters a shipping address in the Customer Service UI
Address Verification (AVS)
This feature adds integration with Avalara from Manhattan Active Omni to validate addresses entered in the Point of Sale and Contact Center applications. This support is provided for any address values that are entered initially or edited by the Point of Sale or Contact Center modules.
When a user adds or modifies an address in the Manhattan Active Omni Contact Center or POS, a web service call is made to Avalara AVS containing the address information captured by the UI. A response is received from Avalara AVS that indicates whether the address that was entered can be fully verified or if recommended address(es) are present as alternatives. These values, if returned, are displayed to the user in the UI for confirmation.
This feature is not extended to include other values that may be offered during verification such as email addresses or billing addresses. This feature is also not applied to orders interfaced into Manhattan Active Omni from external systems
6.1.1.2.2 - Canada Post AVS
What is Canada Post AddressComplete?
Canada Post AddressComplete Address Validation System APIs enable Manhattan Active Omni Point-Of-Sale to check a customer’s address and provide suggested alternatives when available. This helps the clients reduce operating costs and improve customer service by primarily reducing the chances of mis-shipped orders.
What does this integration include?
Manhattan Active Omni is integrated with Canada Post AVS out of the box. This integration enables communication with Canada Post AVS by altering the base functionality in the following ways:
- Address verification request is sent in Canada Post acceptable format when a user enters a shipping address in the POS Customer Capture UI
- This AVS service can be used for Customer Profile Management as well. Without any Sale order, a store user may modify a Customer’s profile to add new saved addresses or edit existing saved addresses.
- This feature is not extended to include other values that may be offered during verification such as billing addresses (AVS is also used for Billing Addresses, but in POS a billing address is pertinent ONLY to the Customer Profile). This feature is also not applied to orders interfaced into Manhattan Active Omni from external systems.
Address Verification (AVS)
When a user adds or modifies a shipping address in the Manhattan Active Omni POS for OMNI Cart Orders, a web service call is made to Canada Post containing the address information captured by the UI. A response is received from Canada Post that indicates whether the address that was entered can be fully verified or if recommended address(es) are present as alternatives. These values, if returned, are displayed to the user in the UI for confirmation.
6.1.1.2.3 - Experian QAS
What is EXPERIAN QAS?
Experian QAS is an address verification and email verification vendor who provides services to enable verification of customer shipping addresses and emails to ensure accurate data. This module provides integration with this vendor tool to augment the Manhattan Active Omni system and enable these verifications.
What does this integration include?
Manhattan Active Omni is not integrated with QAS AVS out of the box. This integration enables communication with QAS AVS by altering the base functionality in the following ways:
- Address verification request is sent in QAS acceptable format when a user enters a shipping address in the Customer Service UI or POS UI
- Email address verification request is sent in QAS acceptable format when a user enters an email address in the Customer Service UI
This feature is not extended to include other values that may be offered during verification such as billing addresses. This feature is also not applied to orders interfaced into Manhattan Active Omni from external systems.
Address Verification (AVS)
When a user adds or modifies an shipping address in the Manhattan Active Omni Contact Center or POS, a web service call is made to Experian QAS containing the address information captured by the UI. A response is received from Experian QAS that indicates whether the address that was entered can be fully verified or if recommended address(es) are present as alternatives. These values, if returned, are displayed to the user in the UI for confirmation.
Email Address Verification
When the CSR/User adds or edits email address on the customer order through Manhattan Call Center UI or through Manhattan Customer Engagement UI, a web service call is made to Experian QAS containing the email address information captured by the UI. A response is received from Experian QAS that indicates whether the email address that was entered was verified or not. If the Experian QAS system is unable to verify the email address or if it is incorrect, an error is displayed on the Manhattan UI confirming that the email address was not verified or is incorrect. User can then edit the email address or ignore and proceed
6.1.1.2.4 - Loqate
What is Loqate?
Loqate is an address verification vendor and leading specialist for location data. Their solutions provide customers with the capability to verify addresses at the point of capture via API and cleanse customer data via batch processing. The global API covers 130 address formats, 3000+ languages, and 245 countries and territories.
What does this integration include?
Manhattan Active Omni is not integrated with Loqate AVS out of the box. This integration enables communication with Loqate AVS by altering the base functionality in the following ways:
- Uses the International Batch Cleanse (v1) API within the Data Cleanse product suiteto validate shipping addresses entered initially or edited within the Call Center application
Verification for imported order addresses, billing addresses, phone numbers, and email addresses are not supported within this feature.
Delivery Address Verification (AVS)
When a user adds or modifies a shipping address in the Manhattan Active Omni Contact Center, a web service call is made to Loqate containing the address information captured by the UI. A response is received from Loqate that indicates whether the address that was entered can be fully verified or if a recommended address is present as alternative. When the Loqate cleanse API returns one or more results, the address pop-up is shown. When multiple addresses are returned in the web service response with acceptable data match scores, the Call Center user is presented with the option to select between the original address and the highest quality address match from Loqate. If the API request is not successfully processed to Loqate, or if a response is returned with an error code or an indicator that the address does not meet necessary verification standards, the AVS pop-up displays with failure message. No recommended address is provided in these failure scenarios
6.1.1.2.5 - Strikeiron
What is Strikeiron?
Strikeiron Address Verification (acquired by Informatica) is the only service that combines postal certifications in one engine from all six global postal organizations: USPS, Canada Post, La Poste in France, New Zealand Post, Australia Post, and Eircode in Ireland. It’s able to parse, analyze, verify, correct, and format addresses according to local postal standards—ensuring that correct elements appear in the appropriate hierarchical alignment. Only with the right address format can you be sure a mailing gets to its addressee.
What does this integration include?
Manhattan Active Omni is not integrated with Strikeiron AVS out of the box. This integration enables communication with Strikeiron AVS by altering the base functionality in the following ways:
- Address verification request is sent in Strikeiron acceptable format when a user enters a shipping address in the Customer Service UI
This feature is not extended to include other values that may be offered during verification such as billing addresses. This feature is also not applied to orders interfaced into Manhattan Active Omni from external systems.
Address Verification (AVS)
When a user adds or modifies an shipping address in the Manhattan Active Omni Contact Center, a web service call is made to Strikeiron containing the address information captured by the UI. A response is received from Strikeiron that indicates whether the address that was entered can be fully verified or if recommended address(es) are present as alternatives. These values, if returned, are displayed to the user in the UI for confirmation
6.1.1.2.6 - UPS
What is UPS AVS?
UPS Address Validation System APIs enable Manhattan Active Omni to check a customer’s address and provide suggested alternatives if an error is discovered. This helps the clients reduce operating costs and improve customer service by primarily reducing the chances of mis-shipped orders.
What does this integration include?
Manhattan Active Omni is not integrated with UPS AVS out of the box. This integration enables communication with UPS AVS by altering the base functionality in the following ways:
- Address verification request is sent in UPS acceptable format when a user enters a shipping address in the Customer Service UI
This feature is not extended to include other values that may be offered during verification such as billing addresses. This feature is also not applied to orders interfaced into Manhattan Active Omni from external systems.
Address Verification (AVS)
When a user adds or modifies an shipping address in the Manhattan Active Omni Contact Center, a web service call is made to UPS containing the address information captured by the UI. A response is received from UPS that indicates whether the address that was entered can be fully verified or if recommended address(es) are present as alternatives. These values, if returned, are displayed to the user in the UI for confirmation
6.1.1.3 - Credit Card Payments
Manhattan Active Omni solutions provide clients the ability to manage the payment processing of an order paid for by credit card . The card number must be tokenized where the corresponding token is stored within MAO. Throughout the life cycle of each order, MAO uses the card token to process authorizations, settlements, and refunds through integration with the 3rd party payment gateway.
Manhattan Active Omni has pre-built apps with many 3rd party Credit Card Payment Gateways for one or more of the above functionalities which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations










6.1.1.3.1 - Alliance (ADS)
What is ADS?
ADS, or ‘Alliance Data Systems’ is a provider of integrated credit and marketing services including Private Label, co-branded and commercial credit card programs.
What does this integration include?
Manhattan Active Omni is not integrated with Alliance out of the box. This integration enables communication with Alliance Private Label payment processing by altering the base functionality in the following ways:
- Authorization (XML)
- Authorization Reversal (XML)
- Refund Authorization (XML)
- Account Lookup (XML)
- End of Day Settlement File (FLAT)
- Re-send Mechanism for End of Day Settlement File (via MAO UI)
Authorization
An authorization is required to reserve funds to cover the cost of the transaction. This typically occurs during order capture. For Private Label Credit Cards, a call center agent uses the call center screens in MAO to capture the card details. This feature adds the ability for MAO to send the authorization request in the ADS required format via SOAP HTTP web service APIs and update the order based on the response from ADS.
Authorization Reversal
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. Manhattan Active Omni (MAO) creates internal authorization reversals when the order total decreases. This feature adds the ability for MAO to externalize the authorization reversal transactions when the full amount on the auth is being reversed in case of an order cancelation. MAO sends the ADS required format via SOAP HTTP web service APIs when an auth reversal is required.
Refund
A refund is generated when compensation is owed to a customer. This is typically triggered by a return, uneven exchange, or appeasement. This feature adds the ability for MAO to send the refund request in the ADS required format via SOAP HTTP web service APIs and update the order based on the response from ADS.
Account Lookup
Account Lookup provides the CSR an option to lookup a customer’s Private Label Account Number in case the customer cannot is unable to locate their account number. This feature adds the ability for MAO to send an account lookup request based on the customer’s information in the ADS required format via SOAP HTTP web service APIs and update the Account number based on the response from ADS.
End of Day Settlement Batch
A settlement occurs when the authorized funds are actually taken out of the customer’s account. This is typically triggered by a shipment or transfer of goods to the customer. This feature adds the ability for MAO to send a batch end of day settlement file to ADS.
Resend Mechanism for End of Day Settlement
With the end of day settlement performed in batch, this App also includes a UI feature to manually resend End of Day Settlement files from Manhattan Active Omni (MAO) in the event the initial files are lost in transit or incomplete.
6.1.1.3.2 - Adyen
What is Adyen?
Adyen is a global payment company that allows retail businesses to accept e-commerce, mobile, and point-of-sale payments.
What does this integration include?
For Credit Card payment processing integration, Manhattan Active Omni, MAO for short, integrates with Adyen to process payment transactions. MAO generates the transactions in the format required by Adyen and integrates via Rest APIs.
Additionally, MAO Hosted Checkout capabilities in the call center application are added, which is used to capture and tokenize credit card information via Adyen Gateway from the MAO call center application. During Hosted Checkout, Adyen responds back with the payment token which can then be used for further transactions.
This page details Manhattan Active Omni integration with Adyen Payment Gateway for the following processes:
- Hosted Checkout – Payment Method capture and tokenization using the Adyen Hosted Payment Page in the MAO Call Center
- Authorization – Payment Authorization and Reauthorization when Payment Method expiring
- Authorization Extension – Extend expiration date on Authorization
- Authorization Reversal – Reduce amount Authorized (complete or partial)
- Settlement – Capture amount fulfilled (complete or partial)
- Refund – Refund amount settled
- Fraud – Payment Method fraud review using Adyen RevenueProtect (RP)
Payment Types
Payment Types included and supported by Adyen as a part of this App are:
| Payment Type | Pre-Paid? | Refund Type | Void Behavior | Call Center? | Tokenization |
|---|---|---|---|---|---|
| Apple Pay | No | Apple Pay | No | No | Yes |
| Bancontact | Yes | Bancontact | No | No | Yes |
| Credit Card | No | Credit Card | No | Yes | Yes |
| Gift Card | No | Gift Card | No | Yes | Yes |
| iDeal | Yes | iDeal | No | No | Yes |
| Klarna | No | Klarna | No | No | Yes |
| PayPal | No | PayPal | No | No | Yes |
Processes by Payment Type
Processes by Payment Type supported by Adyen as a part of this App are:
| Payment Type | Hosted Checkout | Authorization | Authorization Extension | Auth Reversal | Settlement | Refund | Fraud |
|---|---|---|---|---|---|---|---|
| Apple Pay | No | Yes | No | Complete and Partial* | Complete and Partial* | Yes | Yes |
| Bancontact | No | No | No | No | No | Yes | Yes |
| Credit Card | Yes | Yes | Yes* | Complete and Partial* | Complete and Partial* | Yes | Yes |
| Gift Card | Yes | Yes | No | Complete and Partial* | Complete and Partial* | No | Yes |
| iDeal | No | No | No | No | No | Yes | Yes |
| Klarna | No | Yes | No | Complete Only | Complete and Partial | Yes | Yes |
| PayPal | No | Yes | No | Complete and Partial* | Complete and Partial* | Yes | Yes |
* Determined by configuration, processes leveraged can be adjusted to meet customer specific Adyen processing requirements. For example, Credit Cards can be configured to only send Complete Auth Reversals.
Hosted Checkout
Hosted checkout is a Payment Gateway / 3rd party owned screen (iFrame) used to capture payment information during the order creation/modification process in the MAO Call Center. Hosted Checkout makes the payment information capture more secure since the payment information is collected on the payment gateway side and the payment page along with the underlying security is owned by the gateway solution where MAO only invokes the Hosted Checkout page with the necessary order information. Once the payment information is submitted on the hosted checkout page, Adyen sends a token back to MAO, which is stored on the order and can be used for subsequent payment transactions – such as Authorization, Settlement and Refund.
Authorization
An authorization, or approval from the card issuer through the payment gateway, is required to ensure the customer has sufficient funds to cover the cost of the transaction. MAO creates authorizations in various scenarios such as order capture/modification through the Call Center application or when an authorization is expiring and requires a new authorization. This feature adds the ability for MAO to send an authorization request to Adyen in the required format when an authorization is required.
Authorization Extension
An authorization of a pre-authorized payment can be adjusted to extend the authorization period. This feature adds the ability for MAO to send an authorization adjustment request to Adyen in the required format when an authorization extension is required.
Authorization Reversal
An authorization reversal may occur when a merchant reverses the authorization step of the transaction for any funds that the merchant does not intend to capture. MAO creates internal authorization reversals when the order total decreases and there are unused funds on the authorization transaction. This feature adds the ability for MAO to externalize the authorization reversal transactions when the remaining amount on the auth is being reversed. MAO sends an authorization reversal request to Adyen in the required format when an auth reversal is required.
Settlement
A settlement transaction (Capture) is created when product on the order is fulfilled, so issuing bank sends funds to the seller’s payment processor, which disperses said funds to the merchant. This feature adds the ability for MAO to send a settlement request to Adyen in the required format when a payment capture is required.
Refund
A refund is required when money is owed to the consumer, triggered by a return, uneven exchange, appeasement, etc. This feature adds the ability for MAO to send a refund request to Adyen in the required format when a refund is required. Usually, a refund is issued for an existing order that is fulfilled and has invoice in Closed status. However, as a part of this App a backend API is included to process a refund without an existing order.
Fraud
Fraud is processed with Ayden RevenueProtect (RP) to provide capabilities to automate and streamline Order Reviews and Fraud Case Management operations. This feature adds the ability to support fraud check and case resolution between MAO and RP. When an order is updated in RP after being placed on fraud hold, RP provides notifications to MAO on any Fraud Status/Result changes.
6.1.1.3.3 - Arvato
What is Arvato?
Arvato is an internationally active services company that develops and implements innovative solutions for business customers from around the world. These include SCM solutions, financial services and IT services, which are continuously developed with a focus on innovations in automation and data/analytics. Globally renowned companies from a wide variety of industries – from telecommunications providers and energy providers to banks and insurance companies, e-commerce, IT and Internet providers – rely on Arvato’s portfolio of solutions. Arvato is wholly owned by Bertelsmann. The services business also includes the global customer experience company Majorel, which is listed on Euronext Amsterdam and in which Bertelsmann holds a stake of around 40 percent.
What does this integration include?
For Credit Card payment processing integration, Manhattan Active Omni, MAO for short, integrates with Arvato to process payment transactions using REST Web-Service APIs. MAO generates the transactions in the format required by Arvato.
This document details MAO integration with Arvato via the following transactions:
- Authorization / Fraud Validation
- Authorization Reversal (Cancel)
- Settlement (Capture)
- Refund
Authorization
An authorization, or approval from the card issuer through the payment gateway, is required to ensure the customer has sufficient funds to cover the cost of the transaction. Manhattan Active Omni (MAO) creates authorizations as a combo Authorization / Fraud validation call during MAO Order Creation. This feature adds the ability for MAO to send the Arvato required format when an authorization is required.
Authorization Reversal
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. MAO creates internal authorization reversals when the order total decreases. This feature adds the ability for MAO to externalize the authorization reversal transactions when the full remaining amount on the auth is being reversed. MAO sends the Arvato required format when an auth reversal is required.
Settlement
A settlement transaction is created when product on the order is fulfilled, so issuing bank sends funds to the seller’s payment processor, which disperses said funds to the merchant. This feature adds the ability for MAO to send the Arvato required format when a settlement is required.
Refund
A refund is required when compensation is owed to a customer; triggered by a return, uneven exchange, appeasement, adjustment invoice etc. This feature adds the ability for MAO to send the Arvato required format when a refund is required.
6.1.1.3.4 - Aurus
What is Aurus?
Aurus is a leading provider of global payment software and services for retailers.
What does this integration include?
For Credit Card payment processing integration, Manhattan Active Omni integrates with AurusPay Switch to process payment transactions using Web-Service AESDK version 6.13.8. MAO generates the transactions in the format required by Aurus. Additionally, MAO adds logic for Hosted Checkout in the call center application, which is used to capture credit card information via AurusPay Switch. Then, Aurus returns the payment token, which can then be used for further transactions.
This integration also adds logic to process Gift Card, Klarna, Affirm, PayPal, and Digital Wallet (ApplePay/Google Pay) payment transactions, as well as Safety Pay (Bank Transfers in Mexico) and OXXO payments.
This document details MAO integration with AurusPay Switch via the following transactions:
- Authorization (PreAuth)
- Authorization Reversal (Void)
- Settlement (PostAuth)
- Sale
- Refund
- Hosted Checkout
- Transaction Lookup
- Issue Gift Card
- Activate Gift Card
- Balance Inquiry of Gift Card
- Redeem Gift Card
- Chargeback Sale
Authorization
An authorization, or approval from the card issuer through the payment gateway, is required to ensure the customer has sufficient funds to cover the cost of the transaction. Manhattan Active Omni (MAO) creates authorizations in various scenarios like when an authorization expires and requires a new authorization. This feature adds the ability for MAO to send the Aurus required format when an authorization is required.
Authorization Reversal
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. Manhattan Active Omni (MAO) creates internal authorization reversals when the order total decreases. This feature adds the ability for MAO to externalize the authorization reversal transactions when the full remaining amount on the auth is being reversed. MAO sends the Aurus required format when an auth reversal is required.
Settlement
A settlement transaction is created when product on the order is fulfilled, so issuing bank sends funds to the seller’s payment processor, which disperses said funds to the merchant. This feature adds the ability for MAO to send the Aurus required format when a settlement is required.
Sale (Combo Call)
A sale is utilized to capture funds when base generates a settlement transaction upon adding a new payment method in the Call Center UI. This feature supports the capture of funds without requiring an authorization transaction.
Refund
A refund is required when compensation is owed to a customer; triggered by a return, uneven exchange, appeasement, adjustment invoice etc. This feature adds the ability for MAO to send the Aurus required format when a refund is required.
Hosted Checkout
Hosted checkout, or a 3rd party owned screen (iFrame) used to capture payment information during the order creation process in the Call Center application, is added as part of this feature. Aurus sends a token back to MAO, which is stored on the order and used for subsequent payment transactions.
Transaction Lookup
In scenarios where a timeout occurs when executing a payment transaction with Aurus, a lookup mechanism is required during retry to check if the transaction was processed. This features supports a lookup API call with Aurus before a new transaction is executed. If the transaction that timed out was processed by Aurus, this API returns the response details. Transaction Lookup calls are made for all the transactions listed in this extension except for the Gift Card Balance Inquiry.
Gift Card – Issuance and Activation Gift Card
For scenarios where a refund must be issued on a gift card as well as scenarios where an E-Gift Card is added to an order as a sellable item, MAO calls Aurus to issue and then activate a new E-Gift Card. The issuance/activation response, which contains the E-Gift Card number and PIN is translated by MAO into a fulfillment order event for the E-Gift Card which generates an outbound message with the E-Gift Card details.
Gift Card – Balance Inquiry
When applying a Gift Card as a payment method in the Call Center application, MAO makes a Balance Inquiry call to Aurus to confirm the card has the funds available. If the available balance is greater than the requested amount, MAO applies the gift card to the order for the requested amount. If the available balance is less than the requested amount, MAO applies the available balance. Additional payment methods are captured to continue the order creation process.
Gift Card – Redeem
When confirming an MAO Call Center order having a Gift Card applied as payment, MAO sends Aurus a Redeem request for the amount applied on the Gift Card in the Balance Inquiry step. The Gift Card Redeem transaction is modeled as a MAO Settlement transaction, and successful Gift Card redemption results in an order moving to Paid status (if the Gift Card covers the entire order total).
Pay by Link
With Pay by Link, customers can input their credit card information using their own mobile device, tablet, or laptop, rather than providing their sensitive credit card information to contact center agents. This reduces the level of risk for customers who are placing orders or making order edits over the phone.
OXXO
With OXXO payments, customers in Mexico receive a barcode on order confirmation which is saved to their mobile phones. The customer can then has 3 days to show the barcode at an OXXO store and pay for the order, at which point the OXXO payment, through Aurus, is posted to the MAO orders asynchronously. MAO executes payment cancellations for orders fully cancelled prior to payment being posted and refunds for any returns or adustments after payment has been posted.
6.1.1.3.5 - Chase
What is Chase Paymentech?
Chase is the a leading provider of merchant services with over $1 trillion in annual processing volume. Chase Paymentech is a credit card processing solution aimed at larger enterprise businesses.
What does this integration include?
For Credit Card payment processing integration, Manhattan Active Omni, MAO for short, integrates with Chase Paymentech’s Orbital Gateway to process payment transactions using SOAP Web-Service APIs on version 2.9. MAO generates the transactions in the format required by Chase Paymentech. Additionally, MAO adds logic for Hosted Checkout in the call center application, which is used to capture credit card information via Chase PaymenTech’s Orbital Gateway. Then, Chase returns the payment token, which can then be used for further transactions.
This document details MAO integration with Chase Paymentech Gateway via the following transactions:
- Authorization
- Authorization Reversal
- Settlement (Mark for Capture)
- Settlement Retry (Auth + Capture)
- Refund
- Hosted Checkout
Authorization
An authorization, or approval from the card issuer through the payment gateway, is required to ensure the customer has sufficient funds to cover the cost of the transaction. Manhattan Active Omni (MAO) creates authorizations in various scenarios like when an authorization expires and requires a new authorization. This feature adds the ability for MAO to send the Chase Paymentech required format when an authorization is required.
Authorization Reversal
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. Manhattan Active Omni (MAO) creates internal authorization reversals when the order total decreases. This feature adds the ability for MAO to externalize the authorization reversal transactions when the full remaining amount on the auth is being reversed. MAO sends the Chase Paymentech required format when an auth reversal is required.
Settlement
A settlement transaction is created when product on the order is fulfilled, so issuing bank sends funds to the seller’s payment processor, which disperses said funds to the merchant. This feature adds the ability for MAO to send the Chase Paymentech required format when a settlement is required.
Settlement Retry
In specific scenarios when the settlement call fails, it may be required to re-authorize the payment transaction in order to settlement. This feature adds the ability for MAO to send the Chase Paymentech required format for scenarios where a failed settlement needs re-processing systematically.
Refund / Standalone Refund
A refund is required when compensation is owed to a customer; triggered by a return, uneven exchange, appeasement, adjustment invoice etc. This feature adds the ability for MAO to send the Chase Paymentech required format when a refund is required.
Hosted Checkout
Hosted checkout, or a 3rd party owned screen (i frame) used to capture payment information during the order creation process in the Call Center application, is added as part of this feature. Chase Paymentech sends a token back to MAO, which is stored on the order and used for subsequent payment transactions.
6.1.1.3.6 - CyberSource
What is CyberSource?
CyberSource helped kick start the eCommerce revolution in 1994 and has not looked back since. Through global reach, modern capabilities, and commerce insights, CyberSource creates flexible, creative commerce solutions for everyday life—experiences that delight your customers and spur growth globally.
What does this integration include?
This App adds additional options to the base integration with CyberSource from Manhattan Active Omni Application for the following features:
- Authorization Reversals – Ability to release the funds on the customer’s credit card in the event the full authorization amount is no longer required
- PayPal integration via CyberSource – Ability to integrate to PayPal through CyberSource for Settlement, Refund, Reauthorization, and Authorization Reversals
- Klarna integration via CyberSource – Support for MAO to call CyberSource for Settlement, Refund, Reauthorization, and Authorization Reversal for Klarna payment method
- Bancontact integration via CyberSource – Support for MAO to call CyberSource for Refund for Bancontact payment method
- iDEAL integration via CyberSource – Support for MAO to call CyberSource for Refund for iDEAL payment method
- Przelewy24 integration via CyberSource – Support for MAO to call CyberSource for Refund against Przelewy24 payment method, and Refund Check Status call to update Pending Refund transactions to Refunded
Authorization Reversals
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. Manhattan Active Omni (MAO) creates internal authorization reversals when the order total decreases. This feature adds the ability for MAO to externalize the authorization reversal transactions when the full amount on the auth is being reversed for the credit card. MAO sends the CyberSource required format when an auth reversal is required.
PayPal Integration through CyberSource
Manhattan Active Omni (MAO) out of box integrates directly with PayPal to process settlement & refund transactions. As part of this feature, MAO integrates with CyberSource Payment Gateway to process PayPal payment transactions via the Alternative Payment PayPal Express using Simple Order API. Manhattan Active Omni sends the request to the CyberSource Payment Gateway, which acts as a middle layer and directly integrates with PayPal. This service captures all payment messages sent from MAO, passes these messages to PayPal, and returns the response to MAO. This includes settlement, refund, and full authorization reversal payment transactions.
Klarna alternative payment methods IN CyberSource
Some clients may wish to support alternative payment methods via CyberSource. This feature adds support for Klarna, a Buy Now, Pay Later solution. Manhattan Active Omni sends the request to the CyberSource Payment Gateway using the Alternative Payment Simple Order API, which acts as a middle layer and directly integrates with Klarna. This service captures all payment messages sent from MAO, passes these messages to Klarna, and returns the response to MAO. This includes settlement, refund, reauthorization, and full authorization reversal payment transactions.
Bancontact online bank transfer integration through CyberSource
Clients may wish to support Bancontact, an e-commerce payment system in Belgium that enables customers to pay for goods using direct bank transfer from their bank accounts directly to your account. MAO integrates with CyberSource Online Bank Transfers using the Simple Order API to process payment transactions. Manhattan Active Omni sends the request to the CyberSource Payment Gateway, which acts as a middle layer and directly integrates with Bancontact. This service captures all payment messages sent from MAO, passes these messages to Bancontact, and returns the response to MAO. This includes follow-on refund transactions against Bancontact payment method settlements.
iDEAL online bank transfer integration through CyberSource
Clients may wish to support iDEAL, an e-commerce payment system in the Netherlands that enables customers to pay for goods using online bank transfers from their bank accounts directly to your account. MAO integrates with CyberSource Online Bank Transfers using the Simple Order API to process payment transactions. Manhattan Active Omni sends the request to the CyberSource Payment Gateway, which acts as a middle layer and directly integrates with iDEAL. This service captures all payment messages sent from MAO, passes these messages to iDEAL, and returns the response to MAO. This includes follow-on refund transactions against iDEAL payment method settlements.
Przelewy24 online bank transfer integration through CyberSource
Clients may wish to support Przelewy24, an e-commerce payment system in Poland that enables customers to pay for goods using direct online bank transfers from their bank accounts directly to your account. MAO integrates with CyberSource Online Bank Transfers using the Simple Order API to process payment transactions. Manhattan Active Omni sends the request to the CyberSource Payment Gateway, which acts as a middle layer and directly integrates with Przelewy24. This service captures all payment messages sent from MAO, passes these messages to Przelewy24, and returns the response to MAO. This includes follow-on refund transactions against Przelewy24 payment method settlements.
6.1.1.3.7 - First Data
What is First Data?
First Data is a leading financial services company providing credit, debit, and gift card processing services. First Data Payeezy is a credit card processing solution aimed at larger enterprise businesses. First Data Rapid Connect is a credit card processing solution aimed at larger enterprise businesses.
What does this integration include?
Manhattan Active Omni utilizes custom Hosted Checkout UI to capture payment information. Manhattan Active Omni connects to the First Data Payeezy Gateway to capture credit card information. Hosted Checkout UI is controllable by configuration in the Gateway Administration and Payment Rules. When all the required fields are populated and enabled then Active Omni will point to the Hosted Checkout UI to capture payment details.
For Credit Card payment processing integration, Manhattan Active Omni will be integrating with First Data Merchant Services Rapid Connect Platform to manage credit card processing SOAP HTTP Web-Service APIs and flat file for the End of Day Settlement File. Manhattan Active Omni will generate the transactions in the format required by First Data.
This integration enables communication with First Data Rapid Connect Platform by altering the base functionality in the following ways:
- Authorization (XML)
- Authorization Reversal (XML)
- Refund Authorization (XML)
- End of Day Settlement FIle (FLAT)
Hosted Checkout
Hosted checkout, a third party owned screen (iframe) used to capture payment information during the order creation process in the Call Center application, is added as part of the feature. First Data Payeezy sends a token back to Manhattan Active Omni, which is stored on the order and used for subsequent payment transactions.
Authorization
An authorization, or approval from the card issuer through the payment gateway, is required to ensure the customer has sufficient funds to cover the cost of the transaction, Manhattan Active Omni creates authorizations in various scenarios including during order creation and when an authorization expires requiring a new authorization. This feature adds the ability for Manhattan Active Omni to send the First Data Rapid Connect required format when an authorization is required.
Authorization Reversal
An authorization reversal occurs when a merchant reverses the authorization step of the transaction, before settlement has begun. Manhattan Active Omni creates internal authorization reversals when the order total decreases. This feature adds the ability for Manhattan Active Omni to externalize the authorization reversal transactions when the full remaining amount on the auth is being reversed, Manhattan Active Omni sends the First Data Rapid Connect required format when an auth reversal is required.
Settlement
A settlement transaction is created when product on the order is fulfilled, so issuing bank sends funds to the seller’s payment processor, which disperses said funds to the merchant. Since First Data Rapid Connect processes settlements via the End of Day Settlement file, Manhattan Active Omni base logic is updated to mark settlement transactions as “In Progress” without making any API calls. Settlement transactions are closed via a custom job used to generate the End of Day Settlement file.
Refund Authorization
A refund is required when compensation is owed to a customer, triggered by a return, uneven exchange, appeasement, adjustment invoice, etc. This feature adds the ability for Manhattan Active Omni to send the First Data Rapid Connect required format to request a Refund Authorization. Since First Data Rapid Connect processes refunds via the End fo Day Settlement file, Manhattan Active Omni base logic is updated to mark refund transactions as “In Progress” without making any API calls. Refund transactions are closed via a custom job used to generate the End of Day Settlement file.
End of Day Settlement File
A custom scheduler is created to pick up any Settlement or Refund transactions that are in “In Progress” status, The necessary information is pulled from the transaction to form an entry in the End of Day Settlement file. After the entry is made in the End of Day Settlement file, the transaction is updated to “Closed” status and the next “In Progress” transaction is processed until all transactions have been closed. Once the End of Day Settlement file is complete, the file is saved and exported to First Data.
6.1.1.3.8 - Fiserv
What is Fiserv CardConnect?
CardConnect is a payments platform of Fiserv, focused on helping businesses of all sizes grow through the seamless integration of secure payment processing.
What does this integration include?
This integration enables communication for Manhattan Active Omni (MAO) Point of Sale (POS) card payment flows with Fiserv’s CardConnect platform (API version V3). Card payment types supported through this integration include Credit Cards and Debit Cards.
Integration between MAO POS and Fiserv’s CardConnect Platform is implemented using REST Web-Service APIs. Card-present payment transactions are integrated from the POS register application in the store to CardConnect’s BOLT REST APIs while Card-not-present payment transactions are integrated from the MAO Cloud Server to CardConnect’s CardPointe REST APIs.
MAO sends requests to Fiserv CardConnect in the format required by Fiserv and processes responses from Fiserv back into MAO.
This document details MAO integration with Fiserv CardConnect Gateway via the following transactions:
- Bolt
- Connect and Disconnect
- Display cart on terminal screen
- Confirm Address on terminal
- Card Payment Capture
- Refund By Card Entry
- Offline Payment Processing
- Card Payment Capture
- Card Payment Refund
- CardPointe
- Follow on Refund (referenced refund to original card by transaction token)
- Standalone Refund (unreferenced refund to original card by card token
- Void Capture
- Void Refund
Connect and Disconnect with Payment Terminal
The Bolt API Connect initiates a session between POS register and the Payment Terminal (terminal). The session key returned by the Connect API is required to be included in all subsequent API requests to the Bolt webservice. MA POS initiates the session when a transaction is created in POS and closes the session once the transaction is completed, voided or suspended. The Bolt API Disconnect is executed to close the session between the register and terminal.
Display Cart on Payment Terminal
The Bolt API Display is executed by POS to display the latest updates to the shopping cart on the payment terminal. Each time the cart is modified, such as by adding an item or overriding a price, the POS register calls the display API to update the payment terminal screen with the details of the current state of the cart.
This applies only to Fixed POS Registers where the customer typically cannot see the cart on the POS register UI. In case of Mobile POS Registers, cart is not displayed on the terminal since the user can easily share the POS UI with the customer.
Capture and Settlement
POS executes the authCard Bolt API with the Capture flag set to true to capture payment for a cash and carry transaction. This causes CardConnect to prompt for card entry (among other things) and Authorize and Capture the payment as part of a single API call.
Capture is the process of queuing a payment transaction for Settlement. Settlements are run overnight by Fiserv CardConnect at a pre-configured time agreed to with merchant. Settlement triggers the issuing bank to transfer funds to the merchant’s bank (Acquirer).
Void
A Void operation reverses a payment transaction such as a capture or refund before settlement has occurred. MAO POS executes void in a few different scenarios:
- When an order is post-voided
- When a partial card payment applied to an order is voided mid-transaction. This may be because customer changed their mind and wants to pay for the transaction with a different tender or card.
- During payment reconciliation after store close to void abandoned payments (payments with error conditions)
Refund
Refunds are executed in MAO POS to process returns or negative exchanges. Depending on the type of return different types of refunds are executed:
- Refund to original card may be executed in two ways without card being present
- If the settlement is not expired for the original payment then a refund is executed against the original payment transaction (CardPointe API Refund) – this is called a follow-on refund or a referenced refund
- If the settlement has expired for the original payment then a refund is executed using the card token from the original payment transaction (CardPointe API Authorization) – this is called a standalone refund or an unreferenced refund
- When card is present, refund is executed by card entry (insert, tap or swipe) through the Bolt API authCard with negative amount
Store and Forward (SAF)
SAF is a mechanism by which a payment can be captured with card present on the payment terminal even while the payment terminal is unable to connect to the gateway (Bolt Service). In such a scenario the payment capture is stored locally on the payment terminal until such time the payment terminal’s connection to the Bolt Service is restored. Then the payment terminal uploads all the captured payments (and refunds) to the gateway.
Display Address Confirmation on Payment Terminal
When capturing or editing a customer address on POS fixed register, this feature allows MAO to display the address on the payment terminal for confirmation by customer before it is saved. It allows the customer to specify if the displayed address is correct or not.
6.1.1.3.9 - Mercado Pago
What is Mercado Pago?
Mercado Pago is a global payment processor offering safe, simple, and convenient methods to send and receive payments on websites, social networks, and more. It is the form of collection of Mercado Libre and thousands of companies.
What does this integration include?
This feature adds integration with Mercado Pago for processing Refunds for Card and Transfer payment methods. The Mercado Pago custom integration is comprised of the following capabilities:
- Refunds: Full and Partial Refunds against completed Mercado Pago Card and Transfer transactions
- Get Refund Data: Manhattan Active Omni calls Mercado Pago at a scheduled basis to fetch the refund status and updates accordingly from In Progress.
Refund
As part of this feature, Manhattan Active Omni integrates with Mercado Pago to send Refund Transactions via the Payments API. Manhattan Active Omni sends data to Mercado Pago Payment Component that is required to generate a request to refund and transfer balance directly to buyer’s account when a refund is created against an accredited and approved Mercado Pago Card or Transfer payment transaction. Mercado Pago returns either an Error or “201 Created” Response status. “Refunded/partially_refunded” status triggers the creation of a Closed Refund Transaction in Manhattan Active Omni. If an “Error” response is returned, the Refund is created and marked as Failure or UnAvailable depending on the Refund Creation Error Code details.
Refund Lookup
In scenarios where a timeout occurs when executing a payment transaction with Mercado Pago, a lookup mechanism is required during retry to check if the transaction was processed. This feature supports an API call with Mercado Pago to get the refunds issued for a specific payment before a new transaction is executed. If the refund transaction that timed out was processed by Mercado Pago, this API returns the response details to save the transaction in Manhattan Active Omni.
6.1.1.3.10 - Webpay
What is Transbank Webpay?
Transbank Webpay is a global payment processor offering secure and innovative payment solutions, perfect for the needs of each business. These include products for face-to-face sales, e-commerce and card payment solutions.
What does this integration include?
This feature adds integration with Transbank Webpay for processing Refunds against Credit Card and Redcompra payment tenders. The Webpay custom integration is comprised of the following capabilities:
- Webpay Plus Refunds: Full and Partial Refunds against captured Webpay Plus Credit Card and Redcompra transactions
Webpay Plus – Refunds
As part of this feature, Manhattan Active Omni integrates with Transbank Webpay to send Refund Transactions via the Webpay Plus APl to Void a payment. Manhattan Active Omni sends data to Webpay Payment Component that is required to generate a request when a refund is created against a captured Webpay Plus Credit Card or Redcompra payment transaction. Webpay returns either a successful or error response code. A “0” response_code triggers the creation of a Closed Refund Transaction in Manhattan Active Omni. If an Error response is returned, the Refund is created and marked as Failure or UnAvailable depending on the Response Error Code details.
Webpay Plus – Get Transaction Status
In scenarios where a timeout occurs when executing a Refund payment transaction with Transbank, a lookup mechanism is required during retry to check if the transaction was processed. This feature supports an API call with Webpay Plus to check the transaction status of the Settlement associated to refund before a new transaction is executed. If the refund transaction that timed out was processed by Webpay Plus, this API returns the response details to save the transaction in Manhattan Active Omni.
6.1.1.4 - Customer Master
Manhattan Active Omni solutions maintain a customer entity used for storing customer information needed to track purchases and interactions with the brand. The customer entity stores:
- Basic contact information, saved addresses, and payment information to streamline customer service-assisted orders or point of sale endless aisle orders
- Customer preferences such as opt-in information and preferred store location
- Alternate IDs to cross reference customers who may have more than one account that has been merged
Manhattan Active Omni has pre-built apps with many 3rd party Customer Relationship Management providers which can be leveraged to retrieve and update customer information needed within MAO out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations

6.1.1.4.1 - Salesforce Commerce Cloud
What is Salesforce Commerce Cloud?
Salesforce Commerce Cloud is an ecommerce web platform.
What does this integration include?
Manhattan Active Omni is not integrated with Salesforce out of the box. This integration enables communication with Salesforce by altering the base functionality in the following ways:
- Search Customer
- Create Customer
These services are invoked when a new customer is created via the MAO Point of Sale or Customer Service modules.
Search Customer
This service to SFCC is invoked in POS or Customer Service modules when the user is searching for an existing customer and returns a list of customers for the user to choose from and eventually apply the customer to the order.
Create Customer
This service to SFCC is invoked when in POS or Customer Service modules when a new customer is created and returns a customer ID, which is saved on the customer record.
6.1.1.5 - Fraud
Manhattan Active Omni solutions provide clients with a framework to integrate with 3rd party fraud detection services to hold orders which are flagged as fraudulent, ensuring they are not released for fulfillment until a fraud review is performed. If an order has been put on hold due to potential fraud, then a fraud analyst can analyze the situation and take steps to resolve the alert.
Manhattan Active Omni has pre-built apps with many 3rd party fraud providers which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations
![]()


6.1.1.5.1 - Adyen
What is Adyen?
Adyen is a global payment company that allows retail businesses to accept e-commerce, mobile, and point-of-sale payments.
What does this integration include?
This page details Manhattan Active Omni integration with Adyen Payment Gateway for the following processes:
- Fraud – Payment Method fraud review using Adyen RevenueProtect (RP)
Processes by Payment Type
Processes by Payment Type supported by Adyen as a part of this App are as follows:
| Payment Type | Fraud |
|---|---|
| Apple Pay | Yes |
| Bancontact | Yes |
| Credit Card | Yes |
| Gift Card | Yes |
| iDeal | Yes |
| Klarna | Yes |
| PayPal | Yes |
Fraud
Fraud is processed with Ayden RevenueProtect (RP) to provide capabilities to automate and streamline Order Reviews and Fraud Case Management operations. This feature adds the ability to support fraud check and case resolution between MAO and RP. When an order is updated in RP after being placed on fraud hold, RP provides notifications to MAO on any Fraud Status/Result changes.
6.1.1.5.2 - ClearSale
What is ClearSale?
ClearSale is a fraud management and chargeback protection services company.
What does this integration include?
Manhattan Active Omni is not integrated with ClearSale out of the box. This integration enables communication with ClearSale by altering the base functionality in the following ways:
- Fraud Call
- Fraud Retry
- Manual Review from ClearSale
- Manual Updates in MAO
Fraud Call
For the defined order types MAO makes a call to ClearSale for fraud check before the order is released. ClearSale responds with a fraud decision - accept, failure, or review. For accept, the fraud hold is removed and the order is eligible for release. For failure, MAO cancels the order, and for review, the order is updated with a fraud review hold that requires a manual fraud review.
Fraud Retry
If no response is received from the fraud call to ClearSale, MAO has a retry scheduler to retry the fraud call on a configurable schedule.
Manual Review
If a manual fraud review is required, ClearSale sends an asynchronous message when the fraud analysts makes a final decision. MAO processes the message and updates the order with the fraud details according to the fraud response - accept or failure. The asynchronous message must be translated to the format defined as part of this integration.
Manual Update
In an exception scenario where ClearSale is unavailable for an extended period, a fraud analyst may remove a fraud hold in MAO directly given that the user has the newly added permission. Without this permission, the user is prevented from editing orders on a fraud hold or removing the fraud specific holds from the order.
6.1.1.5.3 - CyberSource
What is Decision Manager?
CyberSource’s Decision Manager is a fraud protection platform, which features a flexible rules engine. Decision Manager allows customers to screen orders for risk to help prevent fraud.
What does this integration include?
This integration extends the base-supported authorization integration with CyberSource by utilizing three methods:
- Combo Call (Adding Fraud fields to Authorization Call)
- Review Fraud Status Calls
- Stand Alone Fraud Calls
The Decision Manger API allows for integration between Manhattan Active Omni and CyberSource’s Decision Manager. The integration with Decision Manager (DM) provides the client capabilities to automate and streamline Order Reviews and Fraud Management operations.
Combo Call
For orders placed in the MAO Customer Servic emodule, a call to CyberSource for authorization is made with the additional fields added for CyberSource to perform the fraud check before the order is released. CyberSource responds with a fraud decision - accept, failure, or review. For accept, the fraud hold is removedand the order is eligible for release. For failure, MAO cancels the order, and for review, the order is updated with a fraud review hold that requires a manual fraud review.
Review Status Call
MAO periodically checks the fraud status of any order that is in Fraud Review with CyberSource DM. This task utilizesthe DM API to check the status of the order and allows MAO to process any updates based on manual review of the order.
Standalone Calls
For order edits where no new authorization is required, MAO sends a standalone fraud call to CyberSource DM and updates the order based on the fraud response.
6.1.1.5.4 - Signifyd
What is SIGNIFYD?
Signifyd is a software as a service fraud and chargeback prevention technology. Signifyd’s technology helps detect and prevent fraud.
What does this integration include?
Manhattan Active Omni is not integrated with Signifyd out of the box. This integration enables communication with Signifyd by altering the base functionality in the following ways:
- Ability to perform Fraud Check for orders created via Active Omni Call Center Application and order modifications done during the remorse period
- Fraud Retry
- Manual Fraud Review
- Manual Fraud Update
Fraud Check
For the defined order types MAO makes a call to Signifyd for fraud check before the order is released. Signifyd responds with a fraud decision – accept, failure, or review. For accept, the fraud hold is removed and the order is eligible for release. For failure, MAO cancels the order, and for review, the order is updated with a fraud review hold that requires a manual fraud review.
Fraud Retry
If no response is received from the fraud call to Signifyd, MAO has a retry scheduler to retry the fraud call on a configurable schedule.
Manual Review
If a manual fraud review is required, Signifyd sends an asynchronous message when the fraud analysts makes a final decision. MAO processes the message and updates the order with the fraud details according to the fraud response – accept or failure. The asynchronous message must be translated to the format defined as part of this integration.
Manual Update
In an exception scenario where Signifyd is unavailable for an extended period, a fraud analyst may remove a fraud hold in MAO directly given that the user has the newly added permission. Without this permission, the user is prevented from editing orders on a fraud hold or removing the fraud specific holds from the order.
6.1.1.6 - Gift Cards
Manhattan Active Omni solutions provide clients the ability to sell or to transact with gift cards.
Selling gift cards
Physical or electronic gift cards may be purchased through the website, Contact Center, or POS, which leverages integration with the external gift card provider to activate the gift card.
Transacting with gift cards
Gift card as a tender is supported with integration to the external gift card provider to process the payment. This includes:
- Balance check to verify available funds prior to accepting as form of payment
- Reducing the funds on the gift card upon fulfillment
- Refunds to existing or new gift card upon cancelation or returns
Manhattan Active Omni Point of Sale provides additional capabilities for store users to perform balance inquiries, reload or activate a gift card, and cash out remaining balance under a defined threshold.
Manhattan Active Omni has pre-built apps with many 3rd party gift card providers which can be leveraged out of the box for one or more of the above functionalities. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations








6.1.1.6.1 - Clutch
What is Clutch?
Clutch is an innovative data-centric marketing solution platform empowering brands with the best technology so that they can identify, understand, and motivate their customers. Clutch provides traditional marketing CRM, loyalty, gift card, mobile, email, and direct mail solutions individually or as part of a unified platform.
What does this integration include?
This Clutch integration enables Manhattan Active to support the following features:
- Balance Check – Check the available balance on a Gift Card
- Hold – Place a hold on the funds on a Gift Card to pay for an order
- Redeem – Redeem the held funds on a Gift Card upon the fulfillment of the order that was paid using the gift card
- Hold Reversal – Release funds that are held on a Gift Card
- Gift Card Processing – Activation and Issuance of Physical and Electronic Gift Cards
Balance Check
When a CSR adds a gift card to an order in the Call Center UI, Manhattan Active Omni generates a payment transaction to determine the available funds on the card. MAO makes a synchronous call to Clutch and sends only one message per gift card. If the available balance is greater than the requested amount, Manhattan Active Omni applies the gift card to the order for the requested amount. If the available balance is less than the requested amount, Manhattan Active Omni applies the available balance. Additional payment methods are captured to continue the order creation process.
Hold
In the Call Center UI, when a CSR places an order requiring a gift card tender authorization, MAO sends an authorization/hold transaction to place a hold on the funds to Clutch. If the approved amount is less than the requested amount, then MAO accepts the response to make the appropriate updates. The correct available, applied, and remaining amounts are displayed in the payment tab of the Call Center UI.
Redeem
A settlement request to Clutch is sent to redeem gift card payment transactions. When an order is shipped, an invoice is generated to mark the sale of goods. If an order is fully shipped, MAO uses the invoice to generate a settlement transaction. If the order is partially shipped, a scheduled job is configured to batch process any open settlement transactions, generating individual calls for each open transaction to Clutch. The redeem transaction releases the remaining funds from the related hold transaction. If all order lines are not shipped, Manhattan Active Omni generates an advanced hold transaction upon a successful response. The advanced hold record is used for any subsequent settlement transactions, until a new hold is generated, or the order is fully shipped or canceled.
Hold Reversal
Manhattan Active Omni uses the authorization reversal interface when an authorization reversal transaction is generated for a gift card authorization. The message interfaced to Clutch is like the settlement request, however, the requested amount is always $0. MAO closes the authorization record and releases the funds for the related hold in Clutch.
Gift Card Processing
When a customer purchases a Gift Card both Electronic / Physical, there are a series of steps involved in fulfilling and activating the Gift Card for the customer to Use. Manhattan Active Omni orchestrates the fulfillment of both the Physical and Electronic Cards and handles the activation of the same.
When a Gift Card order is Released to Fulfillment based on the type of Gift Card the following steps are performed
Allocate
Only applicable for Electronic Gift Card, when an Electronic Gift Card is released MAO makes an Allocate call to Clutch using the CardsetID, which returns the Gift Card Number and optional PIN.
Activate
A Gift Card Activation request to Clutch is generated when the fulfillment center ships the physical gift card. For electronic gift card, the call is generated after a successful Allocate call. This message includes the Gift Card Number and Pin, if available.
Issuance
For both types of gift cards, once the gift card is activated, a Gift Card Issuance request to Clutch is generated to issue the value to the card . MAO makes a synchronous call to Clutch and sends one message per gift card. If multiple gift card issuances are required, multiple messages are sent.
6.1.1.6.2 - Eigen
What is Eigen?
Eigen is a payment management service that can be used for Gift Card issuing and management.
What does this integration include?
This Eigen integration enables Manhattan Active to support the following features:
- Issuing a New E-Gift Card on Refund
- Retry Scheduler for Failed E-Gift Card Issuance
Issueing a New E-Gift Card on Refund
After customers make purchases using a gift card, they generally discard the gift card. Therefore, when a refund or appeasement is processed for the customer, the funds are not put back on the original gift card. If the payment method on the original order is a gift card and a refund transaction is created, a new electronic gift card is issued. In addition, new gift cards are issued as a refund tender when gift recipients return items. For example, if a customer purchases an item as a gift and pays using a credit card, and the gift recipient returns the item, the refund is also issued as a new gift card.
Failed E-Gift Card Retry Scheduler
When the call to Eigen to activate and issue a new E-Gift Card fails with an unavailable response, MAO retries the call to Eigen on a configurable schedule up to the max retry attempts.
6.1.1.6.3 - Givex
What is Givex?
Givex offers gift card, loyalty and stored value ticketing solutions which drive sales for clients, help them better understand, reward and entice their customers and ultimately make better-informed business decisions.
What does this integration include?
This integration enables integration to Givex for two Payment Methods:
- Gift Card (GC)
- Store Card (SC)
In the context of this integration a Store Card is essentially a Gift Card except it must be redeemed within the store only and not through other channels. This is managed in Givex by assigning a Gift Card to a Group. By the virtue of the card being associated to the group it is limited to be redeemed only from stores. The details of the mechanisms / configurations by which this is accomplished is outside the scope of this document and is managed between the Retailer and Givex.
The features within this integration explained more below include: • Card Entry • Redemption • Cash Out • Refund • Balance Inquiry • Activation • Reload • Exchange Tender
Card Entry
This feature provides the ability for the customer to barcode scan a Gift Card or Store Card into the Manhattan Active Omni POS UI. This feature requires integration with a barcode scanner to be implemented outside the scope of this integration.
Redemption
Redeeming is the process of using a Gift Card or Store Card to pay for a purchase in the Manhattan Active Omni POS Application. Funds equal to the redemption amount is reduced from the available funds on the card following a successful redemption.
Cash Out
Immediately following a redemption, if the balance remaining on the card (GC or SC) is below a threshold value (configured in MAO) then customer has the option to cash out the remaining balance in Manhattan Active Omni POS Application. This function is used to redeem (Forced Cashback Redemption) the remaining amount on the Gift Card or Store Card.
Refund
Refund results from processing a return or a negative exchange where customer is issued funds to an existing or new card (Gift Card or Store Card).
Balance Inquiry
Balance Inquiry is a function in the Manhattan Active Omni POS Application that allows the user to query the balance of an existing Gift Card or Store Card.
Activation
Activation is the process of adding funds to a new gift card and making it available to be redeemed. In the Manhattan Active Omni POS application activation is performed once the balance due becomes zero, for an order that contains a Gift Card line item. Note activation is supported only for Gift Cards and not for Store Cards since Store Cards are not sold as line items.
Reload
Reloading is the process of adding funds to an existing card (an activated card that the customer already owns). This process does not require activation since the card is already activated, it simply adds more funds to the card.
Exchange Tender
This function is utilized to return cash to a customer for a Gift Card or Store Card that they own. Alternately this function may also be utilized if a customer has multiple Gift Cards (or Store Cards) and wants to consolidate the funds in those cards to a single card
6.1.1.6.4 - SmartClixx
What is SmartClixx?
SmartClixx is a gift card provider and payment gateway used to issue, charge against, check balances, and other miscellaneous gift card transactions.
What does this integration include?
This SmartClixx integration enables Manhattan Active to support the following features:
- Physical Gift Card activation
- Electronic Gift Card activation
- Settlement (Capture) of Gift Card Funds
- Authorization Reversal of Gift Card Funds
Physical Gift Card Activation
When physical gift cards are added to the order, they are fulfilled by a fulfillment center who scans the card during picking to add the serial number (card number) to the order. This information is passed back to Active Omni on the Order Event (ship confirmation) message. An interface is used to relay the Gift Card Activation request to SmartClixx in the required format. The MAO generates the activation call, consumes the response, and passes the order event message along to mark the physical gift card as shipped.
Electronic Gift Card Activation
When electronic gift cards are added to the order, they are fulfilled virtually through integration with SmartClixx. Active Omni sends a request to SmartClixx to retrieve a card number and CVV2 value from SmartClixx. This information is passed back to Active Omni in the response and used to generate the next call, Activate, to load value to the card. Once the response is received back, the App forms an Order Event message that completes the lifecycle of the order line(s) with the card number and CVV2 value included.
Gift Card Settlement
When parts of the order ship, Active Omni reaches out to SmartClixx to inform them that the gift card has less funds available. Each shipment that occurs results in an individual settlement (capture) transaction reaching out to SmartClixx, further reducing the available funds remaining on the gift card.
Authorization Reversal
When an order is canceled or partially canceled, SmartClixx expects an authorization reversal transaction initiated from Active Omni to release the funds. Active Omni calls SmartClixx on a scheduled basis to perform authorization reversal to remove the hold on the gift card funds.
6.1.1.6.5 - SVS
What is SVS?
SVS (Stored Value Solutions) is a global provider of gift card and stored value services.
What does this integration include?
This SVS integration enables Manhattan Active to support the following features: • Balance Check • Pre-Authorization (Authorization) • Pre-Authorization Complete (Settlement) • Pre-Authorization Complete $0 (Authorization Reversal) • Issue Virtual Gift Card • Activate Physical Gift Card
Balance Check
When a CSR adds a gift card to an order in the Call Center UI, Manhattan Active Omni generates a payment transaction to determine the available funds on the card. MAO makes a synchronous call to SVS and sends only one message per gift card. If the available balance is greater than the requested amount, Manhattan Active Omni applies the gift card to the order for the requested amount. If the available balance is less than the requested amount, Manhattan Active Omni applies the available balance. Additional payment methods are captured to continue the order creation process.
Pre-Authorization (Authorization)
In the Call Center UI, when a CSR places an order requiring a gift card tender authorization, MAO sends an authorization/hold transaction to place a hold on the funds to SVS. If the approved amount is less than the requested amount, then MAO accepts the response to make the appropriate updates. The correct available, applied, and remaining amounts are displayed in the payment tab of the Call Center UI.
Pre-Authorization Complete (Settlement)
A Pre-Authorization Complete (settlement) request to SVS is sent to redeem gift card payment transactions. When an order is shipped, an invoice is generated to mark the sale of goods. If an order is fully shipped, MAO uses the invoice to generate a settlement transaction. If the order is partially shipped, a scheduled job is configured to batch process any open settlement transactions, generating individual calls for each open transaction to SVS. The Pre-Authorization Complete transaction releases the remaining funds from the related hold transaction. If all order lines are not shipped, Manhattan Active Omni generates an advanced hold transaction upon a successful response. The advanced hold record is used for any subsequent settlement transactions, until a new hold is generated, or the order is fully shipped or canceled.
Pre-Authorization Complete $0 (Authorization Reversal)
Manhattan Active Omni uses the authorization reversal interface when an authorization reversal transaction is generated for a gift card authorization. The message interfaced to SVS is like the settlement request, however, the requested amount is always $0. MAO closes the authorization record and releases the funds for the related hold in SVS.
Issue Virtual Gift Card
MAO issues a new Electronic Gift Card for many refund scenarios. MAO utilizes the release of the Electronic Gift Card item to trigger the custom activation calls for Electronic Gift Card. This synchronous call to SVS receives either a successful, failure, or unavailable response from SVS. MAO updates orders to shipped for successful scenarios. MAO also handles scenarios in which SVS is unavailable and resends the request based on the number of retries available.
Activate Physical Gift Card
MAO activates a Physical Gift Card upon receiving the ship event from the fulfillment center. MAO utilizes the Gift Card Number and optional PIN on the ship event to send the custom activation call for Physical Gift Cards. This synchronous call to SVS receives either a successful, failure, or unavailable response from SVS. MAO updates orders to shipped for successful scenarios. MAO also handles scenarios in which SVS is unavailable and resends the request based on the number of retries available.
6.1.1.6.6 - ValueLink (First Data)
What is ValueLink?
First Data, now Fiserv, is a global leader in payments and financial technology, where ValueLink is their proprietary gift card solution.
What does this integration include?
This ValueLink integration enables Manhattan Active to support the following features:
- Physical Gift Card Activation
- Electronic Gift Card Activation
- Balance Inquiry
- Redemption
Physcial Gift Card Activation
When physical gift cards are added to the order, they are fulfilled by a fulfillment center who scans the card during picking to add the serial number (card number) to the order. This information is passed back to Active Omni on the Order Event (ship confirmation) message.
An interface is used to relay the Gift Card Activation request to ValueLink in the required format. The MAO generates the activation call, consumes the response, and passes the order event message along to mark the physical gift card as shipped.
Electronic Gift Card Activiation
When electronic gift cards are added to the order, they are fulfilled virtually through integration with ValueLink. MAO sends a Gift Card Activation request to ValueLink in the required format, consumes the response, and passes the order event message along to mark the electronic gift card as shipped.
Balance Inquiry
When a CSR adds a gift card to an order in the Call Center UI, Manhattan Active Omni generates a payment transaction to determine the available funds on the card. MAO makes a synchronous call and sends only one message per gift card. If the available balance is greater than the requested amount, Manhattan Active Omni applies the gift card to the order for the requested amount. If the available balance is less than the requested amount, Manhattan Active Omni applies the available balance. Additional payment methods are captured to continue the order creation process.
Redemption
When the order is shipped or partially shipped, the MAO reaches out to ValueLink to inform them that the gift card has less funds available. Each shipment that occurs results in an individual settlement (capture) transaction reaching out to ValueLink, further reducing the available funds remaining on the gift card.
6.1.1.6.7 - Voucher Express
What is Voucher Express?
Voucher Express is an industry-leading e-commerce solution that manages the online sale of gift vouchers, gift cards, and electronic gift cards.
What does this integration include?
This Voucher Express integration enables Manhattan Active to support the following features:
- Refund – Issue a refund against a new electronic gift card
Refund
After customers make purchases using a gift card, they generally discard the gift card. Therefore, when a refund or appeasement is processed for the customer, the funds are not put back on the original gift card. If the payment method on the original order is a gift card and a refund transaction is created, a new electronic gift card is issued. In addition, new gift cards are issued as a refund tender when gift recipients return items. For example, if a customer purchases an item as a gift and pays using a credit card, and the gift recipient returns the item, the refund is also issued as a new gift card.
6.1.1.6.8 - Worldpay
What is Worldpay?
Worldpay is the world’s largest processor and payments advocate and provides services to merchants and financial institutions in the US.
Worldpay provides tools to simplify payment strategies including credit cards, ATM processing, and merchant services as part of a unified platform.
WHAT DOES THIS INCLUDE?
This feature adds integration with Worldpay for Gift Card processing including the following capabilities:
- Giftcard Reload Transaction: Loading the funds onto an active gift card (for Physical Gift Cards) on Fulfillment of Purchased Gift Card and Refund Gift Card
Reload Gift Card
As part of this feature, MAO integrates with Worldpay to send Gift Card Reload Transactions via the Native RAFT API. Manhattan Active Omni sends data to Worldpay Payment Component that is required to generate request to load funds onto Physical Gift Cards. This service captures Order Event data from MAO for pGC shipments and generates and transmits request to Worldpay and returns the response to MAO.
6.1.1.7 - Parcel Carrier
Manhattan Active Omni solutions provide clients the ability to integrate with external parcel carriers for label generation and package tracking visibility. Use cases include:
- Generation of shipping labels if leveraging stores as fulfillment centers for orders (ship from store)
- Generation of return labels to include proactively in customer shipments from stores
- Real time tracking services for shipments executed in MAO or for interfaced shipments from fulfillment locations
Manhattan Active Omni has pre-built apps with many 3rd party Parcel Carriers for one or more of the above functionalities, which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
6.1.1.7.1 - Blue Express
What is Blue Express?
Blue Express provides door-to-door service to distribute products to more than 300 cities throughout Chile in an agile and safe way. The Blue Express shipping network provides national and international distribution, retail distribution, home delivery and commercial deliveries.
What does this integration include?
This integration adds functionality for Manhattan Active Omni to call Blue Express Tracking Pull web service, specifically the obtainDocument Service Method (Método obtenerDocumento). This provides the capacbility to track shipments within Manhattan Active Omni Digital Self Service (DSS) when a customer tracks a package associated to a Blue Express service order (OS).
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. One Shipment Tracking page is displayed per package.
The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier such as FedEx to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS.
This feature provides additional integration for 3rd party carrier, Blue Express. When a user accesses the Shipment Tracking UI for a package shipped via Blue Express, a real time call is made to the Blue Express obtainDocument web service to retrieve the latest status of the package as well as the tracking history using the Blue Express service order (OS) as tracking number.
6.1.1.7.2 - Canada Post
What is CANADA POST?
Canada Post is a carrier that acts as the primary postal operator in Canada.
What does this integration include?
Manhattan Active Omni is not integrated with Canada Post out of the box. This integration enables communication with Canada Post by altering the base functionality in the following ways:
- Call Center Return Label
- Store fulfillment Shipping & Return Label
- Tracking
- Void Shipment
Call Center Return Label
When a user initiates a return in Manhattan’s Contact Center the customer needs a return shipping label to ship their items to the return center. When a return order with receipt expected is initiated and confirmed in EOM, a call is made to the carrier to create and retrieve a return shipping label as well as generate a tracking number. Upon a successful response from Canada Post, the return label is stored within the EOM Document Component, and the return tracking number is saved against the order. Each return label contains the customer’s address, return center address, return order id and return tracking number. Canada Post requires that two calls be made to obtain a return tracking number: Create Authorized Return and Get Artifact.
Shipping and Return Label
When a user completes a package in Manhattan’s Store Fulfillment module, a ship request is generated, which communicates the service level, ship from and ship to address and other relevant package information. This ship request is generated to the required format for the two calls to Canada Post to get the tracking number and shipping label. The Canada Post response is translated back to the Store Fulfillment format where the tracking number is saved against the package, and the 4 X 6 PNG shipping label is saved in the document repository to be printed with the pack slip.
Additionally, based on configuration, a return label will be generated to be sent to the customer along with the shipping label. This will be two separate calls to Canada Post that will happen simultaneously to the calls made for the shipping label if configured to do so. The Canada Post response is translated back to the Store Fulfillment format where the return tracking number is saved against the package and the 4 X 6 PNG return label is saved inn the document repository to be printed with the pack slip.
Tracking Request
Once a package is built and has a tracking number for the Create Shipment response, a batch job scheduler runs periodically and pings Canada Post with this information. The frequency of this scheduler is configurable as a cron expression. The status code from the Canada Post Get Tracking response is mapped back to the payload. If the status code indicates possession from the carrier, it is configured with the status “InTransit” and the OMNI Fulfillment API updates the package to “Shipped” status. If any packages have not updated to an in-transit status, the package status remains in “Built”. Any packages that remain in “Built” status should be included in the subsequent requests triggered by the job scheduler.
Void Shipment
Store associates might need to print a new label for a package that was already prepared in store. In that case, they can use the ‘Reprint’ menu in the store application where they have the option to either reprint the label that was already printed or to update the Carrier details before submitting a new call to Canada Post to generate a new label. In the event where they decide to update the Carrier details and print a new label, a Void Shipment call is made to Canada Post to void the previous label.
6.1.1.7.3 - CanPar
What is CanPar?
anPar is a major transportation company in Canada. Serving customers coast-to-coast for over 40 years, Canpar Express is one of Canada’s leading small parcel delivery companies and offers dependable Ground, Select, and Express service across the country.
What does this integration include?
This feature adds integration with CanPar REST Transport-Orders APIs, specifically the Shipment Tracking APIs. These integrations provide the ability to track shipments within Manhattan Active Omni Digital Self Service.
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, CanPar. When a user accesses the Shipment Tracking UI for a package shipped via CanPar, a real time call is made to the CanPar Individual Shipping Consultation API to retrieve the latest status of the package as well as the tracking history.
6.1.1.7.4 - Channel Advisor
What is Channel Advisor?
Channel Advisor is a provider of cloud-based solutions to e-commerce companies. Channel Advisor helps global brands and retailers solve their marketplaces, digital marketing, direct-to-consumer, first-party retail, drop ship and fulfillment needs — all in a single, centralized platform.
What does this integration include?
Manhattan Active Omni is not integrated with Channel Advisor out of the box. This integration enables communication with Channel Advisor by altering the base functionality in the following ways:
- Shipping Labels from SOF
Shipping Labels
During fulfillment from the SOF (Store Order Fulfillment) system, the Manhattan Active Omni system evaluates the carrier required for fulfillment. After a package has been created and closed, a call is made to a carrier to receive the appropriate tracking information and label. This integration allows for carrier configuration to determine when Channel Advisor calls should be executed versus other carriers (such as FedEx, UPS, etc.).
6.1.1.7.5 - Chilexpress
What is Chilexpress?
Chilexpress is the leading Chilean private company in the courier market and in express shipping services. Chilexpress provides clients with express distribution services, logistics transport and international trade, as well as money transfers, collections and electronic commerce.
What does this integration include?
Manhattan Active Omni is not integrated with Chilexpress out of the box. This integration enables communication with Chilexpress using the REST Transport APIs by altering the base functionality in the following ways:
- Shipment Tracking
- Self-Service and Call Center Return Labels
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, Chilexpress. When a user accesses the Shipment Tracking UI for a package shipped via Chilexpress, a real time call is made to the Chilexpress Individual Shipping Consultation API to retrieve the latest status of the package as well as the tracking history.
Self-Service and Call Center Return Labels
Retailers may provide the ability to create returns and same-style exchanges via DSS. Customers can initiate the self-service exchange flow in a few different ways. One is via the link provided in the shipment confirmation email. Another is if the retailer provides a link to return in the customer’s My Account page in e-commerce. A third way to initiate the flow is if the retailer offers a link in e-commerce to initiate returns, even for customers who are not logged in.
Customers can select items to return or exchange, quantity to return, and reason for return. After confirming the return, the customer is emailed a return label. The customer can also download a copy of the return shipping label and use it to ship the return items back. Customers can view and print the return label by using built-in browser functionalities to save or print the return label. In case the return label cannot be created or retrieved, an appropriate error message is displayed to the customer so that they can reach out to the contact center for help.
Base Return label generation is supported for FedEx, UPS, and USPS (the same carriers which are supported in customer service). This feature enables DSS Self-Service returns using Chilexpress as Return Carrier. If the Return Shipping Method is tied to a Chilexpress Carrier Service, upon confirming the DSS return, the Chilexpress App is invoked to generate a return label using the Generate Shipment API.
6.1.1.7.6 - Coordinadora
What is Coordinadora?
Coordinadora is a leading Colombian logistics company. Coordinadora provides clients with express distribution services and logistics transport.
What does this integration include?
This feature adds integration with Coordinadora SOAP APIs, specifically the Return Label and Shipment Tracking APIs. These integrations provide the ability to track shipments and create self-service returns within Manhattan Active Omni Digital Self Service.
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g., in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, Coordinadora. When a user accesses the Shipment Tracking UI for a package shipped via Coordinadora, a real time call is made to the Coordinadora “Seguimiento Detallado” API to retrieve the latest status of the package as well as the tracking history.
Self-Service and Call Center Return Labels
Retailers may provide the ability to create returns and same-style exchanges via DSS. Customers can initiate the self-service exchange flow in a few different ways. One is via the link provided in the shipment confirmation email. Another is if the retailer provides a link to return in the customer’s My Account page in e-commerce. A third way to initiate the flow is if the retailer offers a link in e-commerce to initiate returns, even for customers who are not logged in.
Customers can select items to return or exchange, quantity to return, and reason for return. After confirming the return, the customer is emailed a return label. The customer can also download a copy of the return shipping label and use it to ship the return items back. Customers can view and print the return label by using built-in browser functionalities to save or print the return label. In case the return label cannot be created or retrieved, an appropriate error message is displayed to the customer so that they can reach out to the contact center for help.
Base Return label generation is supported for FedEx, UPS, and USPS (the same carriers which are supported in customer service). This feature enables DSS Self-Service returns using Coordinadora as Return Carrier. If the Return Shipping Method is tied to a Coordinadora Carrier Service, upon confirming the DSS return, the Coordinadora component is invoked to generate a return label using multiple APIs.
6.1.1.7.7 - CrossLog
What is CrossLog?
Expert in e-commerce logistics and transport management for individuals (BtoC) and professionals (BtoB), CrossLog International offers its customers a scalable offer for their e-shop. As a WMS and TMS software editor, CrossLog International provides its customers all the necessary tools to drive their business and communicate dynamically with their consumers.
What does this integration include?
Manhattan Active Omni “MAO” is not integrated with Crosslog out of the box. This integration enables communication Crosslog by altering the base functionality in the following ways:
- Print Shipping & Return labels – To be able to print those labels, 3 requests are needed:
- Import Customer Order - Create a customer order in Crossdesk for tracking purposes
- Create Packs - Request the package tracking number and shipping label from Crosslog
- Get Parcel Return - Request the package return tracking number and return label from Crosslog
- Print the Crosslog edited Packing Slip – Request the packing slip PDF document from Crosslog. This feature can be enabled and disabled through configuration via API.
- Move the orders to shipped using the Get Order State call to Crosslog.
Shipping & Return labels
When a user completes a package in Store Inventory & Fulfillment “SI&F”, a ship process is initiated in MAO, which communicates the relevant data to Crosslog to get the shipping and return tracking numbers and labels. Crosslog requires a Customer Order to be created in their database before any ship or return request can be done. The customer order creation, CreatePacks and GetParcelReturn are translated to the Crosslog required format with the expected data for Crosslog to generate those labels. The Crosslog response is translated back to Store Fulfillment format where the tracking numbers are saved against the package, and the PDF labels are saved in the Supply Chain Document Management API to be printed with the packing slip.
Packing Slip
In the same sequence as the labels printing, MAO also communicates with Crosslog to get the Crosslog edited Packing Slip. This Packing Slip is added to the collate and printed within the same PDF file via a popup on the app. All the documents are stored separately in MAO but merged together in one document to be printed by the store associate.
Move Orders to Shipped
Once the labels are printed in store, the orders are Packed in MAO. Later in that day the carrier comes to collect the Packed orders and scans them to ensure the transfer of ownership is properly done. The carrier then updates Crosslog’s order status to a specific code that marks the order as in transit to the end customer.
MAO runs a scheduled job to get the order state of all Packed orders and moves those orders to Shipped when Crosslog returns this specific code.
6.1.1.7.8 - Cycleon
What is Cycleon?
Cycleon is an industry-leading, international returns management solution which integrates seamlessly with host systems to handle return label generation for multiple carriers.
What does this integration include?
Manhattan Active Omni is not integrated with Cycleon out of the box. This integration enables communication with Cycleon using ILS Core version 6.05 by altering the base functionality in the following ways:
- Return Label Generation + Retry Failed Label Generation in the Store Fulfillment Module
Return Label Generation
When a package is created in SI&F (Store Inventory & Fulfillment), and the user finishes packing a package, MAO calls Cycleon who returns the return label in the format configured within MAO for the corresponding store. The return label size is the standard 4” X 6” or 4” X 4” labels provided by the carriers. SI&F does not resize the label. Although, the return label size is configurable via the custom Configstore API.
EOM will send a return label message for each package that is to be processed. If successful, the response nodes are returned and the Cycleon Id is persisted to the fulfillment detail; otherwise an ERROR node will be returned with a human-readable message.
The language on the label is determined by the address from where the label is mailed.
Retry Failed Label Generation
The reprint option is also available per base Manhattan Active Omni in case the label is damaged or unsuccessfully printed in any way. If the label has previously been printed, it is persisted in the Document Management Server and MAO can pull the previously generated label. If the label has failed to generate, a new request is sent to Cycleon.
6.1.1.7.9 - DHL
What is DHL?
DHL is an industry-leading carrier shipping solution that integrates seamlessly with host systems to handle all small parcel, LTL and TL return orders.
What does this integration include?
Out of the box, Manhattan Active Omni Store Fulfillment does not integrate with DHL. This integration enables communication with DHL by altering the base functionality in the following ways:
- Generate the Return Order Tracking number & Shipping Label
Return Tracking Number and Label Generation
This feature adds integration with DHL to track the delivery status and to make a call to DHL Rate and Shipment service to initiate a Return. DHL receives the request and responds with the Return Tracking Number and Return Label. Return Label is saved as a PDF file in the Document API of Manhattan Active Omni. This document covers two returns processes:
- CSR initiated returns in call center
- Website (import order) initiated returns
6.1.1.7.10 - FedEx
What is FedEx?
FedEx Corp. provides customers and businesses worldwide with a broad portfolio of transportation, e-commerce and business services. FedEx Express and FedEx Express are the business segments that provide parcel shipping services.
What does this integration include?
This integration extends the base-supported Store Fulfillment integration with FedEx by adding the following:
- Pickup Service
Pickup Service
Retailers may schedule reoccurring Pickups if their Store Locations are eligible for the service. Other businesses may require On-Call Pickup Requests if they are not eligible for scheduled Pickup.
The Pickup Service WSDL allows you to schedule a courier to pick up a shipment, cancel a pickup request, or check for pickup availability. As part of this feature, the Pickup Service is used to check for pickup availability and schedule courier pickup of a shipment at the location specified in the transaction.
When a Store has at least one Package manifested with FedEx Express Service Level, a PickupAvailabilityRequest is made to determine whether Pickup Service is available that day at the given Store Location. Based on the PickupAvailabilityReply, a CreatePickupRequest call is made.
6.1.1.7.11 - Fiege
What is Fiege?
Fiege is a third-party logistics company that handles shipments into and out of Switzerland for Sketchers. Fiege leverages Swiss Post as a carrier for delivery within Switzerland. All integration from MAO is directly to Fiege and Fiege handles integration with Swiss Post.
What does this integration include?
This feature adds integration with Fiege REST APIs, specifically the Return Label and Shipment Tracking APIs. These integrations provide the ability to track shipments and create self-service returns within Manhattan Active Omni Digital Self Service.
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS and Call Center. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. A CSR agent can click the tracking number of the shipment while viewing and order’s status. The Digital Self-Service Shipment Tracking page and Call Center UI display details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service and Call Center makes a real time API call to the carrier to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, Fiege. When a user accesses the Shipment Tracking UI for a package shipped via Fiege, a real time call is made to the Fiege API to retrieve the latest status of the package as well as the tracking history.
Self-Service and Call Center Return Labels
Retailers may provide the ability to create returns and same-style exchanges via DSS. Customers can initiate the self-service exchange flow in a few different ways. One is via the link provided in the shipment confirmation email. Another is if the retailer provides a link to return in the customer’s My Account page in e-commerce. A third way to initiate the flow is if the retailer offers a link in e-commerce to initiate returns, even for customers who are not logged in.
Customers can select items to return or exchange, quantity to return, and reason for return. After confirming the return, the customer is emailed a return label. The customer can also download a copy of the return shipping label and use it to ship the return items back. Customers can view and print the return label by using built-in browser functionalities to save or print the return label. In case the return label cannot be created or retrieved, an appropriate error message is displayed to the customer so that they can reach out to the contact center for help.
Base Return label generation is supported for FedEx, UPS, and USPS (the same carriers which are supported in customer service). This feature enables DSS Self-Service returns using Fiege as Return Carrier. If the Return Shipping Method is tied to a Fiege Carrier Service, upon confirming the DSS return, the Fiege component is invoked to generate a return label using the Return Label API. The Fiege component will also pass item and general information about the return order along the return label request so that Fiege can process customer returns accordingly.
6.1.1.7.12 - Logistyx
What is Logistyx?
Logistyx TME is a SaaS-based Transportation Management Solution for global parcel shipping that guarantees carrier compliance, streamlines transportation booking, monitors parcel delivery movements, and identifies ongoing opportunities to increase profits per shipment.
What does this integration include?
This integration enables communication with Logistyx by altering the base functionality in the following ways:
- Rate Shop – Sends necessary data in the Ship Request for Logistyx to rate shop from the Store Fulfillment Module of Manhattan Active Omni
Rate Shop
When a user completes a package in Store Fulfillment, a ship request is generated, which communicates the ship from, ship to address and other relevant package information. This ship request is translated to the Logistyx required format with the expected data for Logistyx to select the carrier and generate the shipping label. The Logistyx response is translated back to the Store Fulfillment format where the tracking number is saved against the package, and the 4 X 6 PNG shipping label is saved in the document repository to be printed with the pack slip.
Rate Shopping allows Logistyx to compare carriers and service levels that meet the expected commitment date and ultimately choose the lowest-cost method to ship a package. There is a rate group assigned to each service level, where the corresponding Logistyx Rate Group Name and Id are configured in MAO. The rate group information is sent in the request to Logistyx for each package.
6.1.1.7.13 - Loomis
What is Starken?
Loomis is a major transportation company in Canada. Loomis Express has what it takes to be your Canadian shipping partner, with a wide range of Domestic and Export services to get your packages wherever they need to go. Whether it’s close to home or around the globe, we deliver to addresses coast to coast in Canada and over 220 countries worldwide.
What does this integration include?
This feature adds integration with Loomis REST Transport-Orders APIs, specifically the Shipment Tracking APIs. These integrations provide the ability to track shipments within Manhattan Active Omni Digital Self Service.
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, Loomis. When a user accesses the Shipment Tracking UI for a package shipped via Loomis, a real time call is made to the Loomis Individual Shipping Consultation API to retrieve the latest status of the package as well as the tracking history.
6.1.1.7.14 - MetaPack
What is MetaPack?
MetaPack is a leading provider of eCommerce delivery management technology to enterprise retailers and brands. The MetaPack platform integrates over 470 carriers and 5,500 delivery services to ensure that retailers and brands can offer delivery options and convenience for their customers.
What does this integration include?
Manhattan Active Omni is not integrated with Metapack out of the box. This integration enables communication with MetaPack Manager 5.x from Manhattan Active Omni “MAO” and Manhattan Active Warehouse Management “MAWM” for:
- Rate Shop – Sends necessary data to MetaPack to rate shop amongst carriers and shipping methods in order to determine the most optimal shipping service
- Shipping – Createsthe consignment in MetaPack for shipping visibility
- Print – Requeststo print the shipping label from MetaPack for the consignment previously created using the Shipping call
- Void – Request to void a package with MetaPack in case a user needs to unpack the order or change the shipping method
- EOD Manifesting – Request to manifest the package(s) created with MetaPack for each location
Rate Shop
Rate Shopping allows MetaPack to compare carriers and service levels that meet the expected commitment date and ultimately choose the lowest-cost method to ship the package or order based on the business rules set up in MetaPack. If enabled - a rateshop group is sent to MetaPack that corresponds to a Service Group on the MetaPack Side, which allows MetaPack to perform rate shopping amongst similar shipping methods.
Shipping
When a user completes a package, a ship request is generated that communicates the service level, ship from, ship to address and other relevant package information to MetaPack. The base ship request from the Parcel API is updated to allow integration with MetaPack. A shipment call is sent in MetaPack’s required format, where MetaPack creates the consignment for visibility to the carrier’s open manifest, and a shipping label is returned from this call.
After the packing process is completed and the consignment is created in MetaPack, the MAO/MAWM MetaPack App sends a request to MetaPack to provide the additional customs documentation (if required).
Void
A user may wish to change the shipping method or undo the packing due to reasons such as damage to the package or order cancelation. If a consignment was created in MetaPack and now the tracking number will not be used, MetaPack requires a Void request to remove or invalidate the package from a carrier’s open manifest.
Note: The user can only void the package if the package has not been manifested.
EOD Manifesting
The MAO/MAWM MetaPack AP runs a scheduled job to send a manifest request to MetaPack to mark the open consignments as ready to manifest. Alternatively, the base End of Day UI can be utilized to generate the EOD request per carrier. The actual manifesting is handled by Metapack through Delivery Manager and is not communicated back to MAO/MAWM.
Note: It is up to the Manhattan project team & customer to define the preferred approach (scheduler or End of Day UI) as part of the project. It is advised to only use one of these methods.
6.1.1.7.15 - Proship
What is ProShip?
ProShip is an industry-leading multi-carrier shipping solution that integrates seamlessly with host systems to handle all small parcel, LTL and TL shipments.
What does this integration include?
Manhattan Active Omni is not integrated with ProShip out of the box. This integration enables communication with ProShip by altering the base functionality in the following ways:
- Shipping
- Rate Shop
- Void
Shipping
When a user completes a package in SI&F, a ship request is generated, which communicates the service level, ship from and ship to address and other relevant package information. This ship request is translated to the ProShip required format with the expected data for ProShip to select the carrier and generate the shipping label. The ProShip response is translated back to the Store Fulfillment format where the tracking number is saved against the package, and the 4 X 6 PNG shipping label is saved in the document repository to be printed with the pack slip.
Rate Shop
Rate Shopping allows ProShip to compare carriers and service levels that meet the expected commitment date and ultimately choose the lowest-cost method to ship a package. If enabled, the rate shop ship via is sent to ProShip instead of the service level, which allows ProShip to perform rate shopping.
Void
A user may wish to undo the packing process for a fulfillment or package due to reasons such as damage to the package or order cancelation. If a tracking number will not be used due to the user canceling the packing process, SI&F sends a void request to ProShip who removes or invalidates the package from a carrier’s open manifest.
6.1.1.7.16 - Purolator
What is Purolator?
Purolator is one of Canada’s leading integrated freight, package and logistics solutions provider.
What does this integration include?
Manhattan Active Omni is not integrated with Purolator out of the box. This integration enables communication with Purolator by altering the base functionality in the following ways:
- Tracking Information – Request updated tracking information for packages in transit to the customer
- Return Label Generation
Tracking Updates
When a user completes a package in SI&F (Store Inventory & Fulfillment Module), a tracking number is assigned to the package in transit to the customer. This tracking number is stored on the order and displayed on the call center UIs to provide updated delivery information to the call center agent. SI&F makes a call to Purolator in the Purolator required format with the expected data, including a list of SI&F’s in transit tracking numbers, for Purolator to respond with the latest tracking information on each. Based on the response for each tracking number, SI&F makes corresponding updates to the tracking details on the order, in addition to updating the order to ‘Delivered’ status upon final confirmation of delivery.
Returns
When a return order is confirmed, MAO makes a return shipment request to Purolator and Purolator responds with a return tracking number. SI&F sends a subsequent request to Purolator using the tracking number provided in order to obtain the return label. The return tracking number is stored in MAO and the return label is stored in doc management to be retrieved by the external system sending the email to the customer. The customer prints the label and uses it to ship the product back to the return center.
6.1.1.7.17 - Starken
What is Starken?
Starken is one of the leading courier and shipping companies in Chile, offering warehousing, logistics and distribution services. Starken has more than 250 branches throughout Chile and 22 regional distribution centers. Starken fulfillment services are focused mainly on sending documents, packages and parcels.
What does this integration include?
This feature adds integration with the Starken PRO REST Seguimiento (Tracking) API. This integration provides functionality to track shipments within Manhattan Active Omni Digital Self Service and Call Center which were fulfilled via Starken carrier.
Shipment Tracking
Retailers may provide the ability to track shipments via MAO DSS and Call Center. To access the Shipment Tracking UI, a customer can use the “Track Package” link provided in the shipment confirmation email/text or via the link provided in an e-commerce site. One Shipment Tracking page is required per package; there is currently no “Order Status” page which displays the status of all items on an order.
The Digital Self-Service Shipment Tracking page displays details about a package, including:
- Package status (e.g. in transit or delivered)
- ETA or delivered date
- Details about items in the package (Currently the UI displays item short description, size, color, price, and shipped quantity. Other attributes are not supported).
- Tracking details
Self-Service makes a real time API call to the carrier such as FedEx to retrieve the latest package status. Out of the box integration exists for FedEx, UPS, and USPS. This feature provides additional integration for 3rd party carrier, Starken. When a user accesses the Shipment Tracking UI for a Tracking Number related to a package shipped via Starken, a real time call is made to the Starken PRO Seguimiento API to retrieve the latest status of the package as well as the tracking history.
6.1.1.7.18 - UPS
What is UPS Mail Innovations?
UPS Mail Innovations Returns is a contractual postal returns solution that offers convenience and efficiency to clients’ customers by enabling them to return their orders through the United States Postal Service.
What does this integration include?
Online Orders, bridged into MAO, can be fulfilled by a Distribution Center or a Customer Store. Out of the box, Manhattan Active Omni Store Fulfillment supports FedEx and UPS carrier integrations. This integration extends the base-supported parcel integration with UPS by adding:
- Return Labels
Return Labels
This feature facilitates integration with UPS Mail Innovation Returns to generate return labels for each package fulfilled by Manhattan Active Omni Store Fulfillment Application.
6.1.1.7.19 - United States Postal Service
What is USPS?
The United States Postal Service (USPS) is a vital delivery platform that enables American commerce by providing service to every American business and address.
What does this integration include?
This integration enables communication with USPS by altering the base functionality in the Manhattan Active Omni Store Fulfillment Application in the following ways:
- Shipping - Request the package tracking number and shipping label from USPS
- Tracking Information – Request updated tracking information for packages in transit to the customer
- Cancel Label – Cancels the purchased label in cases where required
Shipping
When a user completes a package in SI&F, a ship request is generated, which communicates the service level, ship from and ship to address and other relevant package information. This ship request is translated to the USPS required format with the expected data for USPS to generate the shipping label. The USPS response is translated back to the Store Fulfillment format where the tracking number is saved against the package, and the 4 X 6 PNG shipping label is saved in the document repository to be printed with the pack slip.
Tracking Updates
When a user completes a package in SI&F, a tracking number is assigned to the package. SI&F compiles the list of open tracking numbers and calls USPS in the required format for status updates on each package. USPS responds with the latest tracking information on each. If the carrier status is configured as ‘In Transit’ in MAO, the package is updated to ‘In Transit’ and the fulfillment is updated to Shipped.
Cancel Package
This is a service exposed to allow for MAO to call and cancel a label printed with USPS when the store associate requests to reprint the label with an updated Carrier and/or Service Level value. This service can either be invoked directly via API call or through an additional extension at the desired event point.
Package Pickup Request
This service allows retailers to schedule reoccurring pickups if their store locations are eligible for the service (based on address). This service allows you to check for pickup availability and to schedule USPS to pick up a shipment. When a store location has at least one package manifested with USPS express shipping, a Pickup Availability Request is made to determine whether pickup service is available that day at the given store location. Based on the response, a package pickup schedule request call is made.
6.1.1.8 - Loyalty & Rewards
Manhattan Active Omni solution provides clients the ability to maintain customer loyalty information used for various reward incentives. Many clients integrate with a 3rd party loyalty system to manage tracking loyalty points based on purchases, as well as the ability to redeem earned rewards on future orders.
Manhattan Active Omni has pre-built apps with many 3rd party loyalty systems which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations

6.1.1.8.1 - 500friends
What is 500friends?
500friends is a loyalty marketing platform that helps you retain, engage, understand, and connect to your customers. 500Friends integrates seamlessly with host systems to handle all customer loyalty metrics such as how many loyalty points a customer has earned per transaction committed & how much remaining value is available on a customer’s loyalty certificate.
What does this integration include?
Manhattan Active Omni is not integrated with 500Friends out of the box. This integration enables communication with 500Friends by altering the base functionality in the following ways:
- Validate – Ensure certificate ID is valid and mark them as “Used” when redeemed
- Monitor – Sends necessary data in the Balance Check for 500Friends to determine how many loyalty points a customer has earned
- Payment Transactions – 500Friends authorizes and settles transactions that contain a loyalty certificate as a form of payment on the order
Validate
There is a Custom SOAP API to 500 Friends to validate certificate Ids upon loyalty certificates being used as a payment method on the order. Request Parameters include Certificate Id and Amount of Certificate. Response Parameters include the status and actual amount of the certificate. MAO makes this call when a user enters a loyalty certificate as a payment method on the call center UI. Whenever a Loyalty Certificate is applied, a tax call must be made to recalculate taxes. The Loyalty Certificate amount is prorated by weight across all items while making the tax call. This is a temporary proration and is not saved after the tax call is made.
Monitor
Manhattan Active Omni performs a synchronous Balance Check transaction call when a Loyalty Certificate tender is added to an order. When adding a Loyalty Certificate tender to an order, a CSR will capture a card number and pin and enter those into the payment details in the Call Center UI. Active Omni then generates a Balance Check transaction in the 500Friends format when a CSR presses “Add” to confirm the addition of the Loyalty Certificate tender.
Payment Transactions
Manhattan Active Omni performs an Authorization transaction call for a Loyalty Certificate tender when either an order is placed or updated in the Call Center UI, which contains a Loyalty Certificate tender that has yet to be authorized. MAO also performs an Authorization call if an order is sent with a valid Loyalty Certificate number without an authorization transaction record. If an order or portion of the order is canceled where an Authorization Reversal transaction is generated, MAO sends a call in the 500Friends format to mark the payment as no longer valid. Dummy Settlement and Refund transactions are generated for Loyalty Certificates and are closed by MAO with no calls to 500Friends.
6.1.1.9 - Promotions
Manhattan Active Omni solution provides clients the ability to integrate with a 3rd party external promotions engine to apply automatic promotions as well as promotions tied to a coupon code during order capture or order edits. As changes to the order are made, a new promotion call can be triggered and the discounts associated to the applied promotions are saved on the order and used in order total calculations. These discounts can be applied against the order, specific order lines, specific charges, and directly against the item price.
Manhattan Active Omni has pre-built apps with many 3rd party Promotion Engines which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations


6.1.1.9.1 - Oracle Relate
What is Relate?
Oracle’s Relate is a CRM system which is used to manage coupons and promotions and offers services to redeem coupons. The system consuming the coupon is expected to make use of these services.
What does this integration include?
Manhattan Active Omni is not integrated with Relate out of the box. This integration enables communication with Relate by altering the base functionality in the following ways:
- Coupon Validation
- Coupon Redemption
- Coupon Void
Coupon Validation
When a new order is created or an existing order is edited to add a serialized coupon in Manhattan Active Omni, MAO makes call to receive the serialized coupon status from Oracle CE.
Coupon Redemption
The feature offers a service to initiate coupon redemption call for one or more serialized coupons in a transaction after the coupons are deemed valid.
Coupon Void
In the scenario where an order is cancelled, or a line is cancelled, Manhattan Active Omni makes a call to Oracle CE to void the applied coupon(s).
6.1.1.9.2 - Salesforce
What is Sales Force Commerce Cloud OCAPI?
Sales Force Commerce Cloud (SFCC) has a pricing and promotions offering called ‘OCAPI’ which is used by customers for their Web/ Call Center orders to determine the pricing and promotions.
What does this integration include?
Manhattan Active Omni is not integrated with SFCC OCAPI out of the box. This integration enables communication with OCAPI by altering the base functionality in the following ways:
- Pricing & Promotion Evaluation
- Calculate S&H
- Retrieving SFCC Customer ID
Pricing and Promotion Evaluation
SFCC is used to manage all types of promotions, as well as pricing of the items for the included order types under this integration. SFCC provides a single pricing and promotions engine to have a consistent way of evaluating pricing and promotions across different B2C/B2B channels. This includes evaluating order promotions, coupons, item promotions, pricing, and shipping promotions. Coupons added by the CSR in the UI are evaluated and, if eligible, are applied to the basket. These promotions are applied to a Customer Order via a REST-service call to SFCC OCAPI. SFCC determines if the coupons are eligible (making an internal call to external system for validation) based on the basket details of the order and responds with the applied promotion(s) details and value.
The basket calculation web-service call is triggered whenever an update is made on the order that impacts promotion eligibility (Ex. Add Item/Cancel line, Add Coupon, Enter Shipping Information, Quantity Update). The out-of-the-box MAO UI is utilized to display the promotion details to the CSR. Configuration for MAO to delete the basket is also available as SFCC OCAPI has a limit on the number of open baskets for a given customer.
Calculate Shipping and Handling
This feature adds the ability to bypass MAO Shipping Charge Calculation and instead use SFCC OCAPI for evaluating and apply shipping charges.
Retreiving SFCC Customer ID
As many clients do not maintain the SFCC Customer ID as the main Customer ID in MAO, the SFCC Customer ID needs to be provided back on the first basket call, which MAO stores on the order in an extended attribute. This value is then sent as the Customer ID in all subsequent basket calls to OCAPI.
6.1.1.9.3 - XCCommerce
What is XCCommerce?
XCCommerce provides a state of the art suite of applications that enable complex promotion and coupon capabilities across all channels and provide a seamless and consistent customer experience at all points of purchase.
What does this integration include?
Manhattan Active Omni is not integrated with XCCommerce out of the box. This integration enables communication with OCAPI by altering the base Point of Sale functionality in the following ways:
- View Promotions – Call XCCommerce ‘PEM-L’ Service to display eligible promotions for a given item
- Apply Promotions – Call XCCommerce ‘PEM-P’ to reapply promotions based on defined modifications to the cart
View Promotions API
When a store associate is browsing items from the item global search or product catalog in Manhattan Active Omni Point of Sale module, it is important to enable them with promotion information to help upsell to the customer. Whenever an item is selected from the global search or product catalog, this App generates the ‘PEM-L’ call to XCCommerce to return back the eligible promotions for the item to display to the user.
Apply Promotions API
When the store associate is making updates to the Point of Sale cart, such as adding or removing an item or adding a coupon, the cart must be re-evaluated for eligible promotions. MAO generates a ‘PEM-P’ call to XCCommerce to apply any eligible promotions to the cart. The response is translated to the MAO required format to update the cart.
6.1.1.10 - Tax
Manhattan Active Omni solution provides integration out of the box with Vertex to calculate estimated taxes during order creation, order edits, and final taxes upon invoicing. Some customers may wish to integrate with a different 3rd party tax engine to calculate taxes.
Manhattan Active Omni has pre-built apps with many 3rd party tax engines which can be leveraged out of the box. Please see each 3rd party vendor to view what functionalities are available.
Third Party Integrations
6.1.1.10.1 - OneSource
What is OneSource?
OneSource is a tax software that integrates seamlessly with host systems to provide quotation and invoice tax detail information for customer order transactions.
What does this integration include?
Manhattan Active Omni allows for base-supported tax integration with Vertex Tax Management. This integration enables communication with OneSource by altering the base functionality in the following ways:
- Quotation tax calculation
- Invoice tax calculation
- Return invoice tax calculations.
Quotation Tax Calculation
When an order is created or edited in Manhattan Active Omni’s Call Center module, a quotation tax call is generated for the order so the appropriate authorized amount of a payment tender can be secured. This quotation tax call is translated to the OneSource required format with the expected data for OneSource to provide the quotation tax calculation. The OneSource response is translated back to the Manhattan Active Omni format where the jurisdiction-level tax details are saved against the order and order line(s).
Invoice Tax Calculation
When an order is shipped in Manhattan Active Omni, an invoice tax call is generated for the order in, so the appropriate amount of the provided payment tender can be settled against. This invoice tax call is translated to the OneSource required format with the expected data for OneSource to provide the invoice tax calculation. The OneSource response is translated back to the Manhattan Active Omni format where the jurisdiction-level tax details are saved against the order and order line(s).
Return Invoice Tax Calculation
When an order is refunded in Manhattan Active Omni, an invoice tax call is generated for the order in so the appropriate amount of the provided payment tender can be settled against. This invoice tax call is translated to the OneSource required format with the expected data for OneSource to provide the invoice tax calculation. The OneSource response is translated back to the Manhattan Active Omni format where the jurisdiction-level tax details are saved against the order and order line(s).
6.1.1.10.2 - Taxware
What is Taxware?
Taxware is a continuous and connected platform for tax determination, e-invoicing compliance, and tax reporting to governments around the world. All these services are offered as part of a single cloud-based platform.
What does this feature include?
This feature adds integration with Taxware to facilitate Manhattan Active Omni to calculate Quotation, Invoice, and Return taxes.
Quotation
When an order is created or modified using Manhattan Active Omni’s Customer Service or Point of Sale Solutions, a quotation tax call is generated instead of the order so the appropriate authorized amount of a payment tender can be secured. This quotation tax call is translated into the format required by Taxware and comprises all the details that Taxware needs to calculate the quotation tax amount. The Taxware response is then translated back to the Manhattan Active Omni format, and the tax details are saved against the order and the respective order line(s).
Invoice
When an order is shipped in Manhattan Active Omni, an invoice tax call is generated to calculate the tax at the time of shipment so that the appropriate amount can be settled against the provided payment tender. This invoice tax call is translated to the format required by Taxware and comprises all the details needed by Taxware to perform the invoice tax calculation. The Taxware response is then translated back to the Manhattan Active Omni format, and the tax details are saved against the order and the corresponding order line(s).
Return
When an order is returned in Manhattan Active Omni, a return invoice tax call is generated against the order so that the appropriate amount can be refunded to the customer. This return invoice tax call is translated into the format mandated by Taxware and contains all the details that Taxware needs to calculate the return invoice tax amount. The response is then translated back to the Manhattan Active Omni format, and the tax details are saved against the order and the respective order line(s).
6.1.1.10.3 - Avalara
What is Avalara?
Avalara is an industry-leading tax solution that integrates seamlessly with host systems to handle all tax calculation needs for eCommerce.
What does this integration include?
Manhattan Active Omni is not integrated with Avalara out of the box. This integration enables communication with Avalara by altering the base functionality in the following ways:
- Tax management including Quotation, Invoice, and Refund tax calculations
- Tax Rate Download
Tax Management
When an order is created in Manhattan Active Omni’s Customer Service or Point of Sale applications, a quotation tax call is generated for the order so the appropriate authorized amount of a payment tender can be secured. When an order is shipped in Manhattan Active Omni, an invoice tax call is generated for the order so the appropriate amount of the provided payment tender can be settled against. When an order is returned in Manhattan Active Omni, an invoice tax call is generated for the order so the appropriate amount of the provided payment tender can be refunded against.
The tax calls are translated to the Avalara required format with the expected data for Avalara to provide the appropriate tax calculation. The Avalara response is translated back to the Manhattan Active Omni format where the jurisdiction-level tax details are saved against the order and order line(s).
Tax Rate Download
Avalara Tax Rate Download is used to support tax calculation in POS Offline mode. A scheduler is created in Manhattan Active Omni to trigger the Avalara Tax Rate Download API on a configurable schedule. MAO sends the list of store locations to Avalara and Avalara returns the applicable tax rates for all valid Store/Product Class combinations.
6.1.2 - Manhattan Active® Supply Chain
Integrate your Manhattan Active Solution with common third party services such as parcel. Additional capabilities beyond what is available in the existing apps can be addressed by the services project team.
Please select the category from below for a summary of its functionalities.
6.1.2.1 - Integrated Automation & Robotics
Manhattan Active Warehouse Management includes the industry’s first WES built into a WMS, which coordinates all resources within the distribution center to ensure each asset - automation, robotics, and people work together. This often includes integrating with advanced material handling solutions (MHE) to ensure maximum throughput within the distribution center. Manhattan has made it easy to add new automation through the Manhattan Automation Network, consisting of best practice integration and industry-leading providers. Together, they create an ecosystem that helps get automation initiatives up and running faster than ever before. MHE integration opportunities include:
- Putaway, Picking, and Palletizing Robotics
- Automated Storage and Retrieval Solutions
- Conveyance and Sortation Systems
- Pick to Light and Zone Picking Solutions
- Goods to person picking solutions
Third Party Integration


6.1.2.1.1 - Grey Orange
What is Grey Orange?
Grey Orange specializes in robotic fulfillment solutions. Their core offerings include autonomous mobile robots (AMRs) and a cloud-based software platform called GreyMatter. These systems work together to automate material movement, order picking, and inventory management within warehouses.
What does this integration include?
Manhattan Active Warehouse Management solutions provide clients with direct integration with Grey Orange for picking, putaway, and inventory management flows. This integration enables REST communication between Grey Orange and Manhattan Active Warehouse Management with messages in standard JSON format.
Picking
After orders are cubed into optimal shipping containers, MAWM is responsible for releasing work to the floor for order fulfillment considering the availability of resources. Upon release MAWM exchanges picking details with Locus. Locus optimization assigns the picking details to carts for execution. During the picking process Locus sends necessary data back to MAWM for picking confirmation. This process supports both pick direct to shipping container and pick to tote flows. Messages included are:
- Pick Expectation – Sent from MAWM to Grey Orange with picking details.
- Pick Transactional Notification – Sent from Grey Orange to MAWM to confirm each individual picks within a task. This does not contain short information.
- Pick Release/Inventory Awaited Notification - Sent from Grey Orange to MAWM to notify the entire pick tasks is completed. This contains partial or full short information.
- Pick Cancel – Sent from MAWM to Grey Orange when a pick allocation is cancelled.
Putaway
After inventory is received, MAWM is responsible for releasing work to the floor for putaway considering the availability of resources and storage locations within a warehouse. Upon allocation to Grey Orange managed locations, MAWM exchanges allocation details with Grey Orange. Grey Orange optimization assigns the allocation details to Grey Orange storage locations for execution. During the putaway process, Grey Orange sends necessary data back to MAWM for putaway confirmation. Messages included are:
- Put Expectation - Sent from MAWM to Grey Orange with putaway allocation details.
- Put Complete - Sent from Grey Orange to MAWM to confirm putaway.
- Put Cancel - Sent from MAWM to Grey Orange to cancel putaway.
Inventory Management
MAWM needs to keep track of inventory levels in Grey Orange managed locations. This is achieved by requesting inventory sync from Grey Orange. Additionally, inventory adjustments occurring due to processes such as counting are fed back to MAWM by Grey Orange.
- Inventory Sync Request - Sent from MAWM to Grey Orange to get inventory sync based on the scheduler.
- Inventory Sync - Sent from Grey Orange to MAWM to sync inventory.
- Inventory Transaction - Sent from Grey Orange to MAWM to adjust inventory.
6.1.2.1.2 - Locus Robotics
What is Locus?
Locus is a warehouse automation company with multiple solutions including directed robotic picking and restocking. Their directed robots optimize worker productivity and accuracy in the warehouse by pairing travel optimization with a clear user interface to assist the putaway and picking processes.
What does this integration include?
Manhattan Active Warehouse Management solutions provides clients with direct integration with Locus for cart picking and cart putaway flows. This integration enables REST communication between Locus and Manhattan Active Warehouse Management with messages in standard JSON format.
- Cart Picking - Assigns the picking details to carts for execution.
- Cart Putaway - Communicates putaway details and exceptions.
Cart Picking
After orders are cubed into optimal shipping containers, MAWM is responsible for releasing work to the floor for order fulfillment considering the availability of resources. Upon release MAWM exchanges picking details with Locus. Locus optimization assigns the picking details to carts for execution. During the picking process Locus sends necessary data back to MAWM for picking confirmation. This process supports both pick direct to shipping container and pick to tote flows. Messages included are:
- OrderJob.New – Sent from MAWM to Locus after work release. Includes picking details.
- OrderJobResult.Accept/Reject – Sent from Locus to MAWM in response to OrderJob.New message.
- OrderJobResult.Print – Sent from Locus to MAWM to trigger the printing of the shipping label at task start.
- OrderJobResult.ToteInduct – Sent from Locus to MAWM to notify MAWM of job start.
- OrderJobResult.Pick – Sent from Locus to MAWM to confirm the pick.
- OrderJobResult.ToteMove – Sent from Locus to MAWM in exceptions during picking.
- OrderJob.Update – Sent from MAWM to Locus after task priority change.
- OrderJobResult.UpdateComplete/Reject – Sent from Locus to MAWM in response to OrderJob.Update message.
- OrderJob.Cancel – Sent from MAWM to Locus when a task needs to be removed from Locus system.
- OrderJob.ResultCancelComplete/Reject – Sent from Locus to MAWM in response to OrderJob.Cancel message.
Cart Putaway
After inventory is received, iLPNs can be scanned in MAWM Make Putaway Cart process to build a tote array. Once built the arrays can be inducted onto Locus Carts. During the putaway execution process Locus communicates putaway details and exceptions. Messages included are:
- PutawayJob.New – Sent from MAWM to Locus after the tote array is “ended” in MAWM Make Putaway Cart.
- PutawayJobResult.Accept/Reject – Sent from Locus to MAWM in response to PutawayJob.New message.
- PutawayJobResult.PutInduct – Sent from Locus to MAWM to notify MAWM of the tote array / cart being inducted onto a Locus cart.
- PutawayJobResult.Put – Sent from Locus to MAWM communicating a putaway of inventory.
- PutawayJobResult.PutMove – Sent from Locus to MAWM communicating the array moving to a different bot.
- PutawayJobResult.PutComplete – Sent from Locus to MAWM communicating putaway cart completion.
- PutawayJob.Cancel – Sent from MAWM to Locus when an iLPN needs to be deallocated from Locus system.
- PutawayJobResult.CancelComplete/CancelReject – Sent from Locus to MAWM in response to PutwayJob.Cancel message.
6.1.2.2 - Parcel Carrier
Manhattan Active Warehouse Management solutions provides clients the ability to integrate with external parcel providers for flexible rate shopping, shipping label generation, manifest assignment. Use cases include:
Optional rules-based Rate Shop Group determination by MAWM.
Rate shop request at package generation for optimal carrier & service level assignment which meets customer service level agreement.
Flexible tracking number generation timing to fit various business requirements.
Carrier compliant references that provide additional information on shipping labels.
Shipping label document storage in MAWM for real time or delayed printing requirements.
Real time manifest assignment or delayed assignment using Ship to Hold functionality.
Simple ‘End of Day’ process to request closure of carrier manifests from MAWM to ship packages.
Manifest documentation provided by EPI and printed by MAWM at the time of End of Day.
Third Party Integrations
6.1.2.2.1 - MetaPack
What is METAPACK?
MetaPack is a leading provider of eCommerce delivery management technology to enterprise retailers and brands. The MetaPack platform integrates over 470 carriers and 5,500 delivery services to ensure that retailers and brands can offer delivery options and convenience for their customers.
What does this integration include?
Manhattan Active Warehouse Management solutions provides clients with direct integration with one of the leading eCommerce delivery management systems, MetaPack. This integration enables communication with MetaPack Manager 5.x from Manhattan Active Warehouse Management “MAWM” for:
- Rate Shop – Sends necessary data to MetaPack to rate shop amongst carriers and shipping methods in order to determine the most optimal shipping service. Rate shopping at package generation compares carriers and services that meet the expected commitment date and selects the lowest cost shipping method.
- Shipping – Creates the consignment in MetaPack for shipping visibility. Ship request at package completion creates the consignment visibility to the carrier’s open manifest
- Print – Request to print the shipping label from MetaPack for the consignment previously created using the Shipping call. Print requests are sent automatically as packing is complete to obtain the corresponding shipping documents
- Void – Request to void a package with MetaPack in case a user needs to unpack the order or change the shipping method.
- EOD Manifesting – Request to manifest the package(s) created with MetaPack for each location. Automatic End of Day manifest processes are performed without any user intervention
- Direct API communications between MAWM and MetaPack do not require use of middleware
RATE SHOP
Rate Shopping allows MetaPack to compare carriers and service levels that meet the expected commitment date and ultimately choose the lowest-cost method to ship the package or order based on the business rules set up in MetaPack. If enabled - a rateshop group is sent to MetaPack that corresponds to a Service Group on the MetaPack Side, which allows MetaPack to perform rate shopping amongst similar shipping methods.
SHIPPING
When a user completes a package, a ship request is generated that communicates the service level, ship from, ship to address and other relevant package information to MetaPack. The base ship request from the Parcel API is updated to allow integration with MetaPack. A shipment call is sent in MetaPack’s required format, where MetaPack creates the consignment for visibility to the carrier’s open manifest, and a shipping label is returned from this call.
After the packing process is completed and the consignment is created in MetaPack, the MAO/MAWM MetaPack App sends a request to MetaPack to provide the additional customs documentation (if required).
VOID
A user may wish to change the shipping method or undo the packing due to reasons such as damage to the package or order cancelation. If a consignment was created in MetaPack and now the tracking number will not be used, MetaPack requires a Void request to remove or invalidate the package from a carrier’s open manifest.
- Note: The user can only void the package if the package has not been manifested.
EOD MANIFESTING
The MAO/MAWM MetaPack App runs a scheduled job to send a manifest request to MetaPack to mark the open consignments as ready to manifest. Alternatively, the base End of Day UI can be utilized to generate the EOD request per carrier. The actual manifesting is handled by Metapack through Delivery Manager and is not communicated back to MAO/MAWM.
- Note: It is up to the Manhattan project team & customer to define the preferred approach (scheduler or End of Day UI) as part of the project. It is advised to only use one of these methods.
6.2 - Access Management 2.0 FAQ
Objective
Access Management 2.0 is the next feature-rich version of the Manhattan Active Platform Identity & Access Management (IAM). It introduces new capabilities such as support for multiple Identity Providers (IdPs), OIDC JIT, and more flexible UI/API configuration options, all while maintaining backward compatibility with the current version of the Manhattan Authorization Server. This page provides a list of the most Frequently Asked Questions (FAQ) along with their answers.
Does it support native Organization Database Users’ login?
Yes, it does. Access Management 2.0 (AM 2.0) natively supports the database users that Manhattan Active products maintain in the Organization Component/Organization Database.
Does it support Multiple Identity Providers?
Yes, it does. Support for multiple Identity Providers has been a frequent request from many Manhattan customers. Access Management 2.0 now fully supports this feature through simple configuration, without requiring any additional code changes.
Does it support SAML 2.0 Just In Time User Creation/Updates?
Yes, it does. Like its predecessor, the legacy Authorization Server, Access Management 2.0 continues to support SAML 2.0 Just-In-Time (JIT) user creation and updates in the Organization Database. While the legacy Authorization Server relied on KV Store property configurations to achieve this functionality, Access Management 2.0 introduces a customer-facing Admin User Interface for configuring SAML 2.0 Identity Providers (IdPs) with JIT or non-JIT features.
Does it support OIDC Just In Time User Creation/Updates?
Yes, it does. Unlike its predecessor, the legacy Authorization Server, which did not support OIDC JIT, Access Management 2.0 fully supports OIDC 2.0 Just-In-Time (JIT) user creation and updates in the Organization Database. It also introduces a customer-facing Admin User Interface to configure OIDC Identity Providers (IdPs) with either JIT or non-JIT features.
Does AM 2.0 Support Custom Branding and Styling?
Yes, it does. Access Management 2.0 includes a Custom User Interface within the Admin UI, allowing users to provide custom style sheets to tailor the look and feel of the platform. Customers often request changes to the standard logo, background image, and footer to align with their branding. A detailed step-by-step guide is also available to assist the Services team.
Does AM 2.0 support Multiple Locales?
Yes, it does. Access Management 2.0 supports over 20 locales out of the box. The desired locale can be easily changed through the Admin UI. Additionally, Access Management 2.0 can dynamically detect browser headers to automatically adjust for localization.
Does AM 2.0 support all Existing Standard Clients in the Legacy AuthServer?
Yes, it does. The legacy Authorization Server supported 13 standard clients, all of which are also supported in Access Management 2.0. For existing customers, these clients are migrated automatically, while for new customers, they come pre-seeded.
Will the switch over from existing AuthServer to AM 2.0 migrate existing standard and custom clients and what are the caveats?
All standard Manhattan clients will be migrated along with their client secrets. Custom clients will also be migrated but without their client secrets. Customers can either update the client secret for a custom client or create a brand-new custom client to meet their external application integration needs.
Does AM 2.0 support Custom Client creation?
Yes, it does. There is a customer-facing help page in the Manhattan Developer Hub that provides a step-by-step guide on creating custom clients, mapping attributes, updating client secrets, and more.
Does AM 2.0 support special characters like the + sign in the Client Secrets?
Yes, it does. If there is one or more + signs in the client secrets, users have two options:
- Option 1: Pass the client secret in its verbatim form within the request body, e.g., using the Body tab in Postman.
- Option 2: Use the Authorization tab in Postman, select Basic Auth, and URL-encode the + character by replacing it with %2B.
How to avoid Users originating from the Customer’s Identity Provider receiving Password Reset Email.
This can be done by setting this property “manh.security.login.identity-type” in the KV Store to mixed.
Does it support the Resource Owner Password Grant aka Password Grant?
The Manhattan Standard Client for Postman no longer supports the Password Grant due to security considerations. Manhattan recommends using the more secure Authorization Code Grant for tools such as Postman. Access Management 2.0 supports the Authorization Code Grant by default. However, if a customer requires Password Grant support, they can create a custom client with Direct Grant support enabled.
Does Access Management 2.0 support the Password Grant with a username and password sent via the Request URL?
No, it does not. Using the Password Grant this way is considered a security violation. The Password Grant was originally intended as a temporary OAuth2 grant type, designed to be replaced by the more secure Client Credentials Grant.
Is there any customer-facing documentation for Custom Client Creation?
Yes, there is one, located here Access Management 2.0.
What is the information needed from the Customer’s Security Admin for IdP Configuration?
For an OIDC Identity Provider, the following are needed:
- The well-known URL provided by the OIDC IdP
- The Client ID
- The Client Secret
For SAML 2.0 Identity Provider, the following are needed:
- The IdP Metadata URL.
- Manhattan needs to provide the Service Provider (SP) Metadata URL to the Customer.
- The Signing and Encryption Keys need to be given and configured in the Customer SAML 2.0 IdP.
Does AM 2.0 support Custom Access Token Lifespans?
Yes, it does. In special cases, this can be configured in the Access Management 2.0 UI. However, if there is a request to extend Access Token lifespans, please reach out to R&D for further discussion and approval.
Does AM 2.0 support different levels of Admin UI Access?
Yes, it does. Access Management 2.0 supports two types of administrators:
- Full Administrator: Has permissions to access, edit, and delete all configurations.
- Restricted Administrator: Has limited access and can manage only Clients and Identity Providers.
Does AM 2.0 support two Signing/Encryption Keys for Access Tokens and SAML 2.0?
Yes, it does. Access Management 2.0 supports the use of two keys: one for internally signing JWT access tokens and another for integrating with the customer’s SAML 2.0 Identity Provider (IdP). For more details or specific requirements, please reach out to R&D for further discussion.
Does AM 2.0 support Auditing/Event Publishing to Activity Stream?
Yes, it does. While the legacy Authorization Server supported Activity Stream Event, Access Management 2.0 expanded the coverage to include
- Authentication Failures (401) and Authorization Failures (403)
- Postman Login
- Identity Provider Login Success and Failure
- Native DB Login Success and Failures
- Password Reset / Set / Change Events
Does AM 2.0 support Password Reset/Forgot Password/Change/Set Password?
Yes, Access Management 2.0 supports the full range of password management use cases, including Forgot Password, Change Password, Set Password, and Reset Password. It is fully integrated with the existing component-organization to facilitate these functionalities.
Does AM 2.0 support Role Based Access Control for Org. DB Users and External IdP Users?
Yes, it does. Like the legacy Authorization Server, Access Management 2.0 fully supports RBAC and is 100% backward compatible in this regard.
Does AM 2.0 allow Manhattan Employees to log in as DB Users?
No, it does not. Access Management 2.0 mandates that all Manhattan employees authenticate using the Manhattan Azure IdP, which is configured in the Admin UI. However, a small whitelist of robot users with the manh.com suffix is permitted to ensure operational effectiveness.
Does AM 2.0 support Voice-Enabled Devices?
Yes, it does. Access Management 2.0 supports the Voice device from a few vendors. Please check with your Service Representative.
Does AM 2.0 support Android and iOS Store Applications?
Yes, it does support both the Android and iOS versions of the Store Application.
Does AM 2.0 support MHE Authentication?
Yes, Access Management 2.0 supports MHE integration.
What role do Manhattan employees play while authenticating using the Manhattan Azure IdP?
Customers are still required to authorize Manhattan employees for access, even though the employees authenticate against the Manhattan Azure IdP. Roles for these employee users are still validated against the Organization Database.
Does AM 2.0 support the User Discovery Mode of the Legacy AuthServer?
No, it does not. Access Management 2.0 supports a single Login Page that provides multiple options for Login. Users can easily choose the native database login, the Customer IdP Login, or the Manhattan Employee Login.
How does AM 2.0 support Multiple IdP Authentication in the UI?
Access Management 2.0 supports a single Login Page customizable for the background image, footer, logo and other styles. Users can easily choose the native database login, the Customer IdP Login, or the Manhattan Employee Login.
How does AM 2.0 support the mapping of User Attributes from External Identity Providers?
Access Management 2.0 supports the mapping of standard user attributes (documented separately in the Developer Hub) through the Mapper tab in the Identity Provider Configuration. It allows the mapping of both single-valued attributes and multi-valued attributes (e.g., roles) represented as comma-separated values. User attribute mapping functions consistently, regardless of the underlying protocol (SAML 2.0 or OIDC).
Does Access Management 2.0 have the userOrgs claim as part of the Access Token?
Access Management 2.0 always includes all mandatory and optional claims as part of the Access Token, aligning with industry standards. If the legacy Authorization Server returned claims outside of the Access Token, users have two options:
- Option 1 Extract the UserOrgs from within the Access Token.
- Option 2 Call the /{url}/authserver/api/authserver/user endpoint separately to receive the id token which will include all claims.
How to avoid the HTTP 413 Request Entity too large/Payload too large errors?
When an OAuth2 client, such as a Spring Boot REST API / UI, calls another REST API with a Bearer Token in the Authorization header, and the token is excessively large (e.g., a very large JSON Web Token or opaque token), it can lead to an HTTP 413 (Payload Too Large) error in the following scenarios:
Header size limit exceeded:
- The Authorization header containing the Bearer Token contributes to the total size of the HTTP request headers.
- If the token is excessively large, it may exceed the maximum allowed header size configured on the target REST API server or an intermediate gateway (e.g., Nginx, AWS API Gateway, or a firewall).
- Most servers enforce limits on header sizes to prevent abuse or resource exhaustion.
Token encoded as JSON:
- If the token is a JSON Web Token (JWT), it includes a payload that might encode a large number of claims, roles, or other metadata.
- For example, a JWT may include user roles, scopes, or custom claims, making the token size grow beyond typical limits.
How this causes HTTP 413
- The server (or an intermediate gateway) immediately responds with an HTTP 413 Payload Too Large error, indicating it cannot process the request.
- This happens before the request body is even processed, as headers are inspected first during request parsing.
How to avoid HTTP 413:
- If the User whose Access Token generates the HTTP 413 has a large number of Roles, Org, etc., please call the following endpoint after the authentication call /{url}/authserver/api/authserver/user
6.3 - Activity Stream FAQ
Frequently Asked Questions for Activity Stream.
What Events are captured by Activity Stream?
Authentication/Authorization/Access Control Events
With the current version of the Manhattan Identity & Access Management (Access Management 2.0), the following access control events are captured by Activity Stream:
- Native Database Events (Organization Database User)
- Successful Login
- Failed Login
- User Password is Locked
- User is Disabled
- Password Update Success
- Password Update Failure
- Password Reset Success
- Password Reset Failure
- Forgot Password Success
- Forgot Password Failure
- Federated Identity Providers Events (eg Okta, Azure, Ping Identity, and others)
- Successful Login via
- OAuth 2.0 Client
- SAML JIT
- OIDC JIT
- IdP Pass Through for Direct (Password Grant)
- Failed Login
- OAuth 2.0 Client
- SAML JIT
- OIDC JIT
- IdP Pass Through for Direct (Password Grant)
- Successful Login via
- Other Events
- Obtaining an Access Token using Postman REST Client
REST API Gateway Events
HTTP-based REST API traffic intercepted by the Manhattan Active API Gateway is captured and recorded as events. This includes:
- Inbound API calls originating from outside the Manhattan Active Platform’s VPC
- Outbound API calls that originate from within the Manhattan Active Platform’s VPC (from Business Components through XBOUND)
Message Processing Events
The Manhattan Activity Stream also captures various message processing during Printing, Wave Processing, and other similar actions. As Message Publishers publish messages for consumers to consume, Activity Stream Messages published during the consumer processing include the elapsed time among other things.
What is the target of the Events/Message Publishing?
The Target of the Activity Stream Events/Message Publishing is a single Google PubSub Topic named activity-stream.
What is the name of the GCP PubSub activity-stream subscription?
The subscription for the activity stream ends with “x”. It usually has the format activity-stream-%-x.
How quickly should I acknowledge a message that I have consumed?
When Google PubSub receives an acknowledgment from a consumer, it marks the message for deletion. If the message is not acknowledged within a configurable limit, it is resent which could lead to duplicate processing by the consumer. The default acknowledgment limit is 10 seconds (check the latest from Google Cloud Docs) but it can be increased (not recommended).
Recommendations for Consumers:
- Ensure all processing paths result in Acknowledgement within the time limit (eg a final block)
Problems to avoid:
- Sending an acknowledgment before persisting/committing the received message may lead to message/data loss if the underlying storage platform later receives an error/exception after the acknowledgement is sent
- Sending the acknowledgment after 10 seconds makes Google PubSub think the message processing has failed at the consumer end and it tries to resend the message again resulting in duplicate messages
Should a Message Consumer expect duplicate messages from Google PubSub?
Yes. Consumers of Google PubSub may sometimes observe duplicate messages, even if a message was published only once. Client libraries used to consume messages include various fail/retry logic to handle network latency and connectivity issues. The same payload may appear more than once with two different message ids if the client receives the original message but fails to acknowledge it within the stipulated 10 seconds (default).
Besides, Google uses the same acknowledgment mechanism to confirm client libraries are publishing messages to PubSub. If due to various reasons (such as network latency), the client library publishing messages does not get the acknowledgement from Google in time, it will indeed send a new message with the same payload resulting in duplicates.
How should a Message Consumer recognize and handle duplicate messages?
Duplicate messages received from Google PubSub topics have unique Message IDs but the business payload is the same. Message Consumers should expect duplicate messages and keep track of recent business keys/primary keys from the payload of processed messages to ensure that the message has not already been processed/persisted. In essence, all message consumers should be Idempotent.
What are common targets for storing Activity Stream events?
Customers may choose to consume the Activity Stream messages from the topic and store the data in any of the following:
- Database: Any Relational Database like MySQL, Postgrace, Microsoft SQL Server, Oracle, DB2 and others
- Service: Application Monitoring Tools like Dynatrace, DataDog, Splunk, and Prometheus have their POST REST APIs to consume new telemetry and, if used, can be used to build useful Dashboards for Alerting/Monitoring.
- Data Lake: Any Big data platform like Google BigQuery, Snowflake, Azure Data Lakes, or AWS RedShift can be used as a sink/target data store
Do I need to write code to consume Activity Stream events?
No. Several Customers have used third-party tools such as Dell Boomi, Mulesoft, Securonix, etc., to consume messages from Activity Stream subscriptions and process them.
What is a Service Account?
A Service Account is a system user used by applications to connect securely to Google Cloud Services. Service Accounts can be assigned the same roles and permissions as a human user. Service Accounts may be identified by a unique set of keyed data (a JSON file). These JSON Keys may be used by Customer-owned clients to connect to Google PubSub and consume messages.
How many Service Accounts are needed for consuming messages from Activity Stream?
One for each customer environment. This is generally two (for stage and production).
How to request a Service Account?
Customers can request a service account by Creating a Ticket in Salesforce.
How does Manhattan Operations share a Service Account with its customers?
When Manhattan Operations creates a Service Account and its associated JSON key, it is shared using Secure Mail.
What IAM Roles are required for a Service Account to access Activity Stream messages with Google PubSub?
The following IAM roles should be assigned to the service account that is used to consume messages published:
- PubSub Subscriber
- PubSub Editor
What performance considerations are recommended when developing an application to generate alerts from Activity Stream events?
It is important to consider the potential volume and rate of messages that are published. When developing an application that consumes Activity Stream events and generates alerts, it must scale to read (and acknowledge) messages to keep pace with the publishing rate. If the consumer lags (by more than 15 minutes) behind the publishing rate, then the alert will fall behind, reducing its effectiveness.
What kinds of publishing rates and message sizes can be expected for staging and production environments?
- Design Criteria 1: Customer-owned Consumer is responsible for Scaling Properly to consume all the messages to avoid the Alerting System from Message Consumption Lag
- Design Criteria 2: If a million messages are waiting to be consumed and the Customer is running a low number of consumers, the Alerting System will not achieve its goal.
Do Activity Stream messages contain request and response payloads?
No. Activity Stream event messages do not contain request and response payloads (by default) for the following reasons:
- Size: Many times, the Response (and sometimes the Request) payloads add to the size of the overall Message and exceed Google’s PubSub message limits.
- Sensitive Data: Payloads for some API endpoints may contain Sensitive data. Personal Identifying Information (PII) or Payment Card Industry (PCI) cannot be exported from a Manhattan Active solution.
- Publishing Rate: Increasing the size of Activity Stream Event Messages published increases the network and processing performance requirements for consumers to keep pace.
How are different Activity Stream Events identified?
Events published to the Activity Stream record data as key-value pairs in the eventAttributes object. The x-activitystream-event-type key contains a different value based on the event as follows:
- zuul.request: An HTTP Request captured by the Manhattan Active API Gateway (Zuul Server)
- zuul.response: An HTTP Response captured by the Manhattan Active API Gateway (Zuul Server)
- auth.request: An Authorization Request received by Manhattan Access Management 1.0
- auth.response: An Authorization Request received by Manhattan Access Management 1.0
- Keycloak.request: An Authorization Request received by the Manhattan Access Management 2.0
- Keycloak.response: An Authorization Response received by the Manhattan Access Management 2.0
- Keycloak.custom: Other events captured by the Manhattan Access Management 2.0
- awpf.request: An asynchronous message posted
- awpf.response: An asynchronous message that was consumed
How do messages for Activity Stream events relate to one another?
Many events captured in the Activity Stream are paired as a request and its response (eg REST API calls, Authentication Requests). Both the request and its response are posted as separate messages to the Activity stream which have the same unique id (UUID) in the x-activitystream-request-id key field of the eventAttributes object.
How is the duration of an event recorded in the Activity Stream?
Response events published to the activity record the duration of time from the original request in the x-activitystream-elapsed-time key field of the eventAttributes object.
How does the client source IP of an event get recorded in the Activity Stream?
The IP Address of the client source is recorded in the x-real-ip key field of the eventAttributes object for both requests and responses.
How does a Consumer get the status code for processing the request?
The Consumer can get the HTTP status code by reading the x-activitystream-status-code attribute of the response event.
Is there a JSON Schema to describe the fields?
The following is a JSON Schema for the Activity Stream Event Payload.
Activity Stream JSON Schema
[{
"table_name": "activities_v5",
"columns": [{
"column_name": "timestamp",
"data_type": "TIMESTAMP",
"description": "timestamp activity created on. i.e. The time someone tried to login, call an API etc."
}, {
"column_name": "id",
"data_type": "STRING",
"description": "unique message id"
}, {
"column_name": "event_type",
"data_type": "STRING",
"description": "report discriminator, e.g. zuul.request zuul.response etc"
}, {
"column_name": "elapsed_time",
"data_type": "INT64",
"description": "time taken to process the request and generate a response, in milliseconds"
}, {
"column_name": "resource_method",
"data_type": "STRING",
"description": "request method used for accessing API, e.g. GET"
}, {
"column_name": "resource_api",
"data_type": "STRING",
"description": "resource API with parameters; lifted from parameterizedPath"
}, {
"column_name": "request_path",
"data_type": "STRING",
"description": "actual request path used by client"
}, {
"column_name": "status_code",
"data_type": "INT64",
"description": "status code should be an INT64; e.g. 200"
}, {
"column_name": "status",
"data_type": "STRING",
"description": "status string; e.g. OK, Accepted"
}, {
"column_name": "remote_addr",
"data_type": "STRING",
"description": "remote IP address of API requestor"
}, {
"column_name": "context_id",
"data_type": "STRING",
"description": "id populated from context or Zuul / XBound request; may repeat"
}, {
"column_name": "organization_id",
"data_type": "STRING",
"description": "lifted from organizationId, x-activitystream-userorg"
}, {
"column_name": "store_profile_type_id",
"data_type": "STRING",
"description": "Applicable for Active Omni Customers"
}, {
"column_name": "user_id",
"data_type": "STRING",
"description": "lifted from userId, x-activitystream-user"
}, {
"column_name": "thread_id",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "component_name",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "component_tag",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "component_stereotype",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "instance_id",
"data_type": "STRING",
"description": "for components, pod id; may be reused from pulse, Only meant for internal use"
}, {
"column_name": "active_release_id",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "code_drop_id",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "environment_type",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "customer_code",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "stack_name",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "stack_alias",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "data_type",
"data_type": "STRING",
"description": "Only meant for internal use"
}, {
"column_name": "data_size",
"data_type": "INT64",
"description": "Only meant for internal use"
}, {
"column_name": "event_data",
"data_type": "STRING",
"description": "Optional"
}, {
"column_name": "request_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-clientrequestid"
}, {
"column_name": "location_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-location"
}, {
"column_name": "store_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-store"
}, {
"column_name": "register_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-registerid"
}, {
"column_name": "device_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-deviceId"
}, {
"column_name": "order_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-order"
}, {
"column_name": "device_platform",
"data_type": "STRING",
"description": "lifted from x-activitystream-device-platform"
}, {
"column_name": "device_os",
"data_type": "STRING",
"description": "lifted from x-activitystream-device-os"
}, {
"column_name": "device_version",
"data_type": "STRING",
"description": "lifted from x-activitystream-device-version"
}, {
"column_name": "device_model",
"data_type": "STRING",
"description": "lifted from x-activitystream-device-model"
}, {
"column_name": "device_manufacturer",
"data_type": "STRING",
"description": "lifted from x-activitystream-device-manufacturer"
}, {
"column_name": "browser_name",
"data_type": "STRING",
"description": "lifted from x-activitystream-browsername"
}, {
"column_name": "app_version",
"data_type": "STRING",
"description": "lifted from x-activitystream-appversion"
}, {
"column_name": "signal_strength",
"data_type": "STRING",
"description": "lifted from x-activitystream-signalstrength"
}, {
"column_name": "roundtrip_time",
"data_type": "INT64",
"description": "lifted from x-activitystream-roundtriptime"
}, {
"column_name": "namespace",
"data_type": "STRING",
"description": "lifted from x-activitystream-namespace"
}, {
"column_name": "event_timestamp",
"data_type": "TIMESTAMP",
"description": "lifted from x-activitystream-event-timestamp"
}, {
"column_name": "pagename",
"data_type": "STRING",
"description": "lifted from x-activitystream-pagename"
}, {
"column_name": "error_type",
"data_type": "STRING",
"description": "error type; e.g. client, server, none"
}, {
"column_name": "is_error",
"data_type": "BOOL",
"description": "error flag; true/false"
}, {
"column_name": "response_time_bucket",
"data_type": "STRING",
"description": "response time in seconds"
}, {
"column_name": "nginx_id",
"data_type": "STRING",
"description": "lifted from x-request-id"
}, {
"column_name": "invoke_id",
"data_type": "STRING",
"description": "lifted from x-activitystream-invoke-id"
}, {
"column_name": "trace_id",
"data_type": "STRING",
"description": "lifted from CP-TRACE-ID"
}, {
"column_name": "tenant_id",
"data_type": "STRING",
"description": "lifted from tenantid"
}, {
"column_name": "content_type",
"data_type": "STRING",
"description": "lifted from content_type"
}, {
"column_name": "content_length",
"data_type": "INT64",
"description": "lifted from content_length"
}, {
"column_name": "user_agent",
"data_type": "STRING",
"description": "lifted from user_agent"
}, {
"column_name": "build_date",
"data_type": "TIMESTAMP",
"description": "lifted from x-activitystream-builddate"
}, {
"column_name": "extension_point",
"data_type": "STRING",
"description": "lifted from awpf-activitystream-extension-point"
}, {
"column_name": "extension_handler",
"data_type": "STRING",
"description": "lifted from awpf-activitystream-extension-handler"
}, {
"column_name": "entry_condition_met",
"data_type": "BOOL",
"description": "lifted from awpf-activitystream-is-entry-condition-met"
}, {
"column_name": "failure_reason",
"data_type": "STRING",
"description": "lifted from awpf-activitystream-is-entry-condition-met"
}, {
"column_name": "custom_build_date",
"data_type": "TIMESTAMP",
"description": "lifted from x-activitystream-custombuilddate"
}, {
"column_name": "base_app_version",
"data_type": "STRING",
"description": "lifted from x-activitystream-baseappversion"
}, {
"column_name": "geohash",
"data_type": "STRING",
"description": "lifted from geohash"
}, {
"column_name": "georegion",
"data_type": "STRING",
"description": "lifted from georegion"
}, {
"column_name": "action",
"data_type": "STRING",
"description": "lifted from x-activitystream-action"
}, {
"column_name": "event_attributes",
"data_type": "JSON",
"description": "Uncategorized / unlifted event attributes"
}]
}]
Sample Activity Stream Messages
REST API Gateway Events
HTTP REST API request messages captured by the API Gateway (Zuul Server) for an environment are posted to the Activity Stream with an eventType of zuul.request.
REST API Gateway Request Message
{
"id": "1120506062",
"eventType": "zuul.request",
"timestamp": "2025-01-20T02:40:18.731Z",
"eventAttributes": {
"via": "1.1 google",
"host": "*****.sce.manh.com",
"accept": "application/json, application/json",
"userId": "*****",
"tenantId": "****spr11o",
"threadId": "122",
"x-scheme": "https",
"stackName": "****spr11o",
"x-real-ip": "50.x.x.126",
"codeDropId": "2.2.3.37",
"stackAlias": "*****",
"islocalized": "true",
"tls-version": "TLSv1.3",
"componentTag": "10.16.0-2e63256",
"content-type": "application/json",
"customerCode": "****",
"geoip-region": "US",
"x-request-id": "**************0af742aabdaf35647d",
"componentName": "com-manh-cp-zuulserver",
"content-length": "28327",
"organizationId": "WMET",
"param_Location": "WMET",
"activeReleaseId": "2024-09",
"environmentType": "p",
"x-forwarded-host": "*****.sce.manh.com",
"x-forwarded-port": "443",
"geoip-client-city": "Mount*******",
"upstreamComponent": "dmmobile-facade",
"x-forwarded-proto": "https",
"param_Organization": "WMET",
"x-forwarded-scheme": "https",
"componentInstanceId": "com-manh-cp-zuulserver-zuulserver-59cbd5d459-vcksr",
"componentStereotype": "ALL",
"x-activitystream-url": "/dmmobile-facade/services/rest/workflow/execute/workflowScriptName/Pick/stateName/AcceptQuantity/actionName/AcceptQuantity",
"geoip-client-lat-long": "48.729314,-97.107386",
"x-cloud-trace-context": "3c7e9739f1f80cc852b3703825f5620b/2397645423678738909",
"param_selectedLocation": "WMET",
"geoip-client-subdivision": "USVA",
"x-original-forwarded-for": "50.x.x.126,34.x.x.124",
"param_SelectedBusinessUnit": "",
"param_selectedOrganization": "WMET",
"x-activitystream-invoke-id": "****-9559-494a-aaff-f981da48a715",
"x-activitystream-namespace": "voice-app-wm",
"x-activitystream-event-type": "zuul.request",
"x-activitystream-request-id": "22350b830174c00af742aabdaf35647d",
"x-activitystream-resource-api": "/dmmobile-facade/services/rest/workflow/execute/workflowScriptName/Pick/stateName/AcceptQuantity/actionName/AcceptQuantity",
"x-activitystream-remote-address": "50.*.*.126",
"x-activitystream-request-method": "POST",
"x-activitystream-request-timestamp": "1737340818730"
}
}
HTTP REST API response messages captured by the API Gateway (Zuul Server) for an environment are posted to the Activity Stream with an eventType of zuul.response.
REST API Gateway Response Message
{
"id": "944858217",
"eventType": "zuul.response",
"timestamp": "2025-01-20T12:22:21.139Z",
"eventAttributes": {
"via": "1.1 google",
"host": "****.sce.manh.com",
"accept": "*/*",
"cookie": "zuulserver_SAVED_REQUEST=; com-manh-cp-zuulserver_JSESSIONID=****-5294-4596-b205-f19642e2ce72; XSRF-TOKEN=****-0550-473a-9297-f99af5d165fe",
"locale": "\"en_US\"",
"origin": "https://****.sce.manh.com",
"userId": "********",
"referer": "https://****.sce.manh.com/cdn/udc/15-19-9/2501090954/log-worker.js",
"priority": "u=1, i",
"tenantId": "****spr11o",
"threadId": "160",
"x-scheme": "https",
"stackName": "****spr11o",
"x-real-ip": "50.x.x.126",
"codeDropId": "2.2.3.37",
"stackAlias": "****p",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0",
"CP-TRACE-ID": "cc918dd054bac77c",
"tls-version": "TLSv1.3",
"componentTag": "10.16.0-2e63256",
"content-type": "application/json",
"customerCode": "****",
"geoip-region": "US",
"x-request-id": "af27a59cfc4b4ef8bd3808c568c9c602",
"x-xsrf-token": "6393338b-0550-473a-9297-f99af5d165fe",
"componentName": "com-manh-cp-zuulserver",
"COMPONENT_NAME": "com-manh-cp-zuulserver",
"content-length": "659",
"organizationId": "ACI-SC",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "en-US,en;q=0.9,es;q=0.8",
"activeReleaseId": "2024-09",
"environmentType": "p",
"x-forwarded-host": "****.sce.manh.com",
"x-forwarded-port": "443",
"geoip-client-city": "Mount Vernon",
"upstreamComponent": "commonui-facade",
"x-forwarded-proto": "https",
"x-forwarded-scheme": "https",
"componentInstanceId": "com-manh-cp-zuulserver-zuulserver-59cbd5d459-56cv6",
"componentStereotype": "ALL",
"x-activitystream-url": "/commonui-facade/api/commonui-facade/dumpLog",
"COMPONENT_INSTANCE_ID": "com-manh-cp-zuulserver-zuulserver-59cbd5d459-56cv6",
"COMPONENT_STEREO_TYPE": "ALL",
"X-Application-Context": "com-manh-cp-zuulserver:docker,sc,cloud,kubernetes,gcp,albt,p,albtp,albtspr11o:8990",
"geoip-client-lat-long": "38.729314,-77.107386",
"x-cloud-trace-context": "1af413f60c272925e15d931b8b5b5280/12101192973808972235",
"geoip-client-subdivision": "USVA",
"x-original-forwarded-for": "50.x.x.126,34.x.x.124",
"x-activitystream-invoke-id": "****-d97e-4c17-97fb-b37cff7efb7f",
"x-activitystream-event-type": "zuul.response",
"x-activitystream-request-id": "****a59cfc4b4ef8bd3808c568c9c602",
"x-activitystream-status-code": 200,
"Access-Control-Expose-Headers": "x-activitystream-elapsed-time",
"x-activitystream-elapsed-time": "9",
"x-activitystream-resource-api": "/commonui-facade/api/commonui-facade/dumpLog",
"x-activitystream-remote-address": "50.x.x.126",
"x-activitystream-request-method": "POST",
"x-activitystream-request-timestamp": "1737375741130",
"x-activitystream-response-timestamp": "1737375741139"
}
}Messaging Events
Asynchronous messages captured and posted to an environment are posted to the Activity Stream with an eventType of awpfEvent.
Message Posted Event
{
"id": "-412349973",
"eventType": "awpfEvent",
"timestamp": "2025-01-20T12:33:12.315Z",
"eventAttributes": {
"userId": "MHE****",
"tenantId": "****spr11o",
"threadId": "233",
"contextId": "****eac9120a8d5b::d67b446c5383cb52",
"stackName": "****spr11o",
"codeDropId": "2.2.3.37",
"stackAlias": "****p",
"userLocale": "\"en\"",
"componentTag": "20.114.3-a2d3f5f",
"customerCode": "albt",
"userTimeZone": "US/Pacific",
"componentName": "com-manh-cp-dmmobile-facade",
"organizationId": "ACI-SC",
"activeReleaseId": "2024-09",
"environmentType": "p",
"componentInstanceId": "com-manh-cp-dmmobile-facade-com-manh-cp-dmmobile-facade-**********-mckvj",
"componentStereotype": "REST",
"awpf-activitystream-status": "SUCCESS",
"x-activitystream-event-type": "awpfEvent",
"x-activitystream-resource-api": "/services/rest/workflow/execute/workflowScriptName/Pick/stateName/AcceptQuantity/actionName/AcceptQuantity",
"x-activitystream-request-method": "POST",
"awpf-activitystream-extension-point": "DMM:GenericHeader:DslExtension:MAALBTEX37AcceptQuantityPostInit",
"awpf-activitystream-extension-handler": "MAALBTEX**AcceptQuantityPostInit",
"awpf-activitystream-event-processing-time": 41,
"awpf-activitystream-is-entry-condition-met": true
}
}Authentication/Authorization/Access Control Events
When a user has successfully logged into the environment, an event is added to the Activity Stream with no eventType, but it has the x-activitystream-event-type of keycloak.custom in its eventAttributes.
Successful Login Event
{
"id": "1740880381480",
"timestamp": "2025-03-02T20:57:51.017Z",
"eventAttributes": {
"via": "1.1 google",
"host": "cmlap-auth.sce.manh.com",
"path": "/realms/maactive/login-actions/post-broker-login",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"cookie": "AUTH_SESSION_ID=*****",
"method": "GET",
"priority": "u=0, i",
"threadId": "157",
"x-scheme": "https",
"loginMode": "IDP",
"sec-ch-ua": "\"Not(A:Brand\";v=\"99\", \"Google Chrome\";v=\"133\", \"Chromium\";v=\"133\"",
"sessionId": "**********C6F6693ABF6F17A18FC47589B",
"stackName": "****spr11o",
"x-real-ip": "180.*.*.113",
"codeDropId": "2.2.7.27",
"requestURI": "/auth/realms/maactive/login-actions/post-broker-login",
"stackAlias": "****p",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36",
"loginStatus": "Successful",
"queryString": "client_id=zuulserver.1.0.0&tab_id=Jz4YwXq4S44",
"tls-version": "QUIC",
"componentTag": "1.0.0-latest",
"customerCode": "****",
"geoip-region": "AU",
"x-request-id": "***************f5e9649d6e3ece86b",
"cache-control": "max-age=0",
"componentName": "com-manh-cp-keycloak",
"param_username": "jess@*****************",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "cross-site",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"activeReleaseId": "2023-12",
"environmentType": "p",
"sec-ch-ua-mobile": "?0",
"x-forwarded-host": "****p-auth.sce.manh.com",
"x-forwarded-port": "443",
"geoip-client-city": "Me***",
"x-forwarded-proto": "https",
"sec-ch-ua-platform": "\"Windows\"",
"x-forwarded-scheme": "https",
"componentInstanceId": "com-manh-cp-keycloak-keycloak-*******d-98dcx",
"componentStereotype": "ALL",
"geoip-client-lat-long": "-**.813628,***.963058",
"x-cloud-trace-context": "*********c394a60b55d405ddbfc23/8253383120543991573",
"geoip-client-subdivision": "AUVIC",
"x-original-forwarded-for": "180.*.*.113,34.*.*.46",
"upgrade-insecure-requests": "1",
"x-activitystream-event-type": "keycloak.custom",
"x-activitystream-elapsed-time": "69 ms"
}
}
HTTP Requests to acquire an access token are posted to the Activity Stream with no eventType, but they have the x-activitystream-event-type of keycloak.request in their eventAttributes.
Access Token Request Event
{
"id": "1740880384195",
"timestamp": "2025-03-02T21:34:52.807Z",
"eventAttributes": {
"via": "1.1 google, 1.1 google",
"host": "****p-auth.sce.manh.com",
"accept": "application/json, application/x-www-form-urlencoded",
"cookie": "JSESSIONID=5DA31276447B6EBBEC81A2587******; KEYCLOAK_LOCALE=en",
"pragma": "no-cache",
"tenantId": "****spr11o",
"threadId": "157",
"x-scheme": "https",
"stackName": "****spr11o",
"x-real-ip": "35.*.*.74",
"codeDropId": "2.2.7.27",
"stackAlias": "****p",
"user-agent": "Java/11.0.22",
"method+path": "POST+/auth/realms/maactive/protocol/openid-connect/token",
"tls-version": "TLSv1.3",
"x-b3-spanid": "6e61cf38baca7c39",
"componentTag": "1.0.0-latest",
"content-type": "application/x-www-form-urlencoded;charset=UTF-8",
"customerCode": "****",
"geoip-region": "AU",
"x-b3-sampled": "1",
"x-b3-traceid": "5c0060f7e4e6707d",
"x-request-id": "07fb7451294a763b6012a96f22c5fe4e",
"cache-control": "no-cache",
"componentName": "com-manh-cp-keycloak",
"content-length": "274",
"param_username": "warehouse@*************.com",
"accept-encoding": "gzip,deflate",
"activeReleaseId": "2023-12",
"environmentType": "p",
"param_grant_type": "password",
"x-forwarded-host": "cmlap-auth.sce.manh.com",
"x-forwarded-port": "443",
"geoip-client-city": "Sydney",
"x-b3-parentspanid": "5c0060f7e4e6707d",
"x-forwarded-proto": "https",
"x-forwarded-scheme": "https",
"componentInstanceId": "com-manh-cp-keycloak-keycloak-767778566d-98dcx",
"componentStereotype": "ALL",
"x-activitystream-url": "/auth/realms/maactive/protocol/openid-connect/token",
"geoip-client-lat-long": "-3*.868***,15*.209***",
"x-cloud-trace-context": "10f2f27245e98775574badc5fc2ae84b/8363174625533109236",
"geoip-client-subdivision": "AUNSW",
"x-original-forwarded-for": "35.*.*.74,34.*.*.46",
"x-activitystream-invoke-id": "24ad8a75-adba-4430-b7b7-4850611882cb",
"x-activitystream-event-type": "keycloak.request",
"x-activitystream-request-id": "07fb7451294a763b6012a96f22c5fe4e",
"x-activitystream-resource-api": "/auth/realms/maactive/protocol/openid-connect/token",
"x-activitystream-remote-address": "35.*.*.74",
"x-activitystream-request-method": "POST",
"x-activitystream-request-timestamp": "1740951292806"
}
}6.4 - Asynchronous Communication with Manhattan Active® solutions via Google Pub/Sub
Introduction
Manhattan Active® Platform is API-first, cloud native, and microservices-based. For enterprise systems to integrate and communicate, Manhattan Active Platform provides both synchronous and asynchronous communication options. All asynchronous communication between Manhattan Active solutions and external systems is done via Google Pub/Sub. This document provides guidelines on how to set up asynchronous communication with Manhattan Active solutions over Google Pub/Sub.
What is Google Pub/Sub?
Google Cloud Pub/Sub is a real-time messaging service that allows applications to publish and subscribe to events. It’s a publish/subscribe-based mechanism for sending and receiving messages between applications and services. You can find more information on Pub/Sub on the Google Cloud website here: https://cloud.google.com/pubsub/docs/overview
Integrating with Google Pub/Sub
Google Pub/Sub provides two connectivity approaches:
- Google provides an SDK that can be added as a library to your application: https://cloud.google.com/pubsub/docs/reference/libraries
- REST API which can be invoked from your application: https://cloud.google.com/pubsub/docs/reference/rest
Authenticating to Pub/Sub
The Manhattan Associates project team will provide a JSON Key file to your integration team. The key file can be used to authenticate against Google Pub/Sub for both the integration approaches mentioned earlier - either the Google Pub/Sub SDK or the REST API. Please review Google Pub/Sub documentation for details on how to use a key file for authentication. Some external applications and middleware systems, such as Boomi, require a .p12 certificate instead for Pub/Sub Authentication, which the Manhattan project team can provide on request.
Pub/Sub Endpoints
The Manhattan Associates project team will create Pub/Sub endpoints for each external interface identified in the solution design. The interfaces may either be “Inbound”, where messages are sent to the Manhattan Active solution, or “Outbound” where messages are sent by the Manhattan Active solution out to external systems.
Outbound Interfaces
The Manhattan Active solution will publish outbound messages to a Pub/Sub topic, and the consumer(s) on the external system will have to read those messages from the corresponding Pub/Sub Subscription. The name of the Subscription will be in the following format: projects/{{project-id}}/subscription/{{interface-name}}
Note:
The project id will differ by environment – STAGE, VPT, or PRODUCTION. The project team will provide the project id value for each environment.
If multiple external systems need to consume a copy of the same message, then the external middleware system can consume the message from a single Pub/Sub subscription and fan out copies of the message to each receiver.
Inbound Interfaces
When external systems have to send messages to the Manhattan Active solution, they must publish those messages to the appropriate Pub/Sub Topic. The name of the Topic will be in the following format: projects/{{project-id}}/topic/{{interface-name}} If multiple systems need to send the same messages, they may send them to the same Topic. For example, if there are multiple Distribution Centers and Stores needing to send Inventory updates to Manhattan Active OMNI, they can all publish to a single Pub/Sub Topic.
The Manhattan project team will create the required Pub/Sub Topics and Subscriptions based on the solution design.
Message Payloads
Google Pub/Sub requires the message payloads to be Base64 encoded. The structure of the payload for each interface is documented in the Interface Mapping Document, created as a part of the Solution Design.
Message Payload Size
Google Pub/Sub limits the maximum size of a message to 10 MB. In case there is a possibility of messages exceeding the 10 MB limit for an interface, Manhattan Active Platform can be configured to send/receive GZIP compressed payloads for that interface. Note that when GZIP compression is enabled for an interface, it will apply to all messages for that interface, irrespective of whether specific messages exceed the 10 MB limit or not.
Message Acknowledgment
Once a consumer reads a message from a Google Pub/Sub Subscription, it must send an acknowledgment must be sent to Pub/Sub. This is used to ensure Guaranteed Delivery of messages. Please refer to Pub/Sub documentation on how to acknowledge receipt of messages.
Messages must be acknowledged even if message processing fails due to any kind of error, including validation errors. If a message is not acknowledged in a timely manner (by default 10 seconds), Google Pub/Sub will not remove the message from the subscription, leading to duplicate reads.
If a message sent from a Manhattan Active solution fails to process on the external system, the external system must not use a NACK response as it can cause infinite looping of that message. Instead, the failed message must be acknowledged and sent to a Dead Letter Queue for offline triage.
Duplicate Messages
To ensure Guaranteed Delivery of messages, Google Pub/Sub depends on message acknowledgments to determine if a consumer has received a message from the subscription. The message acknowledgments must be sent to Google Pub/Sub within a deadline, which by default is 10 seconds. If the acknowledgment threshold is crossed, Google Pub/Sub will assume the message was lost and will re-deliver the message to the consumer, which can lead to message duplication.
Manhattan Active Platform uses a custom Pub/Sub attribute to track inbound messages and identify duplicate messages being re-delivered by Pub/Sub. When sending messages to Manhattan Active solutions via Google Pub/Sub, the sending system must include the MSG_ID_PK attribute populated with a unique value. The unique value for the MSG_ID_PK attribute may be generated from a UUID library. The Manhattan Active solution can be configured to track each MSG_ID_PK value it reads from incoming messages and discard messages that have an MSG_ID_PK value that has been received previously. Since the duplication check works solely on the uniqueness of the MSG_ID_PK value, it is important that if the external system is resending a message, then it must not change the MSG_ID_PK value.
When the Manhattan Active solution sends outbound messages to external systems over Google Pub/Sub, it will include the MSG_ID_PK attribute to help external consumers identify and de-duplicate messages on their side.
Message Attributes
When an external system sends messages to the Manhattan Active solution, it must include the following Pub/Sub Attributes on every message:
| Attribute Name | Attribute Value |
|---|---|
| Organization | Organization at which the message must be processed. This is typically identified during the Solution Design. |
| User | User-id of an active user account in the Manhattan Active solution, whose PrimaryOrgId matches the Organization value. |
| MessageType | Interface name, to be provided by Manhattan |
| MSG_ID_PK | Unique message identifier, which is generated from a UUID library. Max length 50 characters. |
Every message sent by a Manhattan Active solution to an external system over Google Pub/Sub will have the following attributes (not an exhaustive list):
| Attribute Name | Attribute Value |
|---|---|
| SelectedOrganization | Org ID from which the message was generated in the Manhattan Active solution. Discard any message without throwing an error, that has an unrecognized value. |
| MSG_ID_PK | Unique message identifier. May be generated from an UUID library. Max length 50 characters. |
Message Sequencing
There is no guarantee of sequencing/ordering of messages sent from the Manhattan Active Solution via Pub/Sub. If the external systems require sequencing of messages being sent by the Manhattan Active solution, it is recommended that the external middleware system stages the incoming messages first locally and then sequences it for its consumption as needed.
Author
- Devraj Roy: Architect, Technical Services, PSO.
References
6.5 - Overview of AWPF message types
This article describes the concepts of InboundMessageType and OutboundMessageType entities and explains the importance of key fields in this entity that will help you configure the inbound and outbound traffic for a Manhattan Active® Platform microservice.
Fields of InBoundMessageType
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| MessageType | Message type for Inbound. This serves as the business key for the entity along with the profileId. InBoundMessageType is a config type entity, belonging to messaging profile purpose. | N.A | Some name that explains the business purpose of the inbound |
| Description | Functional description of this messageType on its usage. | N.A | Describe the business purpose of the messageType in clear words. |
| NoOfConsumer | The number of concurrent consumers to be started in a high volume stereotype instance like a QUEUE_PROCESSOR | null | Depends on the business usecase. Any QPROC coming up for this messageType will have this number of consumers. The value should be judiciously put based on the volume consideration. For a fairly high volume queue, it should be in 10s at least. |
| MinNoOfConsumer | The number of concurrent consumers to be started in a low volume stereotype instance like a LOW_VOLUME or ALL | null | null / 1 If it is set to null, then it is considered to be 1. It should not be more because generally the low volume instances listen to all the queues and adding more consumers just adds to the number of threads running in the container and may not actually help in scaling the queue processing. 0 The value should be specifically set to 0 in case you do not want any low volume instance to listen to this messageType. Only QPROCS will be able to process this messageType. |
| ServiceId | Service Id mapping to the ServiceDefinition that performs the actual business logic for this messageType. | N.A. | Should be the serviceId(mapped to a ServiceDefinition entry) that is supposed to process the message. |
| Idempotent | Flag to ensure the message is not processed multiple times on the consumer side. False value means it cannot be processed more than once. Should be used judiciously as it adds extra processing on the system as AWPF has to keep track of the processed messages in the database. | true | true (Unless your business usecase forces processing of the message only once. But if you mark a messageType as non-idempotent, please make sure you generate a messageId for the message on your own (on the producer side application code). Else, the framework generates a messageId on its own. This will not serve the actual purpose of a non-idempotent message as AWPF identifies a message with the messageId. Two identical messages (in terms of content) but having different messageIds will be treated as different messages by AWPF and will be processed separately.) |
| RetryCount | Maximum retry count for a message to process. You can override the system property level default retries for your messageType with this property if there is a need | 3 | 3 |
| RetryDelay | Retry delay for a message to process. Earlier the default retry delay was set to 500ms between each retry as a system property and all the messageTypes had to follow the same pattern. You can override the default by providing a comma separated list of retry delays (for each retry loop) for your messageType. | 20,300,600 | 20,300,600 Unless there is need for your messageType to change the default delay in each retry loop. |
| PreFetchCount | Prefetch count for a message type to process. This field lets the user override the default prefetch count set the brokerCluster level at the messageType level | 50 | 50 (Unless your messageType is fairly low volume and heavy processing one. If you have very less number of messages coming in but each message takes a lot of time to process, it is better to set low prefetch count to utilize all the available consumer threads. Else, 50 messages will be given to one consumer thread and other threads will remain idle. Scaling up the processing with QPROCS also will be problematic as very less messages will be in ready state and most of them will be stuck in the unacked state for a long time.) |
| BrokerClusterName | Used for setting up non-default broker properties. This property maps to the InternalBrokerConfig entity where the broker specific producer URI, consumer URI and other parameters are defined. | null | null (Unless your messageType requires to have a specific broker (like Kafka, SQS, Google pubsub) or you want to override specific properties of the default broker setup. Default NULL would mean RabbitMQ.) |
| BusinessKeyPath | A JSON path that points to a field on the payload Document that will be sent to this message type. In the event of a failed message, AWPF will evaluate this JSON path and send the value along with the failed message. When CommonUtil listens to the awpf-reprocess queue, it will look for this field and save it on the BusinessKey column in the failed message table. In the event of a batch job message failure, AWPF will evaluate this JSON path and save it on the UniqueIdentifier column in the batch processed message table | null | null (This field is used to quickly show the user messages that have failed for a specific business key. As such, if you want to make use of this feature, you should provide a JSON path that makes sense to the payload that will be processed by this MessageType.) |
Fields of InBoundQueues
This table is an optional child of InBoundMessageType where you can define explicit queue names
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| QueueName | If you want a specific queue name for your messageType and do not want AWPF to decide the queue name based on your messageType. This is helpful when you have to keep the same “messageType” property in multiple components, but every component has its own queue for this messageType. Mostly used by frameworks. | N.A. | N.A. |
| FullyQualifiedQueue | In a org-specific environment setup, each messageType corresponds to multiple queues, each queue belonging to a different organization that shares the profile. AWPF prefixes the derived queue name with the organization id to make the actual queues org specific. But, if you do not want AWPF to add any suffix and you want to keep the exact queue name you specify, you have to set this flag to true. This is mostly done while connecting to a SQS or pubsub topic where the queuename is part of the handshake with the third party. | false | N.A. |
| FullyQualifiedQueueV2 | Applicable for a multi-tenant environment. Value of true implies that no prefix including the tenant id should be added to the queue name | false | N.A. |
Fields of InBoundMsgToRetransmit
This table is yet another optional child of InBoundMessageType. This will be used to route the inbound message to another queue, without processing it in the current consumer.
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| ToMessageType | Maps to the outbound message type where the message will be retransmitted. This is mostly used for external integration. Say you are connecting to SQS/ Googlepubsub through XINT component but the actual processing of the message will happen in some functional component (like order or inventory). The inbound messageType connecting to SQS/Pubsub should be created in XINT and then the message should be retransmitted one of the internal RabbitMQ queues which will be consumed by the functional component. This is the recommended way of connecting to external brokers for ease of scaling. | null | N.A. |
| TransformServiceId | Maps to a service definition service id which will perform data transformation before retransmitting the message | null | null () |
Authors
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
6.6 - Overview of batch job configuration
This article describes the concepts of JobTypeDefinition and JobSchedule entities and explains the importance of key fields in these entities that will help you configure the batch jobs for a Manhattan Active® Platform microservice.
Entity details
Batch framework has the following entities. The below diagram just captures the Key fields for each entity to depict their relationship. The latter section explains each field in detail.
Please note that the one-to-many relationships shown in the diagram are figurative in nature. There is no database level constraint, it is more of a data relation between the entities.

JobTypeDefinition: This entity defines what and the how part of a job. The entity to store the different types of jobs for which schedules can be created. For. e.g “Re-tag Fulfillment”, “Cancel aged orders” etc. Each component is supposed to provide a finite set of such configurable jobs. New job types can be configured as this is a service level entity.
JobSchedule: This entity defines the when part of the job, basically the execution cadence based on the cron expression. It is tied to a particular jobType and there could be multiple schedules created for a job type. This is a service level entity and schedules can be created / updated as required.
JobParameters: This entity is the direct child of JobSchedule entity and is used to provide input parameters for the job as a key-value pair
JobConfiguration: This entity pertains to only batchv2 jobs and defines the how part of the job.
Fields of JobTypeDefinition
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobTypeId | Unique identifier for a particular job type. This serves as the business key for the entity along with the profileId. JobTypeDefinition is a config type entity belonging to batch profile purpose. For a spring-batch job, the JobConfiguration java file should contain a @Job bean with the same name | N.A. | Some name that explains the business purpose of the JobTypeDefinition. |
| JobTypeDescription | Brief description about the type of job. | N.A. | Describe the business purpose of the jobTypeDefinition in clear words. |
| ChunkSize | Chunk size for the particular job. This is applicable for spring-batch jobs and for JpaPagingItemReader type readers. The default QueryReaderBase, provided as part of BatchFramework makes use of this type of reader. Essentially what does it mean? There is a concept of ChunkSize and PageSize in spring-batch. If there is a lot of data to be read and written (to queues in our case), the read and write can happen in multiple threads and pages. The reader threads read as many number of records in one shot as the configured PageSize. The writer threads receive a List of items to be written to the queue, the List size is based on the ChunkSize. For simplicity, BatchFramework has assumed PageSize=ChunkSize for all processing. This document here has more details about the chunk oriented processing : https://docs.spring.io/spring-batch/trunk/reference/html/configureStep.html#chunkOrientedProcessing | null | N.A. The chunksize should be very carefully set based on the volume consideration for this job. If you expect few thousands of records or more to be read during one particular execution, it is better to set the ChunkSize to a higher value (may be in thousands). If you set it too less, the entire dataset will be logically broken into a large number of pages and as many DB hits will be fired to load the data. This can lead to a situation where all the eligible records are not picked up during an execution if the job updates the same column on which the reader query is built (part of the where clause). As the reader and writer can execute concurrently in separate threads, some of the eligible records can be updated while the read is still in progress. This will impact the total count and the page offsets calculated earlier. You can try adding an “oder by” clause on a field that doesn’t change on the update (like the created_timestamp) |
| StatusMonitorLevel | This field enables status monitoring for your job. Status monitoring implies keeping track of the progress of the job execution and marking the status to OPEN (read start), INPROGRESS (write complete) and COMPLETED (all messages processed). Basically status monitoring should be enabled for only those jobs where you want to take some action after the job execution has been completed and you have defined a callback handler. For all other jobs, setting status monitoring to true may cause un-necessary load on the system. This field supports these values : CHUNK, MESSAGE, NONE. CHUNK : Used to do status monitoring per chunk when t he data was stored at chunk level. Now this implies that status monitoring is enabled. MESSAGE : Not used any more. NONE : This implies that status monitoring is disabled for this job. POINT TO NOTE This feature is supported only when functional jobs have StatusMonitoringJobexecutionListenerBase as JobExecutionListener (for reference Agent Job configuration class | null | NONE Unless you business usecase needs to know the completion status of the job execution and you take some business decision/make some changes (like you have configured a CallBackHandler) based on the outcome of the job execution, it is better to disable the status monitoring by setting it to ‘NONE’. Please note : Leaving it to NULL would imply the value is defaulted to ‘NONE’ in the code. |
| JobType | This field defines different types of jobs. Supported values are SYSTEM, FUNCTIONAL, SERVICE, AGENT SYSTEM : Reserved for framework jobs and should not be used by components. FUNCTIONAL : For functional spring-batch type jobs. This is the default value that is assumed by BatchFramework if this field is not set. SERVICE : For functional service type jobs. Needs to be set explicitly for jobs that just invoke a ServiceDefinition on trigger. AGENT : Agent jobs. Mostly used by services teams to configure jobs where they need to execute the logic in their extension components. | null | N.A. Should be decided based on the Job. If left to the default value of NULL, the system would assume it is a spring-batch job (FUNCTIONAL). |
| JobStatusCallbackHandlerBean | This is the bean that will be invoked once the job execution has been completed. This bean should implement this interface : JobStatusCallbackHandler. If you want to configure a JobStatusCallbackHandlerBean for your job, it is mandatory to enable status monitoring for your job type. | null | N.A. Unless you have set the status monitoring levels accordingly for your job and you have some business logic to perform once the job execution completes. |
| InvocationServiceId | This maps to a ServiceDefinition entry in the system. Once the job trigger time comes, that particular ServiceDefinition will be invoked with all the jobParameters set in the schedule (refer to the section below) as input to the service method. This is tightly coupled with the field JobType (value = SERVICE) and is applicable only for service type jobs and has no bearing on the spring-batch jobs. | null | null Unless you have a SERVICE type job and you have the corresponding ServiceDefinition entry defined in the system |
| CreateContextFromJobParams | Flag to denote whether the context needs to be created from job parameters. By default, during the job execution, the context will be renewed to the context with which the JobSchedule was created. But in case, there is a need to override the context and execute the job in a custom context created from the JobParameters, this flag should be set to true. Location, Organization, User, and Business Unit can be overridden by the JobParameters. | false | false Unless you have a requirement to override the context with which the JobSchedule was created and you want to renew the context based on the JobParameters when the job executes |
| IsHeelToToe | Flag to denote whether it is a heel-to-toe job. A heel-to-toe job would only have one schedule of the job executing at any instance of time. Default false implies multiple simultaneous executions of the job is allowed. | false | false Unless you business usecase requires your job to be of heel-to-toe nature. |
| DropToMessageType | Unique identifier for the outbound messageType where the writer will send the messages. | null | If the DropToMessageType is not specified , the outbound message type will be considered as JobTypeId. |
| JobConfigurationId | Unique identifier for the job configuration. Required only for batch v2 jobs. | null | null Unless you are configuring a batchv2 type job. The Job configuration id mandatory for any batchv2 job to start. |
| MaxRunDuration | Expected time duration for one execution of the job. Jobs will be auto aborted post that. Should be given like ‘30 MIN’, ‘1 HOUR’ etc | null | null Unless you want to abort the job after a specific period of time if it still doesn’t complete naturally |
| IncludedOrganization | Comma separated list of organizations for which the JobSchedule will be included for execution. A jobSchedule will execute for all the organization which are sharing the same profileId for which the jobSchedule has been configured. Out of all those organizations, if you wish to execute the job for a particular few, this property needs to be configured | null | null Unless you wish to restrict the job execution only for certain organizations, even if there are many organizations which share the same profile |
| ExcludedOrganizations | Comma separated list of organizations for which the JobSchedule will be excluded for execution. A jobSchedule will execute for all the organization which are sharing the same profileId for which the jobSchedule has been configured. Out of all those organizations, if you wish to avoid execution of the job for a particular few, this property needs to be configured | null | null Unless you wish to avoid the job execution only for certain organizations, out of all the organizations which share the same profile |
| IsSyncExecution | Flag to denote if the job execution happens synchronously. Defaulted to false denoting async execution. Once the job trigger message arrives in the JobSchedule queue, the execution is handed over to a separate thread by default. As the trigger message is ACKed in the queue, the message is dequeued. In case the job execution fails due to some reason, we have to wait for the next trigger to happen to resume the execution. If you wish to keep the job trigger message alive in the queue till the time the job execution ends, you need to set this property TRUE | false | false Unless it is a very low frequency and important job that needs to resume immediately if the container processing the job goes down. |
Fields of JobSchedule
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobScheduleId | Unique identifier for a particular job schedule. This serves as the business key for the entity along with the profileId. JobSchedule is a config type entity belonging to batch profile purpose. | N.A. | Some name that explains the business purpose of the JobSchedule. |
| JobTypeId | Identifier of the job type to which this schedule is tied to. This field maps to a JobTypeDefinition (jobTypeId column). There is no DB relationship between these two tables, JobSchedule and JobTypeDefinition are linked through data only. | N.A. | Should be the JobTypeId of the JobTypeDefinition for which the JobSchedule has been created |
| CronExpression | String to represent the cron expression for the job schedule. Please refer to https://freeformatter.com for creating your cron. This field is used to build the cron trigger | null | Some cron based on the business need that defines the execution cadence for the particular job schedule. |
| IsDisabled | Flag to denote whether the job schedule is disabled(paused) for the time being. Default value is false, i.e enabled. Is there is a need to stop a schedule from executing for some time and you do not want to delete it yet, this flag can be set to true. This will temporarily disable a schedule until it is enabled back by setting this flag to false | false | false Unless you want to disable a schedule |
| IsAdhoc | Flag to denote whether the job schedule is a dummy schedule created for adhoc jobs. The schedule will be deleted after the execution has been completed. This flag is used entirely for internal purposes and to support ad-hoc jobs (one time execution jobs that can run with any given parameter provided as input). | false | false |
| TimeZone | Timezone in which schedule needs to be executed/triggered. UTC is considered by default. POINT TO NOTE There is a specific format that BatchFramework (and component-scheduler) supports for the timezone input. Please refer to this page for the supported values : https://en.wikipedia.org/wiki/List_of_tz_database_time_zones | null | null Unless there is a business need to run your job at a particular timezone. Most of the repeated jobs should not worry about timezones as they would run at specific intervals. Default NULL implies UTC. |
Fields of JobParameters
This table is the direct child of JobSchedule entity and is used to provide input parameters for the job as a key-value pair
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| InputKey | JobParameters are key-value pairs which are given as input during the job execution. This field is the key field of the pair. | null | N.A. |
| InputValue | JobParameters are key-value pairs which are given as input during the job execution. This field is the value field of the pair. | null | N.A. |
Fields of JobConfiguration
This table is a way of configuring the jobs through DB entities. This configuration pertains to only batchV2 type of jobs.
| Field | Description | Default value | Recommended value |
|---|---|---|---|
| JobConfigurationId | Unique identifier for the job configuration. Serves as business key | N.A. | Some name that explains the business purpose of the batchV2-JobConfiguration. |
| DataListSize | Used by the work distributors to break the data in batches. Each batch is a List of documents. Each batch will be processed independently by the business logic | 1 | 1 Unless you want to group multiple individual entities together to process them as a batch. Your service should be able to handle multiple entities together if you set a higher value |
| DataFormat | This attribute works in conjunction with DataListSize and will be only applicable when DataListSize=1. If DataListSize=1 and the data needs to be published as a LIST then make the DataFormat=LIST | singleton | singleton Unless you want to group multiple individual entities together. |
| PageMessageType | Intermediate message type used by readers or workdistributors to break the paged data into chunks. The listener will process each page independently. | batchv2ProcessSegment | batchv2ProcessSegment Unless you wish to route your segment messages to a separate intermediate queue. If not specified otherwise, all BatchV2 jobs configured for a component, will share the same batchv2ProcessSegment queue. |
Authors
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
6.7 - Cloud Networking
Introduction
Manhattan Active® Platform is deployed as a distributed application using Google Kubernetes Engine on Google Cloud Platform. When we use Kubernetes Engine to orchestrate the Manhattan Active applications, it’s important to think about the network design of the applications and their hosts.Networking design is critical for architecting the infrastructure because it helps to optimize for performance and secure application communications with internal and external services.
Below are the key networking components we designed and implemented for Manhattan Active® Platform.
VPC
Virtual Private cloud (VPC) is the global private isolated virtual network partition that provides managed networking functionality for each kubernetes cluster. It is the fundamental networking resource created before we deploy the kubernetes cluster. When we create the Google project, a dedicated automode VPC is created, and VPC for each customer environment are unique and independent to restrict access from one environment into another. The network firewall and ACL rules for each environment forbid network-level access across environments. As the VPC mode is auto, automatic subnets are created on the Google region and the kubernetes cluster will use those subnets for creating the cluster nodes.
VPC Flow Logs have enabled for all the VPC, and enabling flow logs records a sample of network flows sent from and received by instances used as Google Kubernetes Engine nodes. These logs can be used for network monitoring, forensics, real-time security analysis, and expense optimization.

Planning the GKE IP address
GKE clusters require a unique IP address for every Pod. In GKE, all these addresses can be routed throughout the VPC network. Therefore, IP address planning is necessary because addresses cannot overlap with private IP address space used on-premises or in other connected environments. The following sections suggest strategies for IP address management with GKE.
- Our cluster type is private, and each node has an IP address assigned from the cluster’s Virtual Private Cloud (VPC) network.
- /24 is the default CIDR block assigned for each cluster node to assign the GKE pods.
- RFC 1918 Ip address range is used for the GKE pods and services.
GKE cluster
Kubernetes clusters created for the Manhattan Active® Platform are private by default. Private clusters use nodes that do not have external IP addresses. This means that clients on the internet cannot connect to the IP addresses of the nodes. It reduces the attack surface and the risk of compromising the workloads. The Master node, which is hosted on a Google-Managed project, communicates with the nodes via VPC peering. The public endpoint for the GKE control plane is not exposed to the outside world, and we have enabled authorized networks by only allowing the secure networks.

Cloud NAT
Private GKE Clusters don’t have any external IP addresses, and all the nodes instances get internal ip addresses by default. Pods running on these node instances can’t access the internet. We are configuring Cloud NAT service to allow private Google Kubernetes Engine (GKE) clusters to connect to the Internet.
Cloud NAT implements outbound NAT (i.e. network translation, mapping internal IP addresses to external IP) to allow instances to reach the Internet. As part of Cloud NAT configuration, we can manually reserve a set of public IP address which would create and release IP based on workloads.
When we integrate the Active Omni or Active supply chain with other third party applications via xbound, which employs IP Whitelisting as part of the access mechanism, we can share the ip addresses of the Cloud Nat instead of sharing the Xbound node pool ip address.

Private Google Access
We have also enabled private Google access by default on the VPC where the GKE cluster has deployed. Private Google Access provides private nodes and their workloads access to Google Cloud APIs and services over Google’s private network.
For example, in all customer environments, Private Google Access is used by clusters to access most of the Google apis.
External communication using Xbound
XBound is a Java, Spring Boot component that wraps Netflix OSS Zuul library to provide an outbound proxy, or router that can forward the incoming HTTP(s) calls to configured external locations. The diagram below explains how the invocation sequence looks:

As shown above, the base (and the custom) components invoke the XBound endpoints, and based on the mapping configuration in XBound, the calls would get routed to the external endpoints. In other words, XBound can also be seen as a “NAT†gateway into the outer world, but with more flexibility and control than a standard NAT configuration that the IaaS providers have.
XBound can run as one or more containers similar to the application components. However, XBound is always configured to run on a separate, exclusive node pool (called xbound-pool). This node pool has special configuration in place to automatically assign static public IP addresses. Having static public IP addresses allows for a possibility of the external location requiring an IP address restriction (such as a firewall allow-list). Do note, that the nodes on which the components run (the components-pool) do not have static IP addresses
Route Configuration XBound uses Spring properties to define the routes using the Zuul routing syntax. See the example below:
zuul.routes.example.path: /example/**
zuul.routes.example.url: https://example.com
In this simple example, calls made to XBound on path /example/... will get routed to the target https://example.com/... . The ... designates the remainder of the path as is. For example:
curl -s com-manh-cp-xbound:8080/example/foo/bar
…will result in the same call being forwarded to…
https://example.com/foo/bar
Here’s another example to better explain the concept (real example that can be tested):
Properties in XBound:
---------------------
zuul.routes.ifconfig.path: /ifconfig/**
zuul.routes.ifconfig.url: https://ifconfig.co
Invocation to XBound (presumably from a RestTemplate in the component code):
----------------------------------------------------------------------------
curl -s com-manh-cp-xbound:8080/ifconfig
Invocation is routed to:
------------------------
https://ifconfig.co
If the invocation of XBound is changed:
---------------------------------------
curl -s com-manh-cp-xbound:8080/ifconfig/ip
Then the target is routed to:
-----------------------------
https://ifconfig.co/ip
HTTP Authentication method for xbound
For HTTP(s) calls that originate from the application components, but reach the target external endpoint without any HTTP(s) authentication mechanism, nothing additional needs to be configured. However, if HTTP(s) authentication is required, then depending on the type of authentication requirement, additional configuration may be needed:
Basic auth: No additional configuration required. The Authorization: Basic header with the base64 encoded credentials is passed as is to the forwarded invocation. In other words, the external endpoint will receive the authorization header as is.
OAuth token: No additional configuration required. The Authorization: Bearer header with the encrypted access token is passed as is to the forwarded invocation. In other words, the external endpoint will receive the authorization header as is.
Certificate based auth: The client cert configuration is supported by XBound. However, this feature is supported only for custom extension requirements, and not for base calls. The reason for this restriction because the client certificates are typically customer specific versus the base application code will need to be client-agnostic.
Edge Service
An edge service is a service that provides an entry point into an enterprise or the network of a service provider. Edge services can be as simple as a stateless router or a switch and as complex as a full-fledged web application that addresses not only routing but also other concerns such as security, authorization, throttling etc.
Edge services typically address one or more of the following concerns
- Network security
- User authentication and authorization
- Network protocol translation
- Payload transformation and/or translation
- Rate limiting and Throttling
- Resiliency
- Performance
Why do we need edge services?
We need edge services for our Active Supply Chain solutions to:
- access the devices (i.e. printers, MHE, RF and touch devices, etc.) on the customer’s facility and on the customer’s network
- translate between network protocols (i.e. TCP, HTTPS, etc.)
- provide a single way to interact with the Active Supply Chain solutions on the cloud
- ensure that customer’s applications and devices contact the Active Supply Chain solutions with adequate security and access controls in place
- improve user experience
Edge service components
These components should:
- communicate with Manhattan Active Supply Chain components (within Manhattan’s VPC) through the public load balancer/gateway using HTTPS protocol
- not contain any configuration data and/or should not serve any UIs or HTTPS services for end users
- communicate internal state and/or transient events to an auditing system hosted on Manhattan’s VPC
- log application logs to an external logging system like StackDriver logging on the Google Cloud Platform (GCP)
Edge Networking
Edge services will be deployed within a Virtual Private Cloud (VPC) on GCP for each facility. This VPC will be peered with the customer’s network at the facility using VPN (IPsec tunnel) or alternative suitable peering mechanisms. Once peered, all the devices on the customer’s facilities network will be discoverable by the edge components for that facility. The following diagram shows the deployment and the network boundaries.

Connectivity to Edge Networking
There are multiple ways to connect the Edge stack and customer network. Cloud VPN and Cloud interconnect are the two options typically used for the connectivity. Cloud Interconnect is an expensive option and generally used for gigabytes bandwidth requirement, whereas Cloud VPN is inexpensive and has enough bandwidth support needed for the SC Edge stack.

Cloud VPN
Cloud VPN securely connects the peer network to the Virtual Private Cloud (VPC) network through an IPsec VPN connection. Traffic traveling between the two networks is encrypted by one VPN gateway and then decrypted by the other VPN gateway.High-Availability is the default options we recommend for all our customers. HA VPN is a high-availability (HA) Cloud VPN solution that securely connect the on-premises network to your VPC network through an IPsec VPN connection in a single region. HA VPN provides an SLA of 99.99% service availability. HA VPN gateway to your peer gateway, 99.99% availability is guaranteed only on the Google Cloud side of the connection. End-to-end availability is subject to proper configuration of the peer VPN gateway.If both sides are Google Cloud gateways and are properly configured, end-to-end 99.99% availability is guaranteed. Default recommended routing model is dynamic and static is not supported.

Google Partner Interconnect
Partner Interconnect provides connectivity between the customer network, and the Edge network through a supported service provider. A Partner Interconnect connection is useful if the client data center is in a physical location that can’t reach a Dedicated Interconnect collocation facility, or the data needs don’t warrant an entire 10-Gbps connection.
Service providers have existing physical connections to Google’s network that they make available for the customers to use. After a customer has established connectivity with a service provider, they can request a Partner Interconnect connection from the service provider. After the service provider provisions the connection, client can start passing traffic between the network by using the service provider’s network. Partner Interconnect supports both Layer 2 and Layer 3 connectivity. Depending on the Redundancy and SLA, we can configure Google partner interconnect on both 99.9% and 99.99% availability.
If customer has a Google cloud presence, then the VLAN adapters for the Google partner interconnect could be terminated on the customer owned Google VPC. Manhattan owned VPC then have to peered with the customer VPC for establishing the connectivity.However, if the customer doesn’t have any Google cloud presence, then the VLAN adapters for Google partner interconnect have to be created on the Manhattan VPC for establishing the connectivity.

Cloud Router
The Cloud Router is the important configuration piece as part of the VPN setup. It is used to dynamically exchange routes between the VPC network and on-premises network through BGP.
By default, Cloud Router advertises subnets in its region for regional dynamic routing or all subnets in a VPC network for global dynamic routing. New subnets are automatically advertised by Cloud Router
Cloud DNS
All the private calls between customer network and Manhattan VPC are using Cloud DNS service from Google for DNS resolution.

DNS peering
DNS peering lets you send requests for DNS records that come from one zone’s namespace to another VPC network. For example, Active SC customer can give Edge stack access to DNS records it manages and similarly, Edge stack can give access for SC customer to DNS records it manages. This is primarily used for all the Edge stack calls going out for Printing and outbound MHE and also the incoming calls for RF and MHE from customer network.

Secured Connectivity GCP Service Using Private Service Connect
Manhattan Active® is offered as SaaS solution to all the customers. We provide access to the application via public URL as HTTPS and an authentication for both user access and application REST calls. There are few customers who wanted to enable a private connectivity between the client network and the mother-ship stack load balancer API endpoints due to the security architecture.

Private Service Connect to access Google APIs
All the Google API calls by default use the publicly available IP address for service endpoints such as pubsub.googleapis.com . Private Service Connect lets you connect to Google APIs using endpoints with internal IP addresses in the VPC network. This architecture is recommended for customers who are expecting all the Pubsub traffic to be private from their host systems.

Secured External Replication

Secured Data streaming
Learn More
Authors
- Giri Prasad Jayaraman: Technical Director, Manhattan Active® Platform, R&D
- Akhilesh Narayanan : Sr Principal Software Engineer, Manhattan Active® Platform, R&D
6.8 - Create Client Custom Rest API in Access Management 2.0
Introduction
In enterprise identity and access management systems, managing clients (also known as applications or service integrations) is a critical capability. While Access Management 2.0 offers powerful admin tools through its console and built-in APIs, there are often scenarios where organizations need customized REST APIs tailored to their workflows, security controls, or automation pipelines.
| Description | Request | Example Response |
|---|---|---|
| Create Client (for password and auth-code grant) | POST https://<stack-name>-auth.<domain-name>/clientsHeader Parameters: - Basic Auth header - Content-Type: application/json Body: { “client_id”: “testclient”, “client_secret”: “******”, “scope”: [“openid”, “profile”], “authorized_grant_types”: [“password”, “authorization_code”], “redirect_uri”: “https://www.getpostman.com/oauth2/callback", “access_token_validity”: 1800 } Note: access_token_validity is in seconds (1800 = 30 minutes). Max 86400 (1 day). | Success: HTTP Status: 200 Response Text: Client (testclient) created successfully under maactive realm. Error: - 401: Authentication Failure — valid token required - 403: Authorization Failure — token must have SystemAdministrator or KeycloakAdministrator role in Org DB - 400: Bad request/Validation error - 500: Internal Server Error Response Text: Client (testclient) creation failed. |
| Create Client (for use with Client Credential Grant) | POST https://<stack-name>-auth.<domain-name>/clientsHeader Parameters: - Basic Auth header - Content-Type: application/json Body: { “client_id”: “testclient”, “client_secret”: “******”, “scope”: [“openid”, “profile”], “authorized_grant_types”: [“service_account”], “access_token_validity”: 1800, “srvc_ac_user_name”: “robot4@test.com” } Note: - access_token_validity: in seconds, max 86400 (1 day)- srvc_ac_user_name: username of existing Robot user in Org component | Success: HTTP Status: 200 Response Text: Client (testclient) created successfully under maactive realm. Error: - 401: Authentication Failure — valid token required - 403: Authorization Failure — token must have SystemAdministrator or KeycloakAdministrator role in Org DB - 400: Bad request/Validation error - 500: Internal Server Error Response Text: Client (testclient) creation failed. |
Client configuration fields description
client_id
Definition:
The client_id is a unique identifier for a client (application) registered with Access Management 2.0. It is how Access Management 2.0 recognizes and distinguishes between different applications or services that want to authenticate and authorize users.
It must be globally unique within a realm and is typically used during login flows, token requests, and API calls.
Usage in OAuth/OIDC Flows:
Passed as a parameter in authorization requests:https://myapp.example.com/auth?...&client_id=my-app&...
Access Management 2.0 uses the client_id to:
- Match client settings
- Apply protocol mappers
- Verify redirect URIs and scopes
Example:
{
"client_id": "testclient"
}
Real-life analogy:
Think of client_id like a badge number at a secure facility:
- Every employee (application) has a unique badge ID.
- The badge helps identify the employee.
- Systems use it to verify identity, enforce access rules, and track activity.
client_secret
Definition:
The client_secret is a confidential key associated with a client in Access Management 2.0. It is used to authenticate the client to the Access Management 2.0 server—typically in confidential clients such as backend services or server-side applications. It is similar to a password and must be kept secret. Leaking it can compromise the security of the client application.
Example :
{
"client_secret": "******"
}
Real-life Analogy:
Think of client_secret as the combination to a secure locker:
- The
client_idtells you which locker to open. - The
client_secretauthorizes you to access it. - If someone knows your combination, they can access your locker—hence why it must be kept private.
scope
Definition:
A scope in OAuth2/OpenID Connect defines what access permissions the client is requesting from the authorization server (e.g., Access Management 2.0). It represents the level of access the client application wants on behalf of the user.
Common Scopes:
| Scope | Meaning |
|---|---|
openid | Required for OIDC — gives access to the ID token |
profile | Access to basic user profile (name, username, etc.) |
email | Access to the user’s email information |
offline_access | Grants a refresh token for long-lived sessions |
roles | Access to user’s roles (if configured in Access Management 2.0) |
Example:
{
"scope": ["openid", "profile"]
}
Real-life Analogy:
Scopes are like access levels on a visitor badge:
- A badge with only
openidlets you into the building (authentication only). - Add
profile, and you can access someone’s name and office. - Add
email, and now you get their contact information too. - Each scope adds more access permissions, just like adding stickers or barcodes to a badge to unlock more areas.
authorized_grant_types
Definition:
authorized_grant_types specifies how a client is allowed to interact with the authorization server to obtain tokens.
These are OAuth2 flows that determine the security context and method of exchanging credentials or tokens.
Common Grant Types
| Grant Type | Description |
|---|---|
authorization_code | Used in server-side apps via a user login (requires redirect URI). Secure. |
client_credentials | Used by machine-to-machine communication. No user login required. |
password | User credentials (username/password) are exchanged directly. Less secure. |
refresh_token | Allows refreshing access tokens without re-authenticating. |
implicit | Used by SPAs (deprecated; less secure). |
Example:
{
"authorized_grant_types": ["password", "authorization_code"]
}
Real-life Analogy: Grant types are like ticket types at a train station:
authorization_code: Reserved ticket bought online — verify ID at pickup (secure, indirect).client_credentials: Company ID badge lets an employee through without a ticket (no user).password: Giving someone your credentials to get a ticket (risky).refresh_token: A return pass you can reuse for a second trip without queuing again.
redirect_uri
Definition:
redirect_uri is the callback URL where the authorization server (e.g., Access Management 2.0) redirects the user after they successfully authenticate.
It must be registered by the client to prevent redirection attacks.
Why It Matters:
- Acts as a security check — only exact matches to registered
redirect_urivalues are allowed. - Primarily used in
authorization_codeandimplicitgrant flows.
Example:
{
"redirect_uri": "https://www.getpostman.com/oauth2/callback"
}
Real-life Analogy:
It’s like telling a delivery person the exact address to return your package after verifying your ID.
If the address doesn’t match the one you registered, the delivery is denied to prevent fraud.
access_token_validity
Definition:
access_token_validity specifies the lifetime (in seconds) of the access token issued to the client after successful authentication.
Why It Matters:
Controls how long a client can access resources before needing to refresh the token.
Balances security and performance — shorter durations increase security; longer ones reduce re-authentication load.
Example:
{
"access_token_validity": 1800
}
Real-life Analogy:
It’s like a time-limited visitor badge at a corporate office — once it expires, you need to go back to reception (authentication server) to get a new one.
srvc_ac_user_name
Definition:
srvc_ac_user_name typically refers to the username or identifier of a service account associated with a client in systems like Access Management 2.0 or OAuth-based identity platforms.
Purpose:
This service account is used when the client authenticates using the Client Credentials Grant, allowing server-to-server communication without end-user interaction.
Note:
srvc_ac_user_name is username of user already existing in Org component. This user needs to be a Robot user.
Example:
{
"srvc_ac_user_name": "robot4@test.com"
}
Real-life Analogy:
It’s like giving a building’s cleaning robot its own ID badge. The robot doesn’t represent a person, but it still needs credentials to enter and operate in restricted areas — just like a service account user enables automated system access without human involvement.
Sample responses from API
Create client with unique clientId

Create client with existing clientId

srvc_ac_user_name is missing

Service Account user is not defined as robot user in orgComponent

6.9 - CUPS overview, setup, and best practices
CUPS is a modular printing system for Unix-like computer operating systems that allows a computer to act as a print server. A computer running CUPS is a host that can accept print jobs from client computers, process them, and send them to the appropriate printer.
Features
CUPS provides a way to decide and control which printers are accessible and used by Manhattan Active® Warehouse Management. Connectivity between the cloud-hosted Manhattan Active Warehouse Management and the on-premises CUPS server(s) is private and secured by firewalls. Customer printer configuration, physical printers, and printer network connectivity are independent of Manhattan Active Warehouse Management.
Setup
Scripts are provided to automate the CUPS provisioning for RHEL (Redhat) and DEBIAN Unix distributions. Instructions are provided below for each case, depending on which OS is selected. All documents mentioned in the below steps are included in the ZIP files provided. It is required that there be 2 CPUs and 32Gb memory for each cups server that is being provisioned.
Install on RHEL VM
RHEL 8 or 9 is recommended:
Create a RH Linux VM and make sure that it has internet access.
Create a directory (e.g., cups_setup) on the VM.
Put cups_cfg.sh, cupsd.conf, and cups-browsed.conf in the directory which was created in step 2.
Log on to the VM, and execute the command below under the directory created in step 2.
a. sh ./cups_cfg.sh
b. * Note: This may take 20 minutes or longer upon the number of packages to install to bring the OS up to date.
Once step 4 is completed, the “/etc/cups” directory is created, and the original CUPS configuration files are backed up as follows:
a. cupsd.conf => cupsd.conf-orig
b. cups-browsed.conf => cups-browsed.conf-orig
Execute the command below to verify the CUPS server is up and listening the port 631
a. # netstat -tulpn | grep 631
tcp 0 0 0.0.0.0:631 0.0.0.0:* LISTEN 18031/cupsd
tcp6 0 0 :::631 :::* LISTEN 18031/cupsd
udp 0 0 0.0.0.0:631 0.0.0.0:* 18041/cups-browsed
Test Web-UI access as follows:
a. For HTTP:
i. http://<host-name or IP>:631b. For HTTPS:
i. In “cupsd.conf”, uncomment "Encryption Required” ii. https://<host-name or IP>:631
Rhel VM Documents: rhel.zip
Install on a Debian VM
Create a Debian VM and make sure that it has internet access.
Create a directory (e.g., cups_setup) on the VM.
Put cups_cfg.sh, cupsd.conf, and cups-browsed.conf under the above directory on the VM.
Log on to the VM, and execute the command below under the directory created in step 2.
a. bash ./cups_cfg.sh
b. * Note: This may take 20 minutes or longer upon the number of packages to install to bring the OS up to date.
Once step 4 is completed, the “/etc/cups” directory is created, and the original CUPS configure files are backed up as follows:
a. cupsd.conf => cupsd.conf-orig
b. cups-browsed.conf => cups-browsed.conf-orig
Execute the command below to verify the CUPS server is up and listing the port 631
a. # netstat -tulpn | grep 631
tcp 0 0 0.0.0.0:631 0.0.0.0:* LISTEN 18031/cupsd
tcp6 0 0 :::631 :::* LISTEN 18031/cupsd
udp 0 0 0.0.0.0:631 0.0.0.0:* 18041/cups-browsed
Test Web-UI access as follows:
a. For HTTP:
i. http://<host-name or IP>:631b. For HTTPS:
i. In “cupsd.conf”, uncomment "Encryption Required” ii. https://<host-name or IP>:631
Debian VM Documents: debian.zip
Initial Printer Configuration
Log on CUPS Web-UI: http://<CUPS-server>:631
Navigate to the Administration Tab and “Add Printer”

- Select a printer protocol (IPP or IPPS) and continue.

- For a label printer, change the socket to the following and continue:

- Fill in the information below and check “Share This Printer”

- For label printing, select “Raw” and continue.

- Select Model as “Raw Queue”, and add a printer with default options:

- For testing select “Zebra” instead of “Raw”

- Select “Zebra ZPL Label Printer” and set it to the default options


- Modify a given printer from Zebra to Raw after testing




Testing and Troubleshooting
Connection testing for Network and firewall:
a. telnet <IP:port>
b. nc -vz <IP:port>
c. curl http://<cups-server-name>:631/printers
d. Run the script provided in the setup ZIP files above “simple_web.sh” to start a web server on CUPS and test the connection
Test CUPS printing server access:
a. Get Access:
i. curl http://<cups-server-IP>:631 OR ii. curl http://<cups-server-name>:631b. List Printers/Queues on CUPS server
i. curl get <cups-server-IP>:631/printers.Test printing jobs from the command line:
a. echo “Hello world! " | lp -d <printer-queue-name> -h <cups-server-ip>:631
Test Printing jobs on a printer directly:
a. Using Bash:
i. cat /path/to/file > /dev/tcp/<printer-IP>/<port>b. Using Netcat:
i. cat file-to-print | nc -w 1 <printer_ip> <port>Retrieve CUPS logs from sys-log (This step required root privilege):
a. journalctl -u cups -e
Take tcp-dump:
a. tcpdump -i any <host source-IP> and port 631 -w /tmp/cups-tcpdump.pcap OR
b. tcpdump -i any dst <dst-ip> and src <src-ip> and dst port 631 -w /tmp/cups-tcpdump.pcap
Best Practices and Recommended Settings
It is possible to hit the maximum number of jobs in the print server during wave runs. To avoid this, the following can be set:
MaxJobs = 2000 (Default is 500 and 0 is (Unlimited))
PreserveJobHistory=Off
PreserveJobFiles=Off
Setting PreserveJobHistory and PreserveJobFiles to off prevents issues due to disk size because of the updated config on MaxJobs.
The following configurations are recommended to mitigate connectivity issues between Manhattan Active Warehouse Management and the CUPS server:
DefaultAuthType = None
Printer Shared for Remote printing = Enabled

Restricted IP Source Allow Edge VPC CIDR
a. Check the cupsd.conf file to ensure that the Edge VPC IP is an allowed host.
Configure the ServerAlias with the hostname in the cupsd.conf file.
Author
- Srinivasan Kalpathi Mahadevana: Architect, Technology Services, PSO.
6.10 - Extension points and handlers
Introduction
Manhattan Active® Platform provides a flexible extensible model for customizing the business workflows via Extension Points. Extension points allow the customer or the Manhattan Professional Services organization to extend the base functionality with little to no code, while supports variety of internal and external integration options for invoking, consuming, and orchestrating custom workflows that meet your needs.
Two key constructs that are embedded in the system design of integrating and executing custom workflows as part of the base flows of Manhattan Active® Solutions:
Extension Points: Manhattan Active® application components have built-in extension points for functional customizations. Callouts to custom services can be configured at these extension points such that the custom services are invoked as part of a base workflow. The custom extension points are available throughout the base application functionality for a powerful extension model. Manhattan also evaluates the need for new extension points frequently and continues to insert them as part of application updates every few weeks. Extension points are designed to handle synchronous and asynchronous call-outs from the base flow, respectively
REST API: Every Manhattan Active® Solution microservices publishes a REST API that handles virtually every business function and “CRUD” operation. Collectively, Manhattan Active® Platform exposes thousands of REST API endpoints which can be used as an instrument for integrating 3rd party systems with Manhattan Active® Platform. The REST API supports the same degree of access control that the Manhattan Active® Platform user interface provides. The REST API comes with Swagger documentation that outline the usage and references.
Extension Point
An Extension Point is a pre-defined hook placed in the base application code at specific places where there’s a potential for customization. Extension Points can be configured to invoke custom services, which are instrumented in - and are invoked as part of - the base code flow at runtime.
- Customizations can be configured at these points as necessary.
- Extension points allows for a powerful execution model to support provides a powerful extension model to support customizations while keeping them external to the base code.
- Requirements for the new extension points are considered and evaluated as part of the development process of the base application, and upon approval, they are delivered as part of the routine code delivery. Once added, extension points are never modified or deleted to preserve the compatibility with the potential implementations of these extension points.
- The configuration that implements the extension point resides in entity called Extension Handler. An extension point can have zero or more extension handlers.
An extension point can be of two types:
Synchronous call-out (User Exit)
- Produces a synchronous call-out at the given extension point. The call-out waits for a response before continuing the base flow.
- While a synchronous call-out (user exit) can be configured with multiple extension handlers, only the first matching handler is executed (see more detailed explanation of how the “matching” is performed in the section below)
- Synchronous call-outs (user exits) are typically added at points in the base code where there is an expectation that a response containing a new or modified payload will be received in response to the call-out.
Asynchronous call-out (Event)
- Produces an asynchronous call-out at the given extension point. Unlike the synchronous call-outs, the call-out does not wait for a response before continuing the base flow.
- Unlike synchronous call-outs (user exits), if multiple extension handlers are configured for an event, all matching extension handlers are executed (see more detailed explanation of how the “matching” is performed in the section below)
- Additionally, base code may also send messages to queue(s) through
ExtPointToMessageType, which are processed after the configured extension handlers are executed. This allows the base application code to execute logic after all potential customizations are executed. This is base functionality and not expected to be customized.
The type of extension point to be introduced in the base code is determined by Manhattan engineering based on the functional and technical requirements, behavior expectations, and throughput calculations.
Extension Handler
Implementation of extension point customization is configured using an entity called Extension Handler. The execution of extension handler is performed as part of the base flow when the base code encounters the extension point. When an extension point is evaluated by the base code, it performs two steps:
- Determines the extension handler(s) to be invoked as configured for that extension point
- Serializes the business objects and the contextual metadata from the current transaction as a JSON object and passes it to the extension handlers. See the extension point documentation to learn more about what business objects and contextual metadata is passed to the extension handlers.
The extension handler, when executed, utilizes the JSON payload sent from the extension point, and performs the custom flows. When the extension handler completes the custom flow, it responds back with a “return” payload - the returned payload may contain modifications based on the customization requirements. The returned payload is only relevant for the synchronous call-outs (http); for asynchronous call-outs, the returned payload is not relevant.
Extension handlers can be added and managed via a REST API for the ExtensionHandler entity. However, it is recommended that the Configurator UI is used to configure extension handlers for a more intuitive graphical experience, detailed validations, and to avoid human errors. See below for an example screen-shot of the Configurator UI.

Extension Handler Configuration
As described below, an extension handler can be configured for a variety of customization operations:
ENTRY CONDITION
- Every extension handler can be configured for an Entry Condition to determine if it is the right handler to execute that call-out. Since multiple extension handlers can be configured at a given extension point, the entry condition serves as a selection criterion to choose the appropriate extension handler for the given business flow.
- Entry conditions can be defined using JSONPath or MVEL expression. Environment variables available in the runtime can also be used in the MVEL expressions using the
{:env_variable_name}format.
PRIORITY
- Priority is an integer number that can be assigned to an extension handler to determine the order in which the extension handlers are sorted for execution of the given extension point. The priority numbers are in ascending order of priority (higher the number, higher the priority).
- Extension handlers with the most stringent entry condition should be given the least priority (the smallest number) to ensure these handlers are executed at the very end.
SERVICE DEFINITION
- Service definition are configured for extension points to invoke internal or external APIs as part of the execution of an extension handler. An extension handler can be configured to use one or more service definitions.
- Service definition are configured via the
ServiceDefinitionentity and are configured and managed separately from the extension handler configuration. The extension handler configuration simply “points” to a service definition created previously. - A service definition can be configured to be of several types:
- URL: calls an HTTP URL. For example,
"Url" : "example.com/some/api?k=v". - RequestMappingUrl: partial URL of the same component in which the extension handler is configured. For example,
"RequestMappingUrl": "/api/ServiceDefinition/inBoundMessageType/search"provides an output similar to an HTTP call, but invokes the underlying Spring bean without making an actual HTTP call. - CompositeService: points to an extension handler and executes it. Do note, that entry conditions of an extension handlers are ignored when it is invoked as a composite service configuration.
- URL: calls an HTTP URL. For example,
Example of a URL Service configuration in the Configurator UI:

SERVICE CHAINING
An extension handler can invoke a chain of service definitions as described above. The chaining is created by feeding the output of a service execution call as the input to the next service invocation.
CONDITIONAL SERVICE CHAINING
Conditional service chains are service chains that include conditions between execution of two services. The condition is defined using the same format as the Entry Condition described above.
Example of conditionally chained service configuration in the Configurator UI:

INPUT TRANSFORMATION
While chaining services, the input to the next service can be transformed using Velocity or Freemarker templates. This is useful for services whose payload structures are not directly compatible. Functionality supports both inline and pre-saved templates.
Example of input transformation with Freemarker template:
![]()
OUTPUT AUGMENTATION
When services are chained, it replaces the whole full payload with the output of a service. In addition, you can also preserve the input payload and augment the new output to it by using the Augment key. An augment key can be any string key in the input JSON payload where the new output payload will be added.
OUTPUT TEMPLATES
A service may produce larger payload than necessary, which could lead to performance concerns. Such payloads can be reduced using response templates. Functionality supports both inline and pre-saved response templates.
OUTPUT QUEUES
Outputs of the services can be posted to a queue at individual services level for further asynchronous processing. Output of the entire extension handler can also be posted to a queue.
SAMPLING
Sampling provides clean visibility into the intermediate results of the services and payloads sent to the queues. As an extension handler can comprise multiple service calls, this feature can be very useful for visualizing payloads and debug at different levels of the chain.
Example of the sampling output:

Learn More
Author
- Shanthosh Govindaraj: Director, Manhattan Active® Platform, R&D.
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
6.11 - Access Management 2.0 Identity Provider UI Field Concepts (OIDC)
Introduction
When configuring an OIDC Identity Provider (IdP) in Access Management 2.0 (where Access Management 2.0 acts as the Relying Party or Service Provider and a third-party system—like Okta, Azure Entra ID, Google—is the Identity Provider), the Access Management 2.0 Admin Console UI exposes a set of UI fields. Here is a detailed explanation of each, with real-world examples to make it concrete:
Redirect URI
Definition:
The URI on the Access Management 2.0 side that the external IdP (e.g., Google, Okta) will redirect back to after a user successfully authenticates.
Access Management 2.0’s Role:
It will send this redirect URI as the redirect_uri parameter in the OIDC Auth Request. The external IdP must be configured to allow this redirect URI.
Example: https://******-auth.cp.manh.cloud/auth/realms/maactive/broker/oidckc/endpoint
Real-life analogy:
It’s like telling Google, “After login, send the user back to this exact Access Management 2.0 URL.”
Alias
Definition:
An internal identifier used by Access Management 2.0 to refer to this identity provider. It is part of the redirect URI above and must be unique.
Used in URL path like: /realms/{realm}/broker/{alias}/…
Example:google or okta-tenant1
Real-life analogy:
Think of it as a unique nickname or code name you use internally to refer to a contact in your phone.
Display Name
Definition:
What shows up on the Access Management 2.0 login screen for end users to select the IdP.
Example:
“Login with Google” or “Enterprise SSO”
Real-life analogy:
This is the label on a doorbell that says “Press here to ring Google.”
Display Order
Definition:
An integer that controls the order of appearance of Identity Providers on the login screen. Lower numbers appear first.
Example:
- Google:
1 - Azure AD:
2
Real-life analogy:
It’s like choosing the shelf position for items in a menu — more important ones go at the top.
Use Discovery Endpoint
Definition:
When enabled, Access Management 2.0 will auto-fetch the OIDC configuration of the IdP using its /.well-known/openid-configuration endpoint.
When disabled, you must enter the endpoints (authorization, token, logout, user info) manually.
Real-life example:
With Google, this would fetch from:https://accounts.google.com/.well-known/openid-configuration
Real-life analogy:
This is like using the metadata file of a system to auto-fill all the fields instead of typing them manually.
Well-Known Endpoint/Discovery Endpoint URL
Definition:
URL where Access Management 2.0 can fetch all necessary OIDC metadata from the IdP: token endpoint, auth endpoint, supported scopes, signing keys, etc.
Example:https://login.microsoftonline.com/{tenant}/v2.0/.well-known/openid-configuration
Real-life analogy:
It’s like the public LinkedIn page of an organization that tells you how to contact them and what protocols they follow.
Available Options for Client Authentication
When Access Management 2.0 (as the RP/client) talks to the IdP’s token endpoint, it must authenticate itself. The options available are:
a. Client ID & Secret (client_secret_basic or client_secret_post)
Most common for confidential clients.
Example:
- Client ID:
my-client - Client Secret:
******* - Sent either in HTTP headers (
client_secret_basic) or in the request body (client_secret_post).
Caution: Never use
"*******"as an actual client secret.
It is often used in examples to mask sensitive data but should never be configured as a real value in any environment.
Doing so would create a serious security vulnerability.
b. Client Assertion (Private Key JWT/Client JWT)
Access Management 2.0 uses a private key to sign a JWT and authenticate with the IdP.
This method is used in high-security environments or when mutual trust is established through certificates.
Real-life analogy:
- Client ID/secret is like a username/password login.
- Client assertion is like showing your digital certificate to prove your identity.
Client ID
Definition:
This is the identifier Access Management 2.0 uses to represent itself as a client to the external IdP.
Example:
If your Okta app’s client ID is 0oa1abcxyz, then enter that in Access Management 2.0.
Client Secret
Definition:
The shared secret between Access Management 2.0 and the IdP used to authenticate Access Management 2.0 when requesting tokens.
Example:
Generated in the external IdP UI when registering the Access Management 2.0 client.
Client Assertion Signature Algorithm
Definition:
When using client assertions (JWT), this setting tells Access Management 2.0 which algorithm to use to sign its authentication JWT.
Examples:
RS256(most common)ES256
Real-life analogy:
It’s like choosing whether to sign your official document with a fountain pen or a ballpoint pen — different formats, same idea.
Advanced Settings
a. Store Tokens
Definition:
This toggle controls whether Access Management 2.0 should store the access token, refresh token, and ID token received from the external Identity Provider (IdP) after successful authentication.
When enabled, these tokens are stored in the Access Management 2.0 user session and can be accessed by applications via Access Management 2.0 token introspection or user info endpoints.
Real-life analogy:
Think of this like keeping a copy of your parking receipt after entering a garage.
If you keep it (store tokens), you can prove you’ve paid and re-enter if needed. If you don’t, you’ll need to go back to the entrance every time for a new one.
b. Stored Tokens Readable
Definition:
This toggle controls whether the stored tokens (access token, refresh token, ID token) can be accessed by client applications using Access Management 2.0’s token retrieval APIs (like the userinfo or token endpoint).
- When enabled: The stored tokens are exposed to applications that request them.
- When disabled: The tokens are stored but not accessible to applications—useful for security or privacy-conscious setups.
Real-life analogy:
Imagine you deposit a sealed envelope at a bank that contains important documents (tokens).
- If the toggle is ON: You give the bank permission to open the envelope and read its contents whenever needed—for example, if a trusted partner requests verification.
- If the toggle is OFF: The bank stores the envelope securely but will not open it or allow anyone else to open it—even if they know what’s inside might be useful.
c. Trust Email
Definition:
When enabled, Access Management 2.0 assumes that the email address provided by the Identity Provider (IdP) is verified and trustworthy. It will not send a verification email to the user.
When disabled, Access Management 2.0 requires the user to verify the email, even if the IdP claim is valid.
Real-life analogy:
Imagine you are at the front desk of a hotel:
- If the toggle is ON: The receptionist sees your company ID badge and immediately gives you a room key, trusting that your employer already verified your identity.
- If the toggle is OFF: The receptionist still asks for your passport and takes a photo, even with the company ID—they want to verify for themselves.
d. Account linking only
Definition:
When enabled, users cannot use this Identity Provider (IdP) to log in directly. Instead, the IdP can only be used to link additional accounts to an existing Access Management 2.0 account (e.g., from the Account Console).
This is useful when you want to let users add external IdPs to their profile for extra login methods but not use them to create or authenticate accounts on their own.
Real-life analogy:
Think of it like adding a backup credit card to your online shopping account:
- If the toggle is ON: You can’t use this card to create a new account or make the first purchase, but you can link it to an existing account for future purchases.
- If the toggle is OFF: The card can be used freely, including to sign up or log in directly.
e. Hide on Login Page
Definition:
When enabled, this Identity Provider (IdP) will not appear as a login option on the Access Management 2.0 login page. However, it can still be used for login if triggered via identity provider hints, authentication flows, or account linking.
This is useful when the IdP should be available only in specific scenarios (e.g., internal flows or dedicated clients) but not visible to all users by default.
Real-life analogy:
Think of it like a “hidden entrance” to a building:
- If the toggle is ON: The door exists, but it’s not visible to the public. Only people who know the path or have a key (like internal staff) can access it.
- If the toggle is OFF: The door is visible and accessible to everyone walking by.
f. First Login Flow
Definition:
The First Login Flow is the authentication flow executed when a user logs in through an Identity Provider (IdP) for the very first time.
This flow defines what steps Access Management 2.0 should perform the first time it sees a user authenticated via an external IdP — such as linking accounts, updating user profiles, setting required actions, or verifying email.
Real-life analogy:
It’s like a new employee onboarding process:
- When someone joins a company (first login), they go through orientation: fill out forms, verify details, and maybe link their personal ID.
- But on every login after that, they just badge in — no need for all the setup.
In Access Management 2.0 terms:
- First login flow = orientation
- Subsequent logins = just checking in
g. Post Login Flow
Definition:
The Post Login Flow is the authentication flow that Access Management 2.0 executes after a user has successfully authenticated, typically through an Identity Provider (IdP).
It allows you to run additional checks or actions after login, such as:
- Triggering user attribute updates
- Enforcing terms and conditions
- Applying custom authenticators
- Adding consent screens
This flow is optional and only runs if explicitly configured for an IdP or client.
Real-life analogy:
It’s like a security checkpoint you pass after entering a building:
- You’ve already shown your ID and entered (authenticated).
- Now, before proceeding, you might be asked to agree to company policies, sign a visitor log, or verify your access level.
So, in Access Management 2.0:
- Post Login Flow = final gate of custom rules after you’ve successfully logged in
h. Sync Mode
Definition:
Sync Mode defines how user data from an external Identity Provider (IdP) (like Azure AD, Okta, etc.) is synchronized with Access Management 2.0’s internal user storage.
There are two main sync modes:
1. Import (Default)
- Behavior: User data is imported into Access Management 2.0’s local database upon first login. Future logins use the locally stored data unless the IdP is queried again.
- Pros: Faster login times, reduced external calls, and local user persistence.
- Cons: Data may become outdated if user attributes change in the IdP.
2. Force (also known as “Legacy” or “Legacy Sync”)
- Behavior: Every login pulls fresh user data directly from the external IdP.
- Pros: Always up-to-date user information.
- Cons: Slower logins, increased dependency on IdP availability.
Real-life analogy:
- Import Mode: Like taking a snapshot of someone’s ID at reception. You use that local copy for future visits.
- Force Mode: Like calling the person’s office every time they arrive to confirm their title and access level.
Mappers
Definition:
Mappers in Access Management 2.0 define how user attributes or claims from an external Identity Provider (IdP) are translated and mapped into Access Management 2.0’s internal user model or OIDC/SAML tokens.
Key Types of Mappers
Identity Provider (IdP) Mappers
Used when federating users from external IdPs into Access Management 2.0.Protocol Mappers
Used when issuing tokens to client applications to control the structure and content of tokens.
Common Use Cases
- Map
emailAddressfrom an IdP to the Access Management 2.0 user’semailfield. - Add custom roles or groups to a user’s token.
- Map LDAP attributes to Access Management 2.0 fields (in LDAP federation).
- Rename or transform a claim before it’s included in a token.
Examples
| Mapper Type | Example Mapping |
|---|---|
| Attribute Mapper | Map emailAddress from IdP to Access Management 2.0’s email. |
| Role Mapper | Map isAdmin=true to assign role=admin in the token. |
Real-life analogy:
Think of mappers like a translator at a conference:
- The speaker (external IdP) says something in one language, like
"username". - The translator (mapper) converts that into a form the audience (Access Management 2.0 or the client application) understands, like
"preferred_username".
Mappers ensure seamless communication between different identity systems and applications.
Permissions
Definition:
Permissions in Access Management 2.0 control 2.0 who can manage or interact with an Identity Provider (IdP) once it is created. These are part of Access Management 2.0’s fine-grained authorization system and are governed by policies, roles, and scopes.
When permissions are enabled for an IdP, Access Management 2.0 applies Authorization Services to enforce access rules.
Example Use Cases
- Restrict who can edit or delete an IdP.
- Limit which users can trigger sync or link accounts with the IdP.
- Hide sensitive configurations (like client secrets) from users without proper roles.
Real-life analogy:
Think of an Identity Provider as a shared printer in an office:
- Some users can only see it in the list.
- Some can print (use it for login).
- Only a few can reconfigure or remove it.
Permissions ensure that only authorized personnel can make critical changes or view sensitive information related to the IdP.
Enabled
Definition:
The “Enabled” toggle determines whether the configured Identity Provider (IdP) is active and available for use in the login flow.
Functionality
Enabled:
Users can authenticate through this IdP. It appears on the login page and is processed normally during authentication flows.Disabled:
The IdP is effectively turned off. It won’t show up on the login page and cannot be used for login unless specifically invoked through backend mechanisms (e.g., custom flows or direct linking).
Real-life analogy:
This is like a light switch for the login option:
- When the switch is ON, users can see the IdP and use it.
- When the switch is OFF, it’s as if the IdP doesn’t exist — invisible and inactive — unless hardcoded elsewhere.
Use this toggle to quickly enable/disable access without deleting the IdP configuration.
End-to-End Real-Life Example: Google OIDC Identity Provider
This is a practical example of how to configure Google as an OIDC Identity Provider in Access Management 2.0.
Alias:
googleDisplay Name:
Login with GoogleDisplay Order:
1Redirect URI: https://******-auth.cp.manh.cloud/realms/myrealm/broker/google/endpoint (Must be added to the Google Cloud Console OAuth client settings as an Authorized redirect URI.)
Use Discovery Endpoint:
trueWell-Known Endpoint: https://accounts.google.com/.well-known/openid-configuration
Client ID/Secret:
Obtain these from the Google Cloud Console when you create the OAuth 2.0 client for Access Management 2.0:Client Authentication Method:
client_secret_post(recommended for most providers)Client Assertion Signature Algorithm (optional):
UseRS256if you are configuring Private Key JWT as the authentication method.
Fields in this Interface and their definitions
Alias: A unique identifier for the Identity Provider within Access Management 2.0.
Display Name: The name presented to users on the login screen.
Redirect URI: The URI where the external Identity Provider will redirect users after authentication.
Use Discovery Endpoint: A toggle to enable automatic retrieval of OIDC configuration from the Identity Provider.
Well-Known Endpoint: The URL used to fetch the OIDC configuration when discovery is enabled.
Client ID and Client Secret: Credentials used by Access Management 2.0 to authenticate with the external Identity Provider.
Client Authentication Method: The method Access Management 2.0 uses to authenticate itself to the Identity Provider.
Client Assertion Signature Algorithm: The algorithm used when Access Management 2.0 signs client assertions.
Mappers: Mappers in Access Management 2.0 are used to transform or transfer attributes and claims from an external Identity Provider (IdP) into Access Management 2.0’s internal user model.
Permissions: Permissions in Access Management 2.0 define access control rules that govern who can view, modify, or manage specific Identity Provider settings and operations.
Enabled: indicates whether the Identity Provider (IdP) is active and available for user authentication.
First login flow: First Login Flow defines the authentication and user setup steps that Access Management 2.0 runs the first time a user logs in through an external Identity Provider.
Post Login Flow: Post Login Flow is the authentication flow that Access Management 2.0 executes immediately after a successful login, used to enforce additional checks or actions like consent screens, condition-based role assignments, or user profile updates.
These fields are integral to setting up an OIDC Identity Provider in Access Management 2.0.
For a step-by-step guide on configuring these settings, you can refer to the official Keycloak documentation.
If you have any further questions or need assistance with specific configurations, feel free to ask!
6.12 - Overview of scheduler features
Introduction
This article describes the features of the scheduler component.
Features of scheduler
One-stop-shop for job related queries
The component-scheduler is the central repository for all job schedules spread across components. scheduler takes care of posting a message to the component specific JobScheduleQueue when a job has to be triggered. The batch framework still holds the responsibility of executing the job, only the scheduling part is delegated to scheduler. As scheduler maintains the schedules and triggers them for all components, we have a better control and visibility of the schedules and their next triggers. To manage this, two new entities have been introduced to store the future runs for a configurable time window (next 4 hours by default) and already triggered jobs.
This is how scheduler triggers jobs for all the components -

High-availability
Even if the master instance of component-scheduler goes down, any other instance can elect itself as a master and continue the job triggers seamlessly. Even if none of the master instances are available at a given point of time, there will be no job triggers for the time it is down and when it is brought up, the pending schedules will be triggered as we have stored them in the DB. So, there is no chance of missing a trigger. At most, it can be delayed a few minutes in case of the component being down.
Scheduler master instance election -

Scheduler internal housekeeping jobs
Scheduler component maintains a few internal jobs that help in maintaining and triggering the job schedules for all the components.
Polling data from components: Runs at 00:00 UTC every day to poll the JobSchedule and JobTypeDefinition from all the components. Even though there is a separate process to relay the updates on JobSchedule and JobTypeDefinition on the fly. This job helps in syncing any delta that could have been missed during the relay.
Create Future Data: Runs at the 10th minute of every hour and creates the future execution backlog for the next 4 hours.
Purge Job Executions: Runs every 6 hrs to purge the JobExecution records which are older than 5 days.
Status monitoring for components: Every component can have some jobs configured that need status monitoring. Scheduler triggers a status monitoring for all the inprogress jobs for a component every 1 minute. Once a job execution has been marked as completed, no further status monitoring would happen.
Abort jobs: If a job execution has not been completed even after the MaxRunDuration has elapsed, the corresponding JobExecution record will be marked as aborted. This job runs every 15 minutes
This is how scheduler invokes the internal housekeeping jobs -

Useful API endpoints
Full initialize: This API endpoint will fetch the JobTypeDefinition, JobSchedule and required OutboundMessageTypes for all “managed” components, given as a comma separated list to component-scheduler and for all organizations and persist them in the component-scheduler DB.
POST : {url}/scheduler/api/scheduler/setup/fullinitialize
Initialize for an Org: This is a lighter version of the full initialize API endpoint and does the initialization for a particular Organization across all managed components.
POST : {url}/scheduler/api/scheduler/setup/orgId/{orgId}
Initialize for an Org and a component: This is an even lighter version of the full initialize API endpoint and does the initialization for a particular Organization for the input component.
POST : {url}/scheduler/api/scheduler/setup/orgId/{orgId}/component/{component}
Please note: this API endpoint is expecting the component short name, not the full component name. For example, if you are trying to use this API endpoint for component-order and organization org1, then you would do so by passing “order” as the component name.
Create future jobs: This API endpoint creates the future job execution records based on the cron expression of the jobSchedule and persists them in the SCH_FUTURE_JOB_EXECUTION table. The offset value should be provided as an integer in minutes.
POST : {url}/scheduler/api/scheduler/setup/createfuturejobs/{offset}
The future calculation will start from currenttime+offset. The offset value essentially signifies the time buffer we keep before recreating the futureJobs. While recreating the futureJobs, if the schedule is supposed to trigger, we might have issues because the same futureJob entry could be getting updated or deleted. The immediate futureJob entries (which fall within the offset period) will remain intact to avoid conflict issues as explained above.
Get the master lock status: As per the Active/Active design, only one of the running scheduler instances will hold the ActiveMasterLock and this instance (master instance) will be responsible for triggering the jobs. The below API endpoint can be used to gather information about the current lock status.
GET : {url}/scheduler/api/scheduler/schedulerLockStatus
View already triggered jobs: The following API endpoint can be used to search for the JobExecution records, where scheduler stores the already triggered executions.
POST : {url}/scheduler/api/scheduler/jobExecution/search
{
"Query": "JobScheduleId='<JobSchduleId>'"
}
Any of the fields can be used for searching the job execution records. This sample takes the JobScheduleId as input.
View upcoming job triggers: The following API endpoint can be used to search for the FutureJobExecution records, where scheduler stores the upcoming triggers for the next 4 hours.
POST : {url}/scheduler/api/scheduler/futureJobExecution/search
{
"Query": "JobScheduleId='<JobSchduleId>'"
}
Any of the fields can be used for searching the job execution records. This sample takes the JobScheduleId as input.
Authors
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
6.13 - Manhattan Active® Supply Chain Intelligence
Manhattan Active® SCI (Supply Chain Intelligence) is a powerful reporting and analytics tool designed to support operational decision-making within the Manhattan Active® solution ecosystem. It allows users to generate ad-hoc reports, create interactive dashboards, and set up alerting mechanisms to monitor key performance indicators. With SCI, businesses can analyze large datasets and gain insights through human-readable reports, helping to streamline supply chain processes. However, its usage is optimized for analytical purposes. For real-time decision making, utilize the dashboards built into the Manhattan Active solution. For data integration and migration, utilize tools like Manhattan Integration Framework and Manhattan ProActive.
6.13.1 - JSON Store Columns in SCI Reports
JSON_STORE column is defined by the source product and is available for use in SCI reports to support various Manhattan Active® SolutionsJSON_STORE in the Data Model
Database Layer (FM):
JSON_STOREis added to all entities where applicable.- Usage is set to Attribute.
- Data type is Character.

Business Layer:
- The
JSON_STOREcolumn is exposed in the Business Layer Query Subject across all packages.
- The
Common JSON Patterns in JSON_STORE
The JSON_STORE column may store data in different structures:
A. Flat JSON
{
"item_id": "I001",
"description": "Widget",
"price": 100.5,
"available": true
}
B. Nested JSON
{
"Fields": {
"Description": "Handle with care",
"extend::Hazmat": true,
"ShortDescription": "Hazmat items",
"extend::ExtCanceled": 2,
"extend::OrderSpecialNote": "newborn baby"
}
}
- Regular columns use
:. - Extended columns use
::.
C. Arrays of Objects
{
"order_id": "O1001",
"items": [
{ "item_id": "I001", "qty": 2 },
{ "item_id": "I002", "qty": 1 }
]
}
D. Arrays of JSON Rows
[
{ "Author": "User1", "Message": "Hello" },
{ "Author": "User2", "Message": "Hi" }
]
Using JSON_STORE in Reports
Step 1: Pull JSON_STORE
Include the JSON_STORE column in the query.
Step 2: Identify JSON Structure
Use a JSON formatter to validate and identify the pattern.
Examples:
- Extract extended note:
JSON_EXTRACT([Shipment JSON STORE], '$.Fields."extend::OrderSpecialNote"')
- Extract description:
JSON_EXTRACT([Shipment JSON STORE], '$.Fields."Description"')

Step 3: Apply JSON_EXTRACT
Modify the query item definition using JSON_EXTRACT.
Native SQL Example
SELECT
SHP_SHIPMENT0.SHIPMENT_ID AS Shipment_ID,
JSON_EXTRACT(SHP_SHIPMENT0.JSON_STORE, '$.Fields."Description"') AS Shipment_JSON_STORE,
SUM(SHP_SHIPMENT0.DECLARED_VALUE) AS Declared_Value
FROM (
SELECT
SHP_SHIPMENT.JSON_STORE AS JSON_STORE,
SHP_SHIPMENT.DECLARED_VALUE AS DECLARED_VALUE,
SHP_SHIPMENT.SHIPMENT_ID AS SHIPMENT_ID
FROM
default_shipment.SHP_SHIPMENT SHP_SHIPMENT
) SHP_SHIPMENT0
GROUP BY
SHP_SHIPMENT0.SHIPMENT_ID,
JSON_EXTRACT(SHP_SHIPMENT0.JSON_STORE, '$.Fields."Description"');
Output

Extraction Examples
- Nested JSON (MaxChatCapacity):
JSON_EXTRACT(ColumnName, '$.EntityLabels.Annotations.MaxChatCapacity')
- Array of Objects:
JSON_EXTRACT(order_json, '$.order_id') AS order_id,
JSON_EXTRACT(value, '$.item_id') AS item_id,
JSON_EXTRACT(value, '$.qty') AS qty
- Array of JSON Rows:

JSON_EXTRACT(EngageChatConversation, '$[*].Author') -- All Authors
JSON_EXTRACT(EngageChatConversation, '$[0].Author') -- First Author
⚠ Limitation: Arrays of JSON rows cannot be directly combined with other columns in Cognos. Prefer using flat JSON or JSON with distinct fields.
Performance Considerations
- Query Complexity: Extracting nested fields requires
JSON_VALUE,OPENJSON, or JSONB operators. - Indexing Limitations: Limited or complex indexing on JSON compared to flat columns.
- Slower Reads: Runtime JSON parsing increases CPU usage.
- Maintenance Overhead: Complex JSON structures are harder to validate and debug.
Best Practices
- Flatten JSON in staging tables before reporting.
- Extract frequently used fields into physical columns.
- Use indexed computed columns (SQL Server) or generated columns (MySQL/PostgreSQL) for key paths.
- Avoid deeply nested arrays in high-volume systems.
- Monitor query performance when applying JSON functions in
SELECTorWHERE.
6.13.2 - SCI Limits and Guidelines
The use of Manhattan Active® SCI (Operational SCI) is limited to the Manhattan Active® solution and its directly related systems. To help ensure optimal performance, default limits have been set as follows:
Default Limits
| Description | Limit |
|---|---|
| Runtime Limits | |
| Maximum runtime for batch/scheduled reports | 30 minutes |
| Maximum runtime for interactive reports | 5 minutes |
| Rows Retrieval | |
| Maximum number of retrieved rows per query | 100,000 |
| Content Retention | |
| Number of report output versions | 1 |
| Number of report history occurrences | 5 |
| Content Removal | |
| Retention period for report output | 7 days |
| Retention period for report history | 7 days |
Guidelines
Additionally, the following guidelines are recommended to maintain optimal performance:
1) SCI datasets should not be refreshed more than every 15 minutes.
2) CSV table extracts should not be used.
3) Raw Data Movement Limitation: Extraction of large amounts of raw data, for example, a CSV or Excel file to feed a data warehouse, is not supported in Manhattan Active® SCI. This immense movement of data affects the performance of conventional reporting use cases. Manhattan Active® SCI is intended only for analytics through the production of human-readable reports and dashboards.
4) Real-Time Mission-Critical Reports are not Supported: Reports are generated using a read-only replica of the production database. While replication is typically near real-time, occasional delays may occur. Reports will always reflect what is currently in the read-replica, but due to occasional delays, they may not accurately reflect the current production data and therefore may not be suitable for reports that require real-time information. Real-time production reports are available within the Manhattan Active solution and utilize the real-time production database.
Some examples of mission-critical reports, forms, and labels are:
- Shipping labels and documents, such as packing lists and bills of lading
- Trucks expecting an SCI report before transporting orders
- Floor-level employees waiting for SCI reports before beginning their operations
- Receiving worksheet to initiate the receiving process
- Printing of packing lists and dispatching of orders (shipments stopping due to the dependency on these reports)
- Assembly line operations halted due to the dependency on the SCI report
5) My Content Folder Limitation: Manhattan Active® SCI offers two folders, namely, Team Content and My Content, for developing reports and dashboards. The use of the My Content folder is generally not supported. After any Manhattan Active® SCI upgrade, the content and ownership of items saved in the My Content folder are not retained. It must not be used as a reliable location to save any reporting object. Items in the My Content Folder must be moved to the Team Content folder.
6) Access Control: Admin-level access to Manhattan Active® SCI is exclusively limited to Manhattan Services and Operations teams to manage Manhattan Active® SCI deployments. Customers are prohibited from accessing the system with admin privileges.
Capacity
Manhattan Active® SCI capacity is measured in runtime minutes per hour.
The SCI capacity is based on the licensed subscription tier as follows:
| Size | MAWM - User Tier | MATM - FUM Tier | MAO - Order Tier | Runtime Minutes/Hr |
|---|---|---|---|---|
| Tier 1 | 25 - 450 | 25M - 75M | 250K - 750K | Up to 150 |
| Tier 2 | 500 - 900 | 100M - 500M | 1M - 9M | Up to 300 |
| Tier 3 | 1000 - 1900 | 500M - 2B | 10M - 45M | Up to 500 |
| Tier 4 | 2000+ | 2B+ | 50M+ | Up to 1500 |
Note: These are intended as monitoring guidelines, and are not mandatory for end users to follow.
Runtime minutes per hour refers to the time spent running all reports within a single hour. For example, if 75 reports are run in an hour, and each report runs in two minutes, then the runtime minutes per hour would be 150.
Performance and Health Dashboard
To help identify and resolve performance issues, Manhattan Active® SCI includes a Performance and Health Dashboard. This dashboard includes the current runtime minutes per hour, listings of long running reports, total interactive and scheduled reports, and much more.
6.13.3 - Manhattan Active SCI Status
Overview
The Manhattan Active SCI Status tracks and monitors the usage of SCI across Manhattan Active® products. It intends to continuously monitor and inform users to take proactive actions for interactive and scheduled reports, performance and configuration-related issues, and long-running reports that signal a potential risk of crashing and avoid downtime.
You can access it by navigating to Team Content > SCI Audit Reports > System Activity > Manhattan Active SCI Status.
Manhattan Active SCI Status contains the date filter which you can use to reflect data accordingly. The following table explains the sections it includes. Some sections comprise links to detailed reports that you can view for more insights and analysis.
Report Prompt
The following table explains the fields on the prompt page of this report:
| Prompt Field | Description |
|---|---|
| Select Date | The default value for this filter is ‘Last 24 Hr’, and you can also select a date from the last 15 days. |
| Report Type | You can select the report type that fetches values from ‘Report reportservice’, ‘ReportView reportservice’, or ‘Exploration queryservice’. |
| Type | You can run the report for Standard and Unsaved reports. |
Report Sections
The following table describes the sections in the Manhattan Active SCI Status report and their color coding parameters:
| Section Name | Description | Color Code for Visualization |
|---|---|---|
| Reports in 24Hrs | This visualization includes two metrics for Interactive and Scheduled reports to capture the number of reports users execute in the SCI instance. Detailed Report: You can access the drill-down or detailed report for interactive and scheduled reports by clicking the links on the numbers. This page provides the report name, timestamp, username, package, execution status, execution time in seconds, and issues. You can also filter the drill-down reports by report name and/or username. | Note: The Interactive and Scheduled report metrics do not have any threshold defined. |
| Failed Reports | This visualization indicates the percentage of reports that failed to generate for the date you select. Detailed Report: This section also contains a link to the drill-down or detailed report that includes the report name, timestamp, username, package, report type, execution time in seconds, issues, error details, and KB link. You can also filter the drill-down reports by report name and/or username. | Green : less than 2% ,Yellow : between 2 and 3% ,Red : greater than or equal to 3% |
| Long Running Reports | This section provides the number of reports that ran for more than two minutes for Interactive and 30 minutes for schedule. Depending upon the data availability, this report displays either a Green check or a bar visualization for a report type as shown in the image. Detailed Report: To access the drill-down or detailed report for interactive and scheduled reports, | Color Codes for Interactive Reports :Green : greater than or equal to 0 but less than or equal to 2,Yellow : greater than or equal to 2 but less than or equal to 5,Red : greater than 5,Maximum: 8.Color Codes for Scheduled Reports:Green : less than or equal to 30,Yellow : greater than or equal to 31 but less than or equal to 60,Red : greater than 60, Maximum: 90 |
| Max Runtime Minutes Per Hour | This section provides the highest execution time in minutes per hour for a day and the time interval when it is at its maximum. | Note: The report metrics do not have any threshold defined. |
| Ad hoc Reports | This section provides a count of all ad hoc or unsaved reports users execute. Detailed Report: You can access the drill-down or detailed report by clicking the links on the number. This page provides the report name, timestamp, username, package, execution status, report type, and execution time in seconds. You can also filter the drill-down reports by report name and/or username. | Green : less than or equal to 2,Yellow : greater than or equal to 2 but less than or equal to 5,Red : greater than 5 |
| Operational Documents | This section highlights the number of operational documents that users execute. Examples of these documents are packing lists, bills of lading, and others. | Red : greater than 0 |
| Multiple Users Same Report | This section provides the number of reports that multiple users execute in an hour of a day. Detailed Report: You can access the drill-down or detailed report by clicking the links on the number. This page provides the report name, timestamp, username, package, execution status, report type, and execution time in seconds. | Green : greater than or equal to 0 but less than or equal to 5,Yellow : greater than or equal to 5 but less than or equal to 10,Red : greater than 10 |
Report Types
The following table summarizes the standard IBM Cognos report types used in Operational SCI and their category in the Manhattan Active SCI Report:
| IBM Cognos Service Type | Report Type | Metric Category/Usage in Manhattan Active SCI Status Report |
|---|---|---|
| Exploration queryservice | Dashboards/Story | Not considered in the MA Active status report |
| Exploration queryservice | Unsaved Report | Adhoc |
| Report reportservice | Unsaved Report | Interactive / Adhoc |
| Report reportservice | Standard Report | Interactive |
| Report batchreportservice | Standard Report | Scheduled |
| ReportView batchreportservice | Standard Report | Scheduled |
| Report promptforward reportservice | Unsaved Report | Not considered in the MA Active status report |
| Report promptforward reportservice | Standard Report | Not considered in the MA Active status report |
Manhattan Active SCI Status

Drill-down report for reports in 24Hrs

Drill-down report for long-running reports

Drill-down report for failed reports

Drill-down report for multiple users same report

Drill-down report for ad hoc reports

6.13.3.1 - Troubleshooting Guidelines
Overview
This document outlines best practices for managing long-running reports, addressing report failures, and efficiently utilizing ad-hoc reporting in SCI. Adhering to these guidelines will help maintain optimal system performance.
Long-Running Reports
A long-running report takes more time than expected to execute.
General Guidelines to avoid long-running reports (interactive and scheduled)
- Understand user requirements: Focus on key metrics/KPIs to avoid unnecessary data, minimizing processing time.
- Limit data retrieval:
- Implement filtering options to restrict the volume of data processed and displayed.
- Enable users to select specific time periods and other necessary prompts before running the report.
- Use summary reports: Instead of detailed reports, create summary reports that provide high-level insights without processing more data.
- Break down complex reports: If a report is complex, consider splitting it into smaller, more manageable reports/sections based on the use case.
- Optimize data sources: After applying the other recommendations and if the report is still slow, connect with MA services to verify the indexes.
Scheduled Reports
- Schedule during off-peak hours: Whenever possible, schedule long-running reports during off-peak hours when system usage is lower. Also, pay attention to the frequency of scheduling.
Failed Reports
Follow the recommendations below to minimize the failures.
Review error messages: Verify the error message and resolve the issue if the failure is self-explanatory.
Attempt to re-run the report: If the failure was possibly a one-time issue, try executing the report again after a brief wait.
Verify data sources: Ensure all required data sources are accessible from the Cognos admin console.
Check report logic: Review any filters, calculations, and joins for potential issues that may cause failures.
Document the failure: Keep a record of the failure, including error codes and any relevant details of the resolution, for future reference.
Ad-Hoc Reports
Ad-hoc reports are generated on a need basis to meet specific business requirements quickly. They allow users to analyze data flexibly and dynamically.
- Leverage existing reports: Before creating a new ad-hoc report, check if an existing report can be adjusted to meet the business needs.
- Limit data scope: Focus on specific datasets relevant to the use case to improve performance and reduce execution time.
- Understand the purpose: Clearly define what is needed from the ad-hoc report to avoid unnecessary complexity.
- Avoid excessive runs: Be mindful of the number of ad-hoc report executions within a short timeframe, as it may affect overall system performance.
- Utilize report parameters: Use prompts effectively to customize reports without creating multiple versions of the same report.
Operational Documents
Operational documents are reports that offer insights into the performance, status, and tracking of various supply chain operations. SCI should not be used for creating or running operational document reports, such as Bills of Lading, Packing Slips, Worksheets, or Manifests.
Multiple Users Running the Same Report
Follow the below recommendations:
- Schedule reports: Encourage users to schedule reports to avoid simultaneous, on-demand generation.
- Use prompts and filters: Implement dynamic prompts and filters to tailor reports to individual user needs.
- Consolidate and standardize reports: Minimize redundancy and ensure that users are running the latest versions of reports.
- Leverage report bursting: Use bursting to generate personalized reports and distribute them automatically.
6.14 - Glossary of key terminology
Manhattan Active® Platform, or simply the “Platform” is the underlying runtime that houses the Manhattan Active® applications’ components, and manages them. For an overview of the Platform, see Manhattan Active® Platform Overview. The Platform is informally called the “Cloud Platform”, “CP” or simply, “Active”.
Manhattan Active® Omni
Part of the Platform, Manhattan Active® Omni provides the business functions for Omni-channel commerce and retail. MAO, as it is known in short, includes several business applications including the Order Management, Customer Engagement, Store Inventory & Fulfillment and Point of Sale. For an overview of MAO, see MA Active® Omni and Enterprise Promise & Fulfill Overview
Manhattan Active® Supply Chain
Part of the Platform, Manhattan Active® Supply Chain provides the business functions for Warehouse and Distribution, and Transportation ecosystem. MASC, as it is known in short, includes several business applications including the Warehouse Management, Labor Management, Yard Management, and Transportation Management. For an overview of MASC, see MA Active® Supply Chain Overview
Manhattan Active® Inventory
Part of the Platform, Manhattan Active® Supply Chain provides the business functions for Warehouse and Distribution, and Transportation ecosystem. MASC, as it is known in short, includes several business applications including the Warehouse Management, Labor Management, Yard Management, and Transportation Management. For an overview of MASC, see MA Active® Supply Chain Overview
Environment
An Environment is an isolated “slice” the Manhattan Active® applications as used by a customer, or a tenant. An environment is a logical “container” of the business workflows, custom extensions and business configuration of the application for the given customer. And hence, it is also sometimes referred to as the customer’s environment. Do note, that while an environment may have a one-to-one relationship with underlying compute runtime in certain cases, an environment in many cases may also share compute resources with other environments stood up for that customer or other customers. However, what the term environment does ensure is the isolation of data and business workflows of a customer from other customers - at rest and in transit. Manhattan Active® Platform deployments also ensure that one environment is not impacted adversely – functionally or in performance – because of a neighboring environment if the compute resources are shared among these environments.
Stack
A Stack is a network-isolated collection of compute and physical or virtual resources of the underlying cloud infrastructure. A stack hosts one or more environments depending on the tenancy definition of the stack. Every stack consists of a Kubernetes cluster, a database, a set of essential services, the application microservices, application configuration, and zero or more custom extension components. In other words, a stack is the physical runtime that hosts one or more logical environments. A stack is accessed and managed by the Manhattan Active® Cloud Operations team.
Microservice
A Microservice is a self-contained, immutable, and portable process that can be built, delivered, deployed, run, and managed in isolation from other processes. In Manhattan Active® Platform, most microservices are written in Java, though some microservices use different implementation technologies and programming languages. All microservices in Manhattan Active® Platform are built as Linux containers, orchestrated via Kubernetes, and are accessible via a REST API.
Component
A “Component” is a term used interchangeably with a “microservice”.
Essential Service
Essential Services are specialized microservices, including 3rd party software such as Rabbit MQ or Elasticsearch, that provide runtime support and system services (such as caching, indexing, messaging, time series storage, configuration management etc.) to the application microservices. Without the essential services, the application microservices may not function or perform properly. And hence the term “essential”.
Application Configuration
Application configuration consists of a set of properties files that are maintained in a Key-Value store (Consul), and are injected into the microservice process’s runtime using native configuration instrumentation techniques (such as Spring Cloud Config). Application configuration is managed and delivered just like the way the application code binaries are delivered to the target runtime. Changes to the application configuration are tracked via the built-in change detection & audit mechanisms.
Auth Server
Auth Server is a microservice deployed as part of Manhattan Active® Platform. It performs the role of intercepting the inbound authentication calls, and processes them by redirecting them to the target identity or authentication system (it could be an external system such as a 3rd party identity provider, or could be Manhattan Active® Platform’s native authentication). Upon successful authentication, Auth Server constructs the necessary service context and OAuth access token, and redirects the invocation to the target application (such as Manhattan Active® Omni, Supply Chain or Inventory). All user interface and REST API invocations must authenticate with Auth Server first before they can reach to the application. Unauthenticated requests are returned with HTTP 401 UNAUTHORIZED status code.
Zuul Server
Zuul Server is a microservice deployed as part of Manhattan Active® Platform. It performs the role of a gateway and a router: all user interface and REST API invocations first reach Zuul Server immediately after authentication, and dispatched to the target application microservice based on statically defined routing configuration. Additionally, Zuul Server also performs the resource grants for the requested resource by the user (or system) submitting the request. Zuul Server will only dispatch the invocation downstream if the requester has the grants to access the requested resource. Unauthorized requests are returned with HTTP 403 FORBIDDEN status code.
Organization
Organization is a microservice deployed as part of Manhattan Active® Platform. It performs the role of the bookkeeping of organization hierarchy, application users, user roles and resource grants, locations (such as warehouses or stores), business units of organizations, and authentication information (usernames, passwords, and PINs) applicable to Manhattan Active® Platform’s native authentication mechanism. Organization provides a user interfaces and API to retrieve and manage this configuration, and is used by many other downstream microservices to utilize organization hierarchy and other configuration in business workflows.
User
A User is someone who uses a Manhattan Active® application. Examples of users include employees in a store or a warehouse, or customer service representatives in a call center, or a corporate executive retrieving the operational report. The users are typically the employees, temporary staff, or contractors of the customer of the Manhattan Active® application.
Robot
Robots are specialized user accounts designated to invoke the Manhattan Active® Platform APIs. Robots can be assigned roles and grants just like the “human” users, except that the Robot users can only access the REST API, and not the user interface of the applications.
Resource
Every “function” (such as an API, user interface, or any other URLs that a user may access) is defined as a resource. Every resource is controlled by one or more permission. A user can only access a resource if they have the permission for that resource. A user can only perform a certain action to a resource based on the permissions given to that resource.
Permission
A Permission is a predefined entity for governing access control. A permission defines the type of access (“read”, “write”, “admin”) a specific resource such as a user interface, or an API of the Manhattan Active® Platform. Permissions are static values that must be added to a role, and granted to a user.
Role
A Role is a collection of permissions such that the permissions can be grouped based on business requirements. Roles may be defined as “corporate administrator”, “user administrator”, “store user”, “CSR”, “cashier” etc. When a role is assigned to a user, the user inherits the permissions defined in the role. Roles can also be hierarchical. Roles are typically defined statically as part of business configuration of the application, but can also be modified as part of the routine operation of the applications. Roles can be managed via the Organization user interface, or API.
Grant
A Grant is the assignment of a role to a user. A grant states what resources a user has, and what a user can do with that resource. Grants are typically added, modified or deleted dynamically as users are onboarded, change their responsibilities or when they are removed from the application. Grants can be managed via the Organization user interface, or API.
Stereotype
In a typical deployment, a microservice could have multiple instances running at any given time. We assign specific responsibilities to every instance by setting a stereotype to that instance. During the runtime, the instance can detect the stereotype value, and behave in a certain way, throughout its life cycle. Stereotype values are predefined such as REST that designate certain instances to process the REST API workload including all HTTP invocations from the user interfaces or external systems, QUEUE_PROCESSOR to process asynchronous messages from queuing systems, and ALL to process both REST/HTTP and asynchronous workload.
Extensibility
Extensibility is Manhattan Active® Platform’s ability to extend or modify the default behavior of an application function. Extensibility is a mechanism using which customers can develop additional business functionality to meet their functional requirements, or can adjust them to work within the existing IT landscape. Such changes to out-of-the-box (“base”) functionality is called a Custom Extension.
Extension Point
Manhattan Active® Platform exposes “hooks” in certain places in the base functional flows where a custom extension is plugged in. These hooks are well documented similar to the APIs, and continue to grow in numbers as Manhattan identifies new requirements. These hooks are also known as the extension points.
Extension Handler
In order to use an extension point, it needs to be attached to some handling configuration such as invoking one or more service, or intercepting the incoming payload and modifying it when that extension point is invoked. The handling configuration is defined as an Extension Handler. The handler can utilize the base API, 3rd party APIs, or other custom extensions. If an extension handler is defined for an extension point, the base code will invoke the configured custom flow at that point. Subsequent execution of base code will make use of the modified payload returned from the extension handler’s response. Extension points with extension handlers could cause performance problems. Performance tests should be performed when implementing extension handlers that may cause execution latency.
Synchronous Extension Handler
Synchronous extensions handlers are a type of extension handler that execute the extension flows synchronously. If a synchronous call-out (user exit) is defined for an extension point, the base flow waits for the response from the handler before proceeding to the next step. If the extension handler modified the payload in transit, the subsequent workflow execution will use the modified payload returned from the extension handler for further execution.
Asynchronous Extension Handler
Asynchronous extension handlers are a type of extension handler that execute the extension flows asynchronously. Events are typically used for “fire and forget” workflows (such as notifications of certain milestones), though they can be modeled to orchestrate a workflow that can handle asynchronous invocations. For example, when a new order is placed, the system can send a message to a queue to notify the recipient about the order creation event. The receiving system (the target that subscribes to the asynchronous message) can in turn invoke additional steps in the workflow with or without modifying the payload.
Custom Extension Components
Custom extension components are microservices developed and deployed in the SaaS environment for meeting a customer’s business requirement. A custom extension component runs custom (Java) code as part of the Manhattan Active® Platform’s cloud runtime, and integrates with the base microservices via REST API or messaging. Do note, that only the Manhattan’s professional services team is authorized to develop and deploy the custom extension components as they require internal knowledge of how the system works and depend on restricted resources that are only accessible to Manhattan employees.
AWPF
AWPF stands for Asynchronous Workload Processing Framework. AWPF is Manhattan’s proprietary framework for abstracting the management of asynchronous communication for individual microservices.
Message
A Message is an asynchronous payload either received by, or sent by, a microservice, and is sent or received using a queuing mechanism such as Rabbit MQ. A message has a producer, and usually, zero or more consumers. A message provides an ability for microservices to communicate to one another asynchronously in one of one-to-one, one-to-many or broadcast fashion. A message has two parts: The metadata about the message, or the header, and the actual message content, or the body. The header contains the envelope information (sender and receiver information, metadata about the message and timestamps). The body contains the business contents of the message.
Message Types
Message Types are configuration entities meant to provide an easy-to-use abstraction for queue naming and other connection details. From a microservice’s perspective, it can either produce some messages or consume some messages. Messages produced by a microservice, are called outbound messages, and messages consumed are called inbound messages. These message types are defined technically as OutBoundMessageType and InBoundMessageType, and are available in the runtime of every microservice.
Message Brokers
Message Brokers are the message queueing services or systems that a microservice can integrate with. Manhattan Active® Platform supports Rabbit MQ and Kafka for internal messaging (messaging between microservices), and Google Pub/Sub or Amazon SQS for external messaging (messaging to- and from- the microservices and external systems).
Transactional Messaging
If there is a need to send a message only when the parent transaction succeeds, we can use the Transactional Messaging. The parent transaction can perform different database updates along with sending the message. There are primarily two resources involved in such transactions: the database and messaging. As the transaction does not span both resources (not JTA), Manhattan Active® Platform has its own way of handling such requirement by first writing the message to a database and then sending it to the messaging service.
Non-transactional Messaging
Unlike the transaction messaging, if a message can be sent irrespective of the presence or completion of a parent transaction, Manhattan Active® Platform also supports Non-transactional Messaging. It does not have the overhead of tracking transactionality of a message.
Message Persistence, or TranLog
Manhattan Active® Platform has a way of storing messages in Elasticsearch for future reference and reconciliation. It is recommended to enable message persistence for only external messages as there could be need for reconciliation later. For message types that do not require reconciliation later, or for other replayable messages, message persistence should be disabled as it could lead to over-utilization of resources and performance issues.
Learn More
Author
- Kartik Pandya: Vice President, Manhattan Active® Platform, R&D.
- Subhajit Maiti: Director, Manhattan Active® Platform, R&D.
- Shanthosh Govindaraj: Director, Manhattan Active® Platform, R&D.
6.15 - UI-based Automated Tests
There are times when it may be beneficial to create UI-based automated tests for specific flows within Manhattan Active® solutions. This is a common and accepted practice.
Warnings
Creating UI-based automated tests that traverse HTML to find UI widgets should be undertaken with a few warnings and precautions:
- HTML elements and widgets are NOT guaranteed to be consistent across releases. They are NOT guaranteed to be backward compatible.
- If HTML traversal and searching are required for automated tests, the
data-component-idHTML attribute should be the most consistent across releases. - HTML element changes, including those to
data-component-id, are not published in the release notes.
Author
- Ryan Rupp: Sr Director, Manhattan Active®, R&D.