Manhattan Active® Platform Release Engineering
Manhattan Active® Platform Release Engineering is a subsystem consisting of processes, conventions, and a set of tools that enable the transit and promotion of code from a developer’s laptop to a production environment. This document describes the inner workings of this subsystem.
Release Engineering consists of two main aspects:
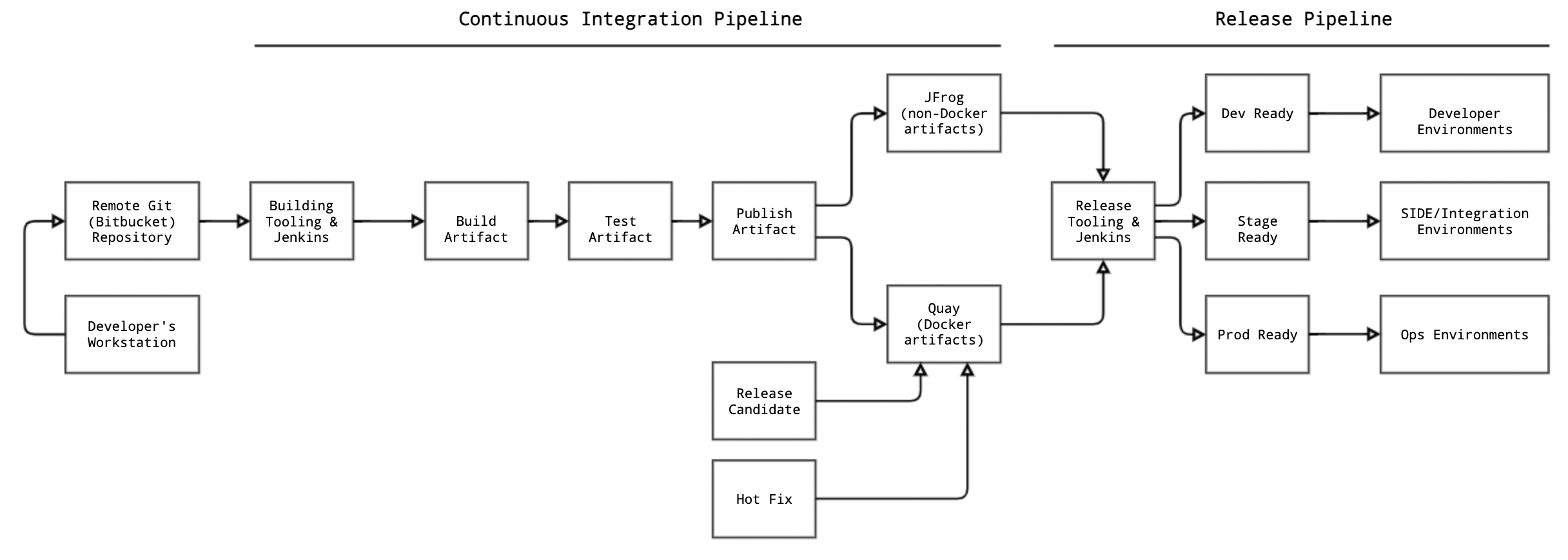
- Continuous Integration Pipeline: Covers how code committed to Git (Bitbucket) repositories goes through various stages of build and test phases to become production ready. Code is built and released as deliverable binary artifacts (i.e. Docker images, NPM packages, JARs or Zip archives)
- Release Pipeline: Covers how the built artifacts are formally released and delivered for deployments in the target runtime. Release mechanism includes routine code delivery to the target runtimes (known as Code Drops) or are priority patches that may be released on demand (known as Hotfixes).
Continuous Integration
The typical development process can be summarized as the following:
- Every microservice has a separate codebase in its own Git repository
- Every development team works on the microservices they are responsible for and push the changes to the respective feature branches
- The continuous integration pull request process builds and tests the code from the feature branches
- Upon successful build and tests, the development team merges the code to the mainline (trunk or “master”)
- The continuous integration process then builds and tests the code from the trunk, builds the Docker image, and publishes to a private Docker registry
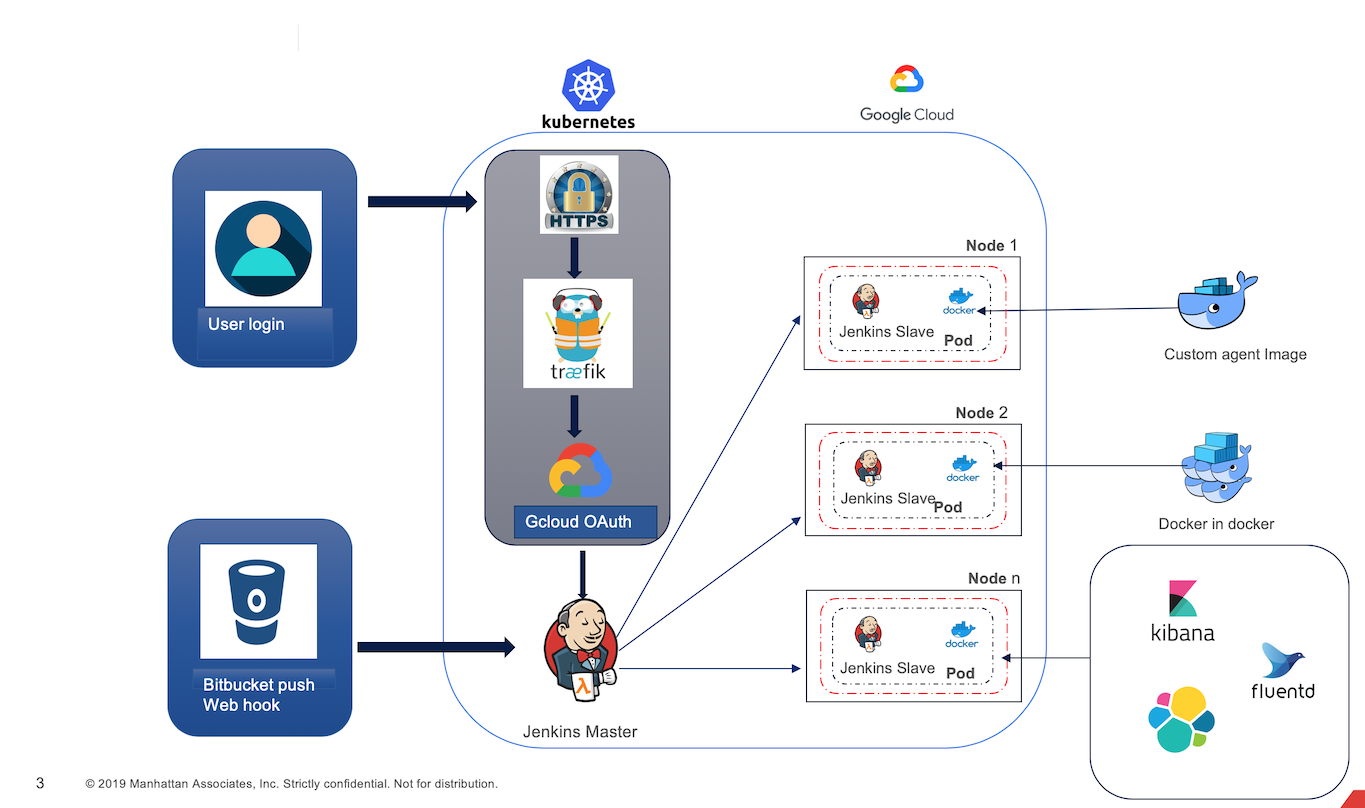
In order to be able to build and test the code that developers commit to the Git repositories, we have put in place the Continuous Integration process using Jenkins.
Jenkins Deployment Topology
The topology has been designed in a way to maximize inbound traffic while ensuring the security and stability of the CI subsystem. Jenkins is deployed on a Kubernetes cluster, with the worker (“slave” in Jenkins-speak) nodes being the Kubernetes pods that are dynamically provisioned when the build event occurs.
Key features of the CI pipeline with Jenkins:
- Runs on Kubernetes for high scalability and performance
- Runs an average of 600+ builds per day, or over 4000 builds in a week
- Supports building, testing, and packaging framework libraries, Docker containers CDN deliverable packages, mobile builds and generic zip and tar archives.
- One click deployment of Jenkins cluster using Kubernetes with all configuration
- Automated node provisioning using preemptible virtual machines for cost optimizations
- Blue-green deployment support for Jenkins cluster
- Auto-renewal of SSL certificate
- Multi-zone high availability of the worker nodes
Continuous Integration Pipelines
Continuous Integration Pipeline is the backbone for the release engineering process during the development cycles and responsible for building, testing and publishing the standard artifacts (i.e. Docker images, NPM packages, WAR, JARs or Zip archives). CI pipeline uses Jenkins multi-branch pipeline jobs to perform various tasks specific to the target Bitbucket repository. The pipeline serves for components and as well as the frameworks. This section summarizes a set of CI pipelines that are most relevant to developers:
Component pipeline
The component pipeline job runs once for each component, and is triggered when a new commit is pushed to the target branch of the component’s Bitbucket repository. The component pipeline job monitors a set of known branch name patters for which a build will be automatically triggered:
master Branch
Purpose of the component’s master branch pipeline is to build and test the component’s code from its master branch where the code from other branches is merged and integrated. Only the artifacts built, tested and published from the master branch are prompted as release candidates, and subsequently released for the downstream deployments, including the Ops managed customer environments. One exception to this rule is the priority (also known as “Hot Fix” or “X” pipeline, described in “priority Branch” section below) where code from a branch other than the master branch is promoted to downstream environments for the purposes of addressing priority or “hot” defects.
Commits pushed to the master branch of the component’s Bitbucket repository triggers the pipeline job, which goes through the phases as summarized below. Clicking on each phase shows the list of activities and logs performed by that phase:

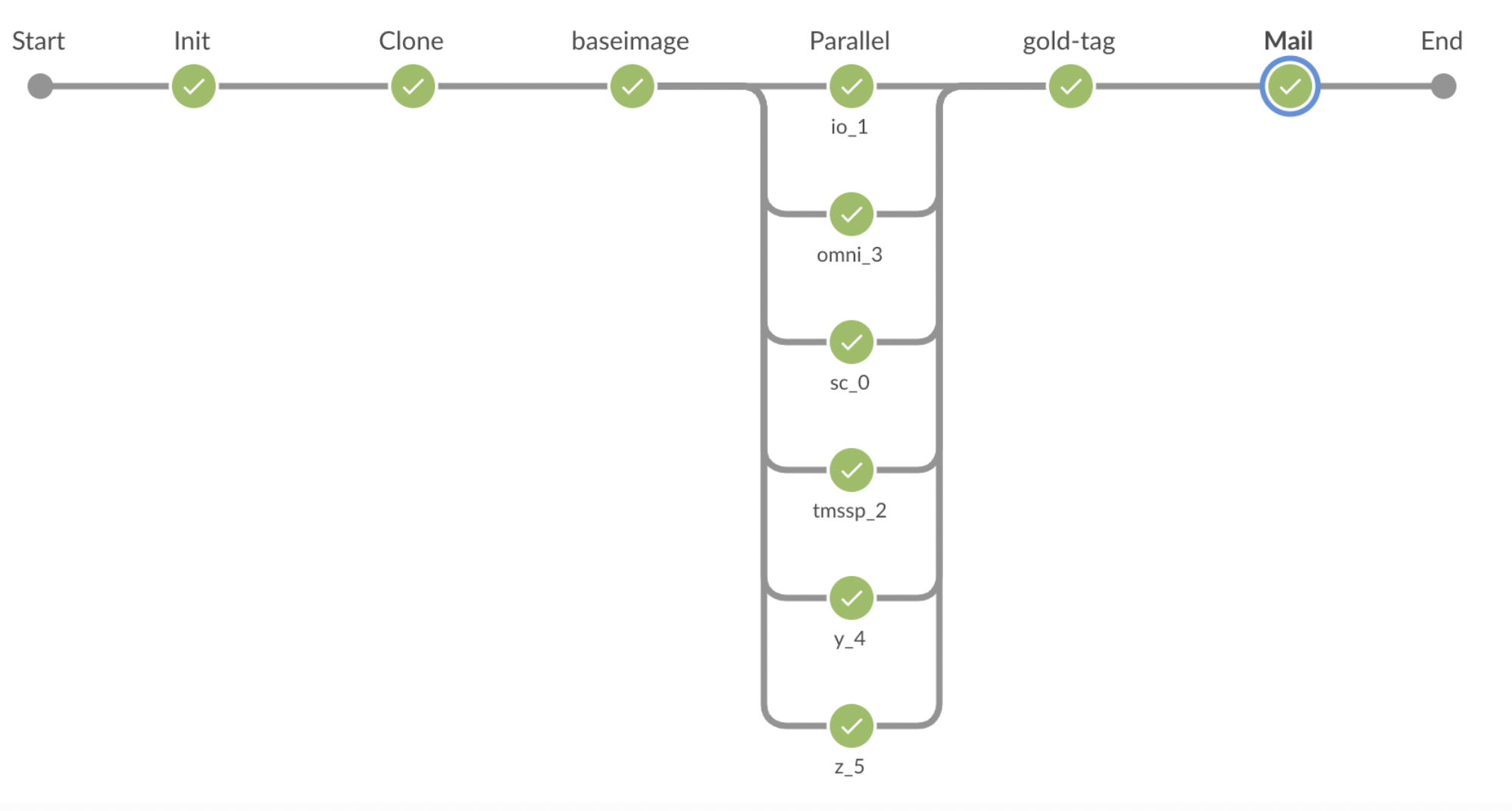
Phases
Init: Initializes the job and the workspace for the job
Clone: Clones the target component’s repository at the tip commit of the master branch; records the tip commit ID, which will be used for tagging purposes
BaseImage: Builds the Docker image for the component. The built Docker image is then tagged as base-<commit_id>-<build_number>, and pushed to Quay.io. This image is then used in subsequent phases. Note, that the Docker image is never built again in the entire pipeline. The same Docker image built in this phase then “travels” through the rest of the pipeline, and upon successful completion of the pipeline, the same Docker image is tagged as gold and pushed to Quay.io
Parallel: Two identical phases (Parallel-Y and Parallel-Z) are triggered in parallel. Both phases run identical set of tests with the only difference being the value of
ACTIVE_RELEASE_IDenvironment variable. This phase runs the full suite of tests that accompany the components, which typically includeBASIC,EXTENDEDandEND-TO-ENDtests (components can customize which of these types of tests to run or skip via theirJenkinsfileusing relevant parameters).Parallel-Y: This parallel phase is also known as the “Y Pipeline”. This phase runs the identical set of tests as the Parallel-Z phase, but with the
ACTIVE_RELEASE_IDset to the most recently released (“GA”) release identifier. For example, if the most recently released quarterly release is 19.3 (or 2019-06), then the global environment configuration for Parallel-Y phase will haveACTIVE_RELEASE_ID=2019-06. By setting theACTIVE_RELEASE_IDto the most recent GA release identifier, the tests in this phase will use the feature flags configured to be enabled for that release. In other words, with the example of the 19.3 release, Parallel-Y phase runs the component’s tests assuming the feature flags for the 19.3 release are enabled, but the feature flags for the upcoming 19.4 release are disabled. For full details on how feature flags work, see this document.Parallel-Z: This parallel phase is also known as the “Z Pipeline”. This phase runs the identical set of tests as the Parallel-Y phase, but with the ACTIVE_RELEASE_ID set to the upcoming quarterly release identifier. For example, if the most recently released quarterly release is 19.3, then the upcoming quarterly release is 19.4 (or 2019-09). In this example,
ACTIVE_RELEASE_IDfor the Parallel-Z pipeline is configured as 2019-09, which would enable all feature flags for this release for the tests that run in this phase.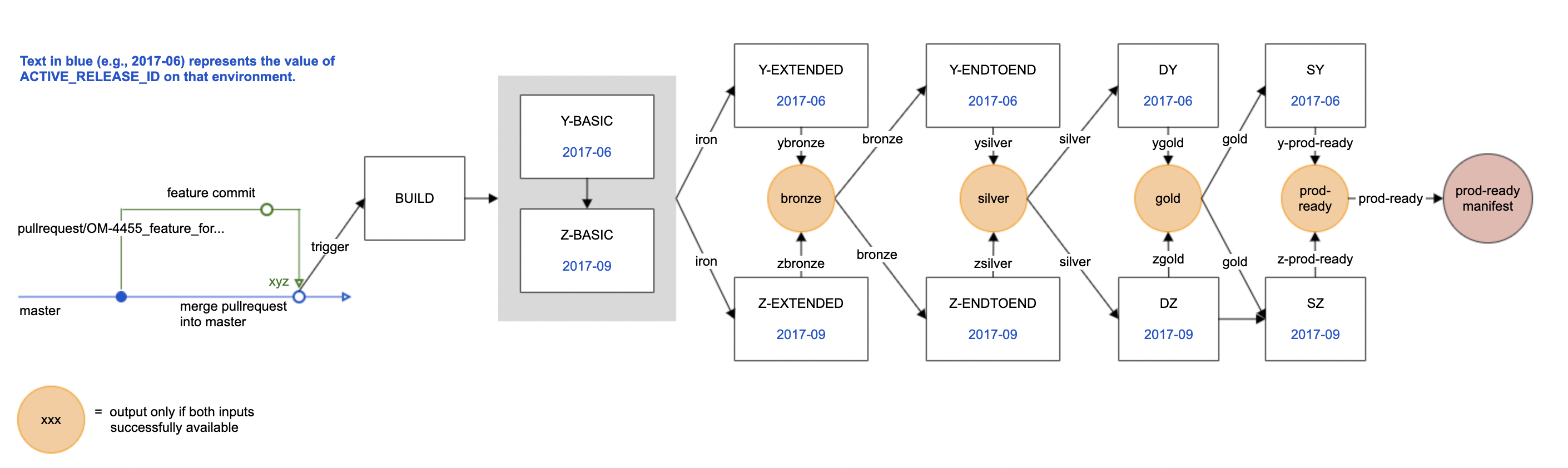
- BASIC tests: Include the component’s unit tests
- EXTENDED tests: Include the component’s functional integration tests that require the component’s dependencies to be running. As part of this phase, the
component is launched using
launchme.sh, and the dependencies are launched using launch-deps.sh before the tests are executed. - END-TO-END tests: Include the component’s end-to-end functional scenarios that span across more than 2 dependencies. These tests are typically designed to cover system-level integration scenarios, rather than testing the component’s functionality in isolation.
GoldTag: Upon successful completion of all (100%) tests, the base-<commit_id>-<build_number> image built as part of the BaseImage phase will be tagged as gold. The gold tag of the component’s Docker image is then pushed to Quay.io. Along with the gold tag, the component’s client libraries, if enabled in the component’s
Jenkinsfile, is also published to JFrog.Mail: An email notification is sent out to DL_R&D_CI_NOTIFICATIONS alias with the status and links to the Jenkins pipeline.
Support for additional parallel phases as part of the component’s CI pipeline: Certain components require additional test phases to run in parallel in addition to the standard Parallel-Y and Parallel-Z phases depending on the spring profiles configured in the configuration repository as different profiles for the component.
pullrequest Branch
Purpose of the component’s pullrequest branch pipeline is to build and test the component’s code from the given pullrequest branch. The built artifacts are never promoted to downstream environments, but provides a way for the developers to build and test their code before merging the code into the master branch. Commits pushed to any branch named pullrequest/<some_suffix> to the component’s Bitbucket repository triggers the pipeline job, which goes through the similar phases mentioned above for master but without any parallel phase. Upon successful completion of the pipeline, the docker image created in the BaseImage phase is tagged as pr-gold and pushed to Quay.io.
While the default behavior of the pullrequest branch pipeline is to execute each of the pipeline phases described above, the developer has control over what all phases are actually executed if a different behavior is desired. A developer, while making the commit, can insert a tag (defined for each phase ) to control what build phases have to be executed.
priority Branch
Purpose of the component’s priority branch pipeline is to enable developers to make priority bug fix on a previously released Code Drop which is presently deployed in production environments. Typically, the defects that cause work-stoppage or result in a significant loss of productivity at the customer is considered a Priority bug, and is usually escalated to the levels of senior executives. When a Priority bug is reported, the expected time window of fixing it and deploying the fix in the production environment is very short (12 to 48 hours, typically). The Priority Bug-Fix Pipeline will help the development team with a quicker turnaround for producing a bug fix for such a defect.
Commits pushed to any branch named priority/<code_drop_id> to the component’s Bitbucket repository triggers the pipeline job, which goes through the similar phases mentioned above for master but without any parallel phase. Upon successful completion of the pipeline, the docker image created in the BaseImage phase is tagged as xgold and pushed to Quay.io.
future Branch
Purpose of the component’s future branch pipeline is to build and test the component’s code from the given future branch. It allows for the developers to “branch out” the code from master for significant changes or enhancements that may not make it back into master for a considerable period of time, or perhaps, never. In concept, future branch pipeline is akin to pullrequest branch pipeline, but the future branch pipeline acts and works more like its master counterpart by going through the same detailed build phases as the master branch. The primary difference between the master branch pipeline and future branch pipeline is that the artifacts produced from the future branch are never promoted to a release or deployment to downstream environments.
Commits pushed to any branch named future/<some_suffix> to the component’s Bitbucket repository triggers the pipeline job, which goes through the similar phases mentioned above for master. Upon successful completion of the pipeline, the docker image created in the BaseImage phase is tagged as fgold and pushed to Quay.io.
Framework pipeline
The framework pipeline job runs once for each component, and is triggered when a new commit is pushed to the target branch of the framework’s Bitbucket repository. The framework pipeline job monitors a set of known branch name patters for which a build will be automatically triggered:
master Branch
Purpose of the framework’s master branch pipeline is to build and test the framework’s code from its master branch where the code from other branches is merged and integrated. This branch publishes the artifacts i.e. JARs, which will be consumed by the components.

Release & Maintenance Branch
Purpose of the framework’s Release & Maintenance branch pipeline is to maintain and publish a specific version of the framework JARs. The build process is same as master.
Release Engineering
At the end of the continuous integration pipeline, a microservice Docker image is tagged as a Release Candidate or rc. The RC-tagged Docker images go through a series of production assurance validations. These validations include upgrade tests (to ensure compatibility between versions), user interface tests (to test user experience and mobile applications) and business workflow simulations (to ensure that the end-to-end business scenarios continue operating without regressing). If regressions are found, they are treated as a critical defect and either addressed or toggled off using feature flags so that the code can be released without the regression of the functionality.
Release Candidates
As explained above in the master branch build section for the application components, the commits pushed to the master branch of a component’s repository results in a build pipeline, at the end of which, the newly built (and tested) Docker images is published with two tags to Quay.io:
Gold tag: com-manh-cp-<component_short_name>:gold (for example: com-manh-cp-inventory:gold); and
Absolute tag: com-manh-cp-<component_short_name>:
While gold tag designates a component’s Docker image as a “stable” image, it still is not considered ready for release until it goes through additional functional and performance testing. Each component team is responsible to test the gold tagged images (commonly, but incorrectly referred to as “gold image”) and declare readiness of that image for release. This is performed by the means of the rc tags. The component teams test the gold tagged image, and upon successful validation, tag the same absolute version as rc using an automated job. In other words, when a Docker image is rc tagged, for a short period, there will be 3 tags, all pointing to the same physical Docker image: gold, absolute tag and rc.
Deployment Metadata
Metadata about every deployment artifact that gets delivered to Operations, and deployed in the customer stacks is maintained as a YAML file in release-pipeline repository. The metadata is managed as 5 categories:
cattle: The application components
pets: The essential services
configuration: The application and deployment configuration
binaries: The mobile app builds and Point of Sale Edge Server binaries
infrastructure: The infrastructure tools that are used for the purpose of deployment and environment management Each entry in the metadata is (unsurprisingly) called a “metadata entry”. Each metadata entry defines a few attributes:
- name: Fully qualified name of the deployment artifact, such as com-manh-cp-inventory , ma-cp-rabbitmq or manh-store-android.
- shortName: Short name of the deployment artifact, such as inventory, rabbitmq or manh-store-android.
- repository: The Bitbucket repository name of the deployment artifact
- groups: One or more groups that this deployment artifact belongs to. If a component is in all group, it will be considered part of every group. For more details see the following section.
- runtime: One or more runtimes that are supported by this deployment artifact. Most artifacts support docker and jar runtimes. However, for some special cases, the artifacts can also support war runtime (such as POS Edge Server).
- platform: One or more platforms that are applicable by this deployment artifact. Supported values are one or more of aws (deployments on AWS/ECS), Kubernetes (deployments with GCP/GKE/Rubik) and side (SIDE deployments)
- containerPort: The port on which the application “inside” the Docker container listens to HTTP traffic
- virtualPort: The host’s port on which the Docker container listens to HTTP traffic (applicable only for SIDE deployments; on ECS and Kubernetes, the port value is assigned dynamically by the underlying orchestrator)
- hasDb: true if the deployment artifact has a Database dependency; false otherwise.
- importance: Relative importance of this deployment artifact. Value must be between 0-9. This value is used to decide the priority class of the deployment in Kubernetes - artifacts with more importance are less likely to get preempted.
- resourceLimit: Memory requests (container memory and JVM -Xmx) for the deployment artifact
- environmentVariables: Any additional pre-configured environment variables that the deployment artifact may need at runtime (deprecated - do not use) The deployment metadata is used to generate deployment artifacts for the target deployment. Sidekick provides APIs to fetch list of deployment artifacts based on the values of group, platform and runtime. The fetched list is then used by the deployment tooling to create the deployment specifications (such as docker-compose.yml for SIDE instances, or Kubernetes spec files for Rubik deployments).
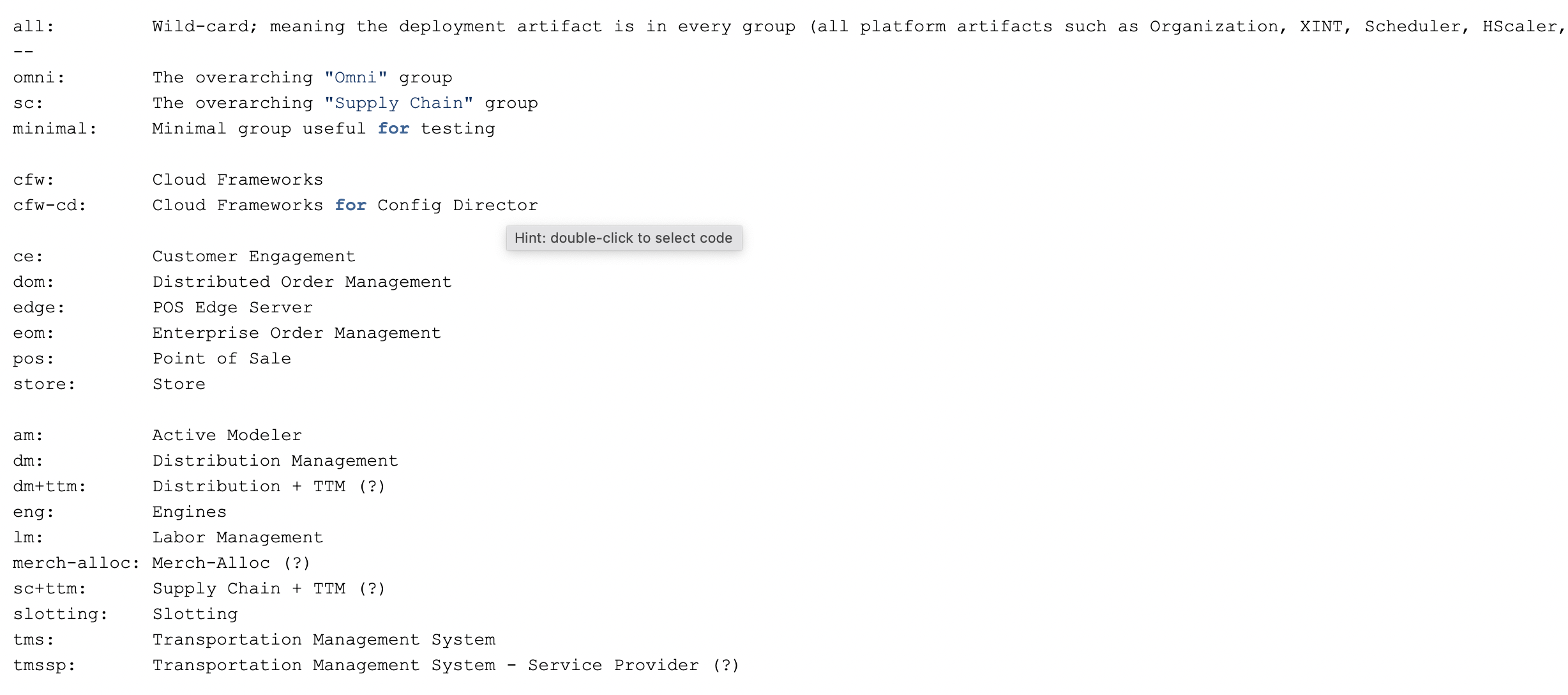
Groups
The group attribute for the metadata entry for each deployment artifact contains one or more values. By associating a deployment artifact to one or more groups, the artifact declares that it “belongs to” any of those groups. The “group” is an arbitrary value and not a predefined enumeration of values. However, each group value must be meaningful in the context of Manhattan products. Currently, the following groups are defined by one or more deployment artifacts
Code Drops
Manhattan Active® Platform Code Drops are the instrument by which the development team deliver the set of deployment artifacts to the Cloud Operations team (and for internal use, to services teams). A code drop is a manifest, or a “bill of lading” containing the set of deployment artifacts, and their versions that are being released as part of that code drop.
Code Drop Manifest
Every code drop manifest consists of 4 sets of deployment artifacts:
- Docker images of the application components (affectionately known as the “cattle”), essential services (or “pets”) and infrastructure (or “rancher”) tools. See Deployment Units for the detailed description of the “Pets and Cattle” analogy.
- Configuration zip containing the archived form of the configuration repository.
- Mobile App binaries representing the application mobile apps. In general, the “binaries” can be used as vehicle to release any form a binary, not limited to the mobile apps. But the current purpose of the binaries is to include only the mobile app binaries.
Types of Code Drop Manifests
A code drop can be released as one of the three flavors:
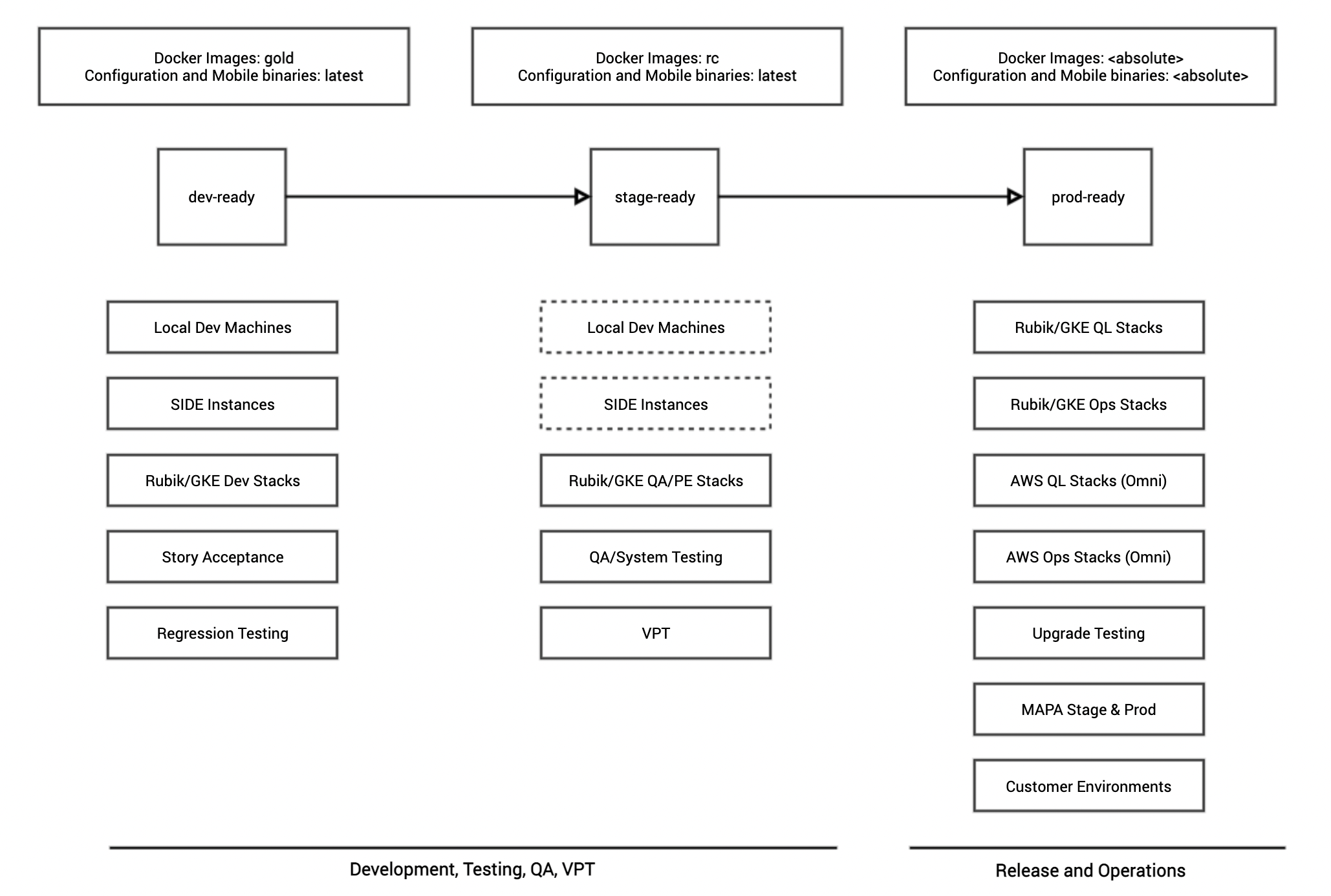
dev-ready: A code drop that is only used for internal purposes, and for development only. The dev-ready code drop manifest contains the same set of deployment artifacts, but their versions are marked as gold (for Docker images) and latest (for Configuration zip or mobile app binaries). This allows the application teams to take a dev-ready drop for their development environments or other internal environments, while ensuring that the standard set of deployment artifacts are all available.
stage-ready: A code drop that is only used for internal purposes, and for development or QA, or for staging the release before it is promoted to downstream environments. The stage-ready code drop manifest contains the same set of deployment artifacts, but their versions are marked as rc (for Docker images) and latest (for Configuration zip or mobile app binaries). This allows the application teams to take a stage-ready drop for their development environments or other internal environments, while ensuring that the standard set of deployment artifacts are all available.
prod-ready: A code drop that is only ready to be released to Operations and for promotion to downstream environments. The prod-ready code drop manifest contains the same set of deployment artifacts, but their versions are marked as the actual release ready versions for Docker images, Configuration zip and mobile binaries. At the time of the code drop event (typically at the end of the 2-week period after completing the necessary testing and validation activities with the deployment artifacts from the stage-ready manifest), the absolute versions of then-current rc tags of the Docker images, most recent Configuration zip file and mobile binaries are recorded in the prod-ready manifest. So, as an example, when we prepared the code drop 2.0.60.x on September 27, 2019, the stage-ready versions of the deployment artifacts were recorded as absolute versions, which produced a prod-ready manifest as shown in the example below (compare it with the snippets shown above for dev-ready and stage-ready manifests - they look nearly identical, except for the difference in the versions):
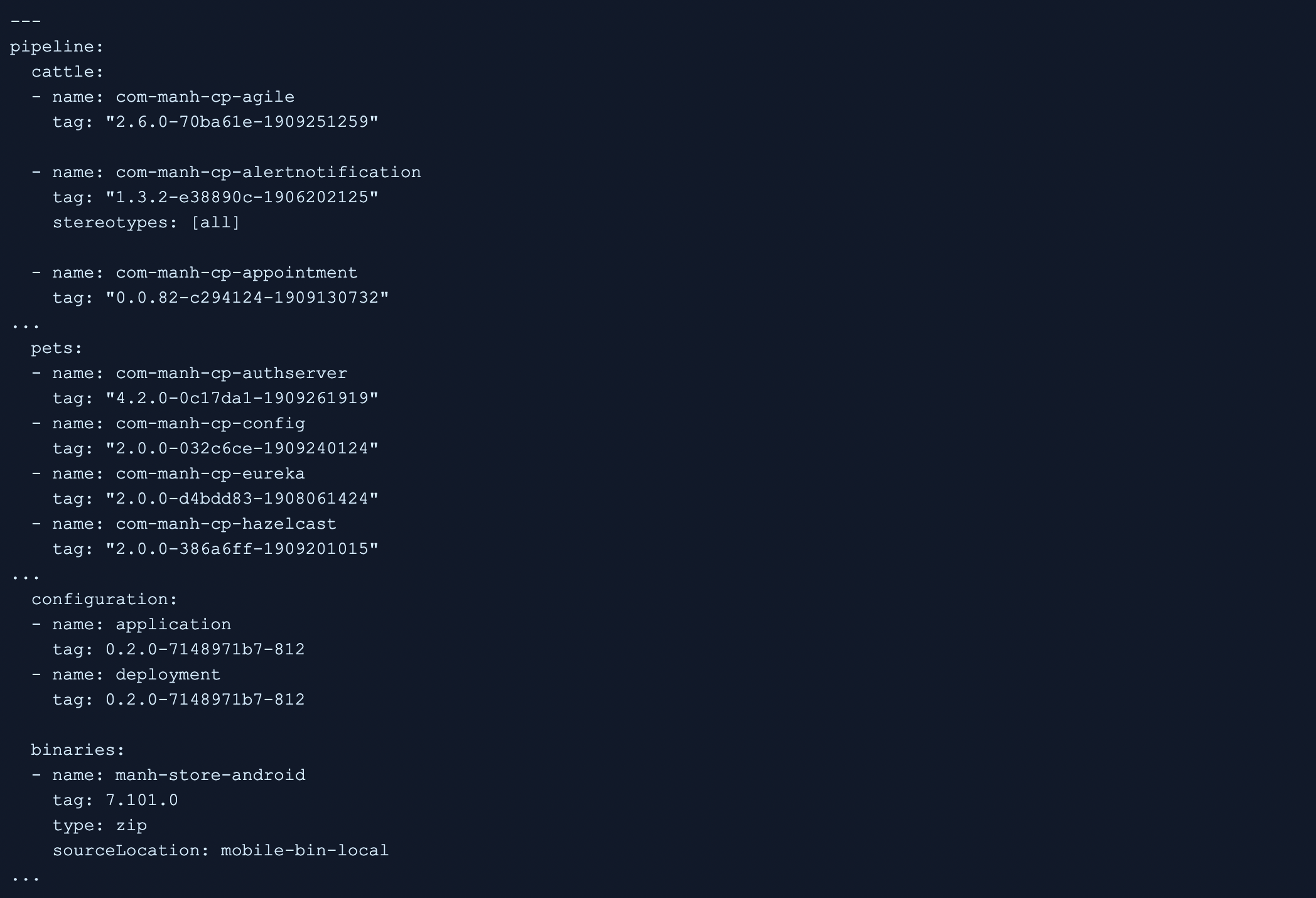
By recording the absolute versions at a given moment, we essentially “lock down” the versions that will be released to the Operations team. This allows the development team to release a precise and static set of versions across the deployment artifacts. In contrast, the dev-ready and stage-ready manifests point to a more “fluid” gold or rc tags, respectively, which are dynamic in nature by design.
Code Drop Version Convention
To identify a prod-ready manifest, or a code drop that is delivered to Operations team, a specific versioning convention is used that includes 4 digits: 2.0.XX.YY, where XX and YY are two-digit numbers. The digit XX represents the Code Drop number, and YY represents the Hot Fix number for that code drop. For example, prod-ready manifest identified as 2.0.59.0 is the original manifest for the Code Drop 59. However, when updated to 2.0.59.1 or 2.0.59.13, the last digit represents the Hot Fix # 1 or # 13 in the code drop 59, in this example.
Code Drop Workflow
In summary, the dev-ready, stage-ready and prod-ready manifests follow the workflow as described in the diagram below:
Hot Fixes
As explained in the Code Drop section above, the bi-weekly releases and the shipped manifest are part of a recurring process, and hence scheduled events. However, there are times when high priority CIIs (usually to report high or critical impact defects, or to ask for other time-sensitive changes) are reported by the services team, Operations or the customers (including the internal customers such as the PA or Sales). The requester may not be able to wait for the requested changes until the next code drop to be released and deployed in their environments. In these cases, upon approvals by senior leaders of the application teams (usually at least a Director-level lead), a change may be allowed to be released as a “Hot Fix” on the most recently shipped code drop.
Example of a Hot Fix
A Hot Fix request is typically reacted by delivering a Docker container (if the desired change was made in an application component or an essential service), a new Configuration zip (if the change is in the configuration repository), or a new mobile binary. Regardless of the type of deployment artifact being delivered as a Hot Fix, the change is recorded in the most recent prod-ready manifest in the release-pipeline repository branch specific to that code drop, and a new version of the manifest is delivered to the Operations team.
As an example, assume that component-order was released as com-manh-cp-order:1.2.3-abcdefg-1909030621 as part of say, code drop 2.0.58.4. For a CII that was reported for the component-order, a new Hot Fix version was built with a change. Assume that the revised version is com-manh-cp-order:1.2.4-ghijklm-1009132056. To release this Hot Fix, the prod-ready manifest of the code drop 2.0.58.x is updated to record the new version of component-order, and the version of the manifest is incremented to 2.0.58.5.
Cumulative Nature of Hot Fixes
Hot Fixes for a given Code Drop are cumulative. In other words, when the Code Drop 2.0.58.0 is initially delivered to the Operations team, it contains no hot fixes. With each hot fix (or set of hot fixes if made available at the same time) the manifest’s version number is incremented to 2.0.58.1, 2.0.58.2 and so forth. It is possible that a single Hot Fix increment may have a single change (e.g., component-order only), or may have multiple changes (e.g., component-order and component-payment). However, the last digit of the code drop version will always be incremented by 1. In other words, when 2.0.58.2 is delivered, the Operations teams will also get the Hot Fix delivered as part of 2.0.58.1.
Learn More
Authors
- Pravas Kumar Mahapatra: Sr Manager, Continuous Integration & Release Engineering, Manhattan Active® Platform, R&D.